NanoNets :數據有限時如何應用深度學習?(上)
我覺得人工智能就像是去建造一艘火箭飛船。你需要一個巨大的引擎和許多燃料。如果你有了一個大引擎,但燃料不夠,那么肯定不能把火箭送上軌道;如果你有一個小引擎,但燃料充足,那么說不定根本就無法成功起飛。所以,構建火箭船,你必須要一個巨大的引擎和許多燃料。
深度學習(創建人工智能的關鍵流程之一)也是同樣的道理,火箭引擎就是深度學習模型,而燃料就是海量數據,這樣我們的算法才能應用上。——吳恩達
使用深度學習解決問題的一個常見障礙是訓練模型所需的數據量。對大數據的需求是因為模型中有大量參數需要學習。
以下是幾個例子展示了最近一些模型所需要的參數數量:
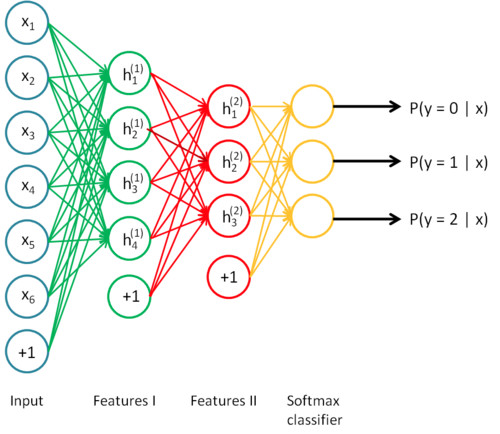
深度學習模型的詳細信息
神經網絡又名深度學習,是可以堆疊起來的層狀結構(想想樂高)
深度學習只不過是大型神經網絡,它們可以被認為是流程圖,數據從一邊進來,推理或知識從另一邊出來。
你可以拆分神經網絡,把它拆開,從任何你喜歡的地方取出推理。你可能沒有得到任何有意義的東西,但你依然可以這么做,例如Google DeepDream。
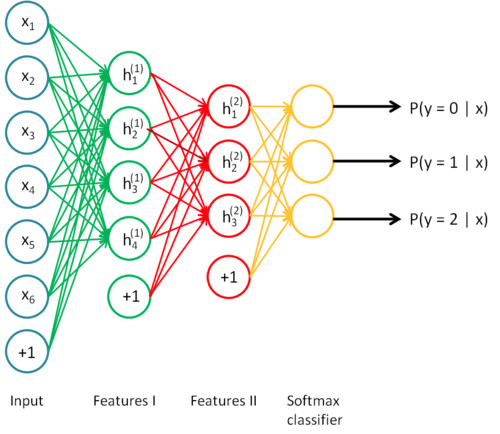
模型大小 ∝ 數據大小 ∝ 問題復雜度
在所需的數據量和模型的大小之間有一個有趣的近乎線性的關系。 基本的推理是,你的模型應該足夠大,以便捕捉數據中的關系(例如圖像中的紋理和形狀,文本中的語法和語音中的音素)以及問題的具體細節(例如類別數量)。模型早期的層捕捉輸入的不同部分之間的高級關系(如邊緣和模式)。后面的層捕捉有助于做出最終決策的信息,通常能夠幫助在想要的輸出間進行區分。因此,如果問題的復雜性很高(如圖像分類),參數數量和所需數據體量也非常大。
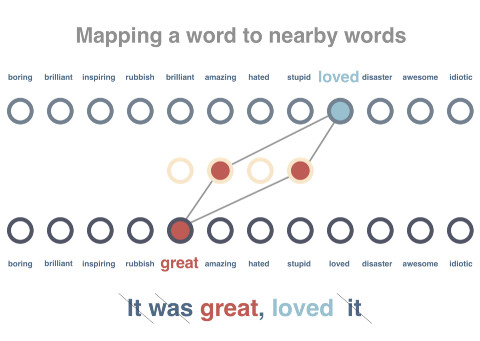
AlexNet在每一步能夠看到什么
遷移學習來解圍!
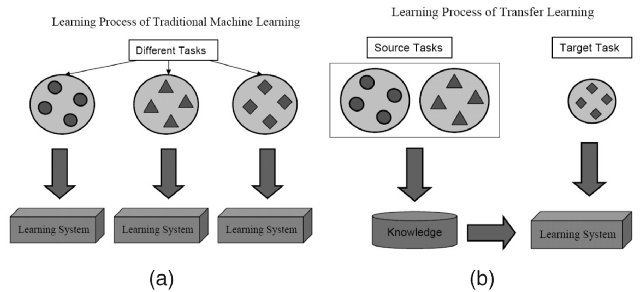
在處理一個您的特定領域的問題時,通常無法找到構建這種大小模型所需的數據量。 然而,訓練一個任務的模型捕獲數據類型中的關系,并且可以很容易地再用于同一個領域中的不同問題。 這種技術被稱為遷移學習。
轉移學習就像沒有人試圖保留但卻保存的***的秘密一樣。 業內人人都知道,但外界沒有人知道。
Google 趨勢機器學習 vs 深度學習 vs 遷移學習
參考Awesome — Most Cited Deep Learning Papers,看看深度學習中的***論文: 引用最多的深度學習論文,超過50%的論文使用某種形式的轉移學習或預訓練。 轉移學習變得越來越適用于資源有限(數據和計算)的人們,但不幸的是,這個想法還沒有得到應有的社會化。 最需要它的人還不知道它。
如果深度學習是圣杯,數據是守門人,轉移學習是關鍵。
通過轉移學習,我們可以采用已經在大型現成數據集上訓練好的預訓練模型(在完全不同的任務上進行訓練,輸入相同但輸出不同)。 然后嘗試查找輸出可重復使用特征的圖層。 我們使用該層的輸出作為輸入特征來訓練需要更少參數的小得多的網絡。 這個較小的網絡已經從預訓練模型了解了數據中的模式,現在只需要了解它與你特定問題的關系。 貓咪檢測模型可以被重利用于梵高作品重現的模型就是這樣訓練的。
使用轉移學習的另一個主要優勢是模型的泛化效果很好。 較大的模型傾向于過度擬合數據(即對數據進行建模而不是對潛在的現象建模),并且在對未見數據進行測試時效果不佳。 由于轉移學習允許模型看到不同類型的數據,因此它更好地學習了世界的基本規則。
把過擬合看做是記憶而不是學習。—— James Faghmous
由于遷移學習導致的數據減少
假設想結束藍黑禮服vs白金禮服的爭論。你開始收集驗證的藍黑禮服和白金禮服的圖像。如果想自己建立一個像上文提到的那樣精確的模型(有140百萬個參數)。為了訓練這個模型,你需要找到120萬張圖像,這是一個不可能完成的任務。 所以可以試試遷移學習。
計算一下使用遷移學習解決該問題所需要的參數數量:
- 參數數量 = [輸入大小 + 1] * [輸出大小 + 1]
- = [2048+1]*[1+1]~ 4098 個參數
我們看到參數數量從1.4×10⁸減少到4×10³,這是5個數量級。 所以我們要收集不到一百個連衣裙的圖像,這樣應該還好。唷!
如果你不耐煩,等不及要找出衣服的實際顏色,向下滾動,看看如何建立自己的禮服模型。
· · ·
轉移學習的分步指南——使用與情感分析相關的實例
在這個實例中我們有72個電影評論
- 62個沒有分配情緒,這些將被用于預先模型
- 8個分配了情緒,它們將被用于訓練模型
- 2個分配了情緒,它們將被用于測試模型
由于我們只有8個有標記的句子(那些有感情相關的句子),我們首先直接訓練模型來預測上下文。 如果我們只用8個句子訓練一個模型,它會有50%的準確率(50%如同用拋硬幣進行決策)。
為了解決這個問題,我們將使用轉移學習,首先在62個句子上訓練一個模型。 然后,我們使用***個模型的一部分,并在其基礎上訓練情感分類器。 使用8個句子進行訓練,并在剩下的2個句子上進行測試時,模型會產生100%的準確率。
步驟一
我們將訓練一個對詞語之間的關系進行建模的網絡。將句子中的一個詞語傳遞進去,并嘗試預測該詞語出現在同一個句子中。在下列的代碼中嵌入的矩陣大小為vocabulary x embedding_size,其中存儲了代表每個詞語的向量(這里的大小為“4”)。
Github地址: https://gist.github.com/sjain07/98266a854d19e01608fa13d1ae9962e3#file-pretraining_model-py
步驟二
我們會對這個圖標進行訓練,讓相同上下文中出現的詞語可以獲得類似的向量表征。我們會對這些句子進行預處理,移除所有停止詞并標記他們。隨后一次傳遞一個詞語, 盡量縮短該詞語向量與周邊詞語之間的距離,并擴大與上下文不包含的隨機詞語之間的距離。
Github地址:https://gist.github.com/sjain07/3e9ef53a462a9fc065511aeecdfc22fd#file-training_the_pretrained_model-py
步驟三
隨后我們會試著預測句子索要表達的情緒。目前已經有10個(8個訓練用,2個測試用)句子帶有正面和負面的標簽。由于上一步得到的模型已經包含從所有詞語中習得的向量,并且這些向量的數值屬性可以代表詞語的上下文,借此可進一步簡化情緒的預測。

此時我們并不直接使用句子,而是將句子的向量設置為所含全部詞語的平均值(這一任務實際上是通過類似LSTM的技術實現的)。句子向量將作為輸入傳遞到網絡中,輸出結果為內容為正面或負面的分數。我們用到了一個隱藏的中間層,并通過帶有標簽的句子對模型進行訓練。如你所見,雖然每次只是用了10個樣本,但這個模型實現了100%的準確度。
Github地址:https://gist.github.com/sjain07/a45ef4ff088e01abbcc89e91b030b380#file-training_the_sentiment_model-py
雖然這只是個示例,但可以發現在遷移學習技術的幫助下,精確度從50%飛速提升至100%。若要查看完整范例和代碼請訪問下列地址:
https://gist.github.com/prats226/9fffe8ba08e378e3d027610921c51a78
遷移學習的一些真實案例
- 圖像識別:圖像增強、風格轉移、對象檢測、皮膚癌檢測。
- 文字識別:Zero Shot翻譯、情緒分類。
遷移學習實現過程中的難點
雖然可以用更少量的數據訓練模型,但該技術的運用有著更高的技能要求。只需要看看上述例子中硬編碼參數的數量,并設想一下要在模型訓練完成前不斷調整這些參數,遷移學習技術使用的難度之大可想而知。
- 遷移學習技術目前面臨的問題包括:
- 找到預訓練所需的大規模數據集
- 決定用來預訓練的模型
- 兩種模型中任何一種無法按照預期工作都將比較難以調試
- 不確定為了訓練模型還需要額外準備多少數據
- 使用預訓練模型時難以決定在哪里停止
- 在預訓練模型的基礎上,確定模型所需層和參數的數量
- 托管并提供組合后的模型
- 當出現更多數據或更好的技術后,對預訓練模型進行更新
數據科學家難覓。找到能發現數據科學家的人其實一樣困難 --Krzysztof Zawadzki
讓遷移學習變得更簡單
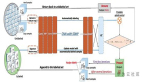
親身經歷過這些問題后,我們開始著手通過構建支持遷移學習技術的云端深度學習服務,并嘗試通過這種簡單易用的服務解決這些問題。該服務中包含一系列預訓練的模型,我們已針對數百萬個參數進行過訓練。你只需要上傳自己的數據(或在網絡上搜索數據),該服務即可針對你的具體任務選擇最適合的模型,在現有預訓練模型的基礎上建立新的NanoNet,將你的數據輸入到NanoNet中進行處理。

NanoNets的遷移學習技術(該架構僅為基本呈現)
構建你的***NanoNet(圖像分類)
1、在這里選擇你要處理的分類。

2、 一鍵點擊開始搜索網絡并構建模型(你也可以上傳自己的圖片)。
3、 解決藍金裙子的爭議(模型就緒后,我們會通過簡單易用的Web界面讓你上傳測試圖片,同時還提供不依賴特定語言的API)。