數據不夠怎么訓練深度學習模型?不妨試試遷移學習
深度學習大牛吳恩達曾經說過:做AI研究就像造宇宙飛船,除了充足的燃料之外,強勁的引擎也是必不可少的。假如燃料不足,則飛船就無法進入預定軌道。而引擎不夠強勁,飛船甚至不能升空。類比于AI,深度學習模型就好像引擎,海量的訓練數據就好像燃料,這兩者對于AI而言同樣缺一不可。
隨著深度學習技術在機器翻譯、策略游戲和自動駕駛等領域的廣泛應用和流行,阻礙該技術進一步推廣的一個普遍性難題也日漸凸顯:訓練模型所必須的海量數據難以獲取。
以下是一些當前比較流行的機器學習模型和其所需的數據量,可以看到,隨著模型復雜度的提高,其參數個數和所需的數據量也是驚人的。

基于這一現狀,本文將從深度學習的層狀結構入手,介紹模型訓練所需的數據量和模型規模的關系,然后通過一個具體實例介紹遷移學習在減少數據量方面起到的重要作用,***推薦一個可以簡化遷移學習實現步驟的云工具:NanoNets。
層狀結構的深度學習模型
深度學習是一個大型的神經網絡,同時也可以被視為一個流程圖,數據從其中的一端輸入,訓練結果從另一端輸出。正因為是層狀的結構,所以你也可以打破神經網絡,將其按層次分開,并以任意一個層次的輸出作為其他系統的輸入重新展開訓練。

數據量、模型規模和問題復雜度
模型需要的訓練數據量和模型規模之間存在一個有趣的線性正相關關系。其中的一個基本原理是,模型的規模應該足夠大,這樣才能充分捕捉數據間不同部分的聯系(例如圖像中的紋理和形狀,文本中的語法和語音中的音素)和待解決問題的細節信息(例如分類的數量)。模型前端的層次通常用來捕獲輸入數據的高級聯系(例如圖像邊緣和主體等)。模型后端的層次通常用來捕獲有助于做出最終決定的信息(通常是用來區分目標輸出的細節信息)。因此,待解決的問題的復雜度越高(如圖像分類等),則參數的個數和所需的訓練數據量也越大。

引入遷移學習
在大多數情況下,面對某一領域的某一特定問題,你都不可能找到足夠充分的訓練數據,這是業內一個普遍存在的事實。但是,得益于一種技術的幫助,從其他數據源訓練得到的模型,經過一定的修改和完善,就可以在類似的領域得到復用,這一點大大緩解了數據源不足引起的問題,而這一關鍵技術就是遷移學習。
根據Github上公布的“引用次數最多的深度學習論文”榜單,深度學習領域中有超過50%的高質量論文都以某種方式使用了遷移學習技術或者預訓練(Pretraining)。遷移學習已經逐漸成為了資源不足(數據或者運算力的不足)的AI項目的***技術。但現實情況是,仍然存在大量的適用于遷移學習技術的AI項目,并不知道遷移學習的存在。如下圖所示,遷移學習的熱度遠不及機器學習和深度學習。

遷移學習的基本思路是利用預訓練模型,即已經通過現成的數據集訓練好的模型(這里預訓練的數據集可以對應完全不同的待解問題,例如具有相同的輸入,不同的輸出)。開發者需要在預訓練模型中找到能夠輸出可復用特征(feature)的層次(layer),然后利用該層次的輸出作為輸入特征來訓練那些需要參數較少的規模更小的神經網絡。
由于預訓練模型此前已經習得了數據的組織模式(patterns),因此這個較小規模的網絡只需要學習數據中針對特定問題的特定聯系就可以了。此前流行的一款名為Prisma的修圖App就是一個很好的例子,它已經預先習得了梵高的作畫風格,并可以將之成功應用于任意一張用戶上傳的圖片中。

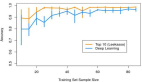
值得一提的是,遷移學習帶來的優點并不局限于減少訓練數據的規模,還可以有效避免過度擬合(overfit),即建模數據超出了待解問題的基本范疇,一旦用訓練數據之外的樣例對系統進行測試,就很可能出現無法預料的錯誤。但由于遷移學習允許模型針對不同類型的數據展開學習,因此其在捕捉待解問題的內在聯系方面的表現也就更優秀。如下圖所示,使用了遷移學習技術的模型總體上性能更優秀。

遷移學習到底能消減多少訓練數據?

這里以此前網上流行的一個連衣裙圖片為例。如圖所示,如果你想通過深度學習判斷這條裙子到底是藍黑條紋還是白金條紋,那就必須收集大量的包含藍黑條紋或者白金條紋的裙子的圖像數據。參考上文提到的問題規模和參數規模之間的對應關系,建立這樣一個精準的圖像識別模型至少需要140M個參數,1.2M張相關的圖像訓練數據,這幾乎是一個不可能完成的任務。
現在引入遷移學習,用如下公式可以得到在遷移學習中這個模型所需的參數個數:
No. of parameters = [Size(inputs) + 1] * [Size(outputs) + 1] = [2048+1]*[1+1]~ 4098 parameters
可以看到,通過遷移學習的引入,針對同一個問題的參數個數從140M減少到了4098,減少了10的5次方個數量級!這樣的對參數和訓練數據的消減程度是驚人的。
一個遷移學習的具體實現樣例
在本例中,我們需要用深度學習技術對電影短評進行文本傾向性分析,例如“It was great,loved it.”表示積極正面的評論,“It was really stupid.”表示消極負面的評論。
假設現在可以得到的數據規模只有72條,其中62條沒有經過預先的傾向性標記,用來預訓練。8條經過了預先的傾向性標記,用來訓練模型。2條也經過了預先的傾向性標記,用來測試模型。
由于我們只有8條經過預先標記的訓練數據,如果直接以這樣的數據量對模型展開訓練,無疑最終的測試準確率將非常低。(因為判斷結果只有正面和負面兩種,因此可以預見最終的測試準確率可能只有50%)
為了解決這個難題,我們引入遷移學習。即首先用62條未經標記的數據對模型展開通用的情感判斷,然后在這一預訓練的基礎上對本例的特定問題展開分析,復用預訓練模型中的部分層次,就可以將最終的測試準確率提升到100%。下面將從3個步驟展開分析。
步驟1
創建預訓練模型來分析詞與詞之間的關系。這里我們通過分析未標記語句中的某一詞匯,嘗試預測出現在同一句子中的其他詞匯。

步驟2
對模型展開訓練,使得出現在類似上下文中的詞匯獲得類似的向量表示。在這一步驟中,62條待處理語句首先會被刪除停用詞,并被標記解釋。之后,針對每個詞匯,系統會嘗試減小其向量表示與相關詞匯的差別,并增加其與不相關詞匯的差別。

步驟3
預測一個句子的文本傾向性。由于在此前的預訓練模型中我們已經得到了針對所有詞匯的向量表示,并且這些向量具有用數字表征的每個詞匯的上下文屬性,這將使得文本的傾向性分析變得更易于實現。

需要注意的是,這里并非直接使用10個已經被預先標記的句子,而是先將句子的向量設置為其所有詞匯的平均值(在實際任務中,我們將使用類似時間遞歸神經網絡LSTM的相關原理)。這樣,經過平均化處理的句子向量將作為輸入數據導入模型,而句子的正面或負面判定將作為結果輸出。需要特別強調的是,這里我們在預訓練模型和10個被預先標記的句子之間加入了一個隱藏層(hidden layer),用來適配文本傾向性分析這一特定場景。正如你所看到的,這里只用10個標記量就實現了100%的預測準確率。
當然,必須指出的是,這里展示的只是一個非常簡單的模型示意,而且測試用例只有2條。但不可否認的一點是,由于遷移學習的引入,確實使得本例中的文本傾向性預測準確率從50%提升到了100%。
遷移學習的實現難點
雖然遷移學習的引入可以顯著減少模型對訓練數據量的要求,但同時也意味著更多的專業調教。從上面的例子就能看出,只是考慮這些海量的必須硬編碼實現的參數數量,以及圍繞這些參數進行的繁雜的調試過程,就足夠讓人望而生畏了。而這也是遷移學習在實際應用中難以進一步推廣的重要阻礙之一。這里我們總結了8條常見的遷移學習的實現難點。
- 獲取一個相對大規模的預訓練數據
- 選擇一個合適的預訓練模型
- 難以排查哪個模型沒有發揮作用
- 不知道需要多少額外數據來訓練模型
- 難以判斷應該在什么情況下停止預訓練
- 決定預訓練模型的層次和參數個數
- 代理和服務于組合模型
- 當獲得更多數據或者更好的算法時,預訓練模型難以更新
NanoNets工具
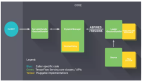
NanoNets是一個簡單方便的基于云端實現的遷移學習工具,其內部包含了一組已經實現好的預訓練模型,每個模型有數百萬個訓練好的參數。用戶可以自己上傳或通過網絡搜索得到數據,NanoNets將自動根據待解問題選擇***的預訓練模型,并根據該模型建立一個NanoNets(納米網絡),并將之適配到用戶的數據。NanoNets和預訓練模型之間的關系結構如下所示。

以上文提到的藍黑條紋還是白金條紋的連衣裙為例,用戶只需要選擇待分類的名稱,然后自己上傳或者網絡搜索訓練數據,之后NanoNets就會自動適配預訓練模型,并生成用于測試的web頁面和用于進一步開發的API接口。如下所示,圖中為系統根據一張連衣裙圖片給出的分析結果。

具體使用方法詳見NanoNets官網。