簡單SQL也很慢?數據庫端到端性能問題的解決思路探討
作為綜合性多業(yè)務的“互聯網+生活服務”平臺, 美團點評 對數據庫的穩(wěn)定運行有較高的要求,小概率的性能抖動(包括慢SQL)都會造成一定的可用性損失。本文將從過去幾年遇到的一些性能問題中,挑選了一個較為棘手的案例,探究端到端數據庫性能問題的解決思路,為DBA同學在解決類似問題時提供一種參考。
問題描述
在一段時間內不斷有開發(fā)同學反饋,線上應用程序獲取數據超時,通過C AT 監(jiān)控系統發(fā)現這些應用的SQL 99line都比較高,這在一定程度上影響了對應業(yè)務的QoS,比如達不到99.99%的業(yè)務可用性(超時被定義為不可用)。這些問題出現在很多業(yè)務場景中,是一個普遍性問題。
通過 C AT 監(jiān)控系統、SQL樣本、慢查詢系統等進一步了解,發(fā)現這類SQL有如下特征:
- 基本上都是以主鍵或唯一鍵為條件的簡單查詢,查詢后的結果集及掃描的行數都比較小;
- 查詢的表的數據總量也很小,最小的表甚至只有幾千行;
- 時間達到了幾百ms,甚至1s;
- 數據庫的slow log里沒有記錄這類SQL。
下圖為CAT相關監(jiān)控數據的樣本,以xxx-service這個service為例:
99line的監(jiān)控數據,有很多SQL的返回時間超過100ms以上。

SQL的絕對數量在2016年9月6日當天為 :3788。

具體到某個SQL,甚至達到了929ms。

FB_Coach的表結構如下:
可看到最多641條記錄,還有聯合索引。

概要分析
要想定位到原因,必須通過排除法找到該SQL到底慢在哪個階段,這樣才能縮小范圍。接下來我們來分析慢SQL的花費時間組成。從下圖可看出,時間主要由3部分組成:

- App Server:發(fā)出SQL請求的時間,接收返回結果的時間
- 網絡:SQL請求包及查詢結果在網絡上花費的時間
- MySQL Server:發(fā)出SQL到查詢結果整個過程花費的時間
我們可以通過抓包工具獲取每個階段花費的時間,從而定位到底慢在哪個階段。
問題解決思路迭代
思路1:確認哪個過程花費的時間最多
方法:分別在APP Server與MySQL Server部署TcpDump抓包工具,得到數據包在4個監(jiān)測點的“到達時間”。為了方便,把如下4個Wireshark分析結果(對TcpDump抓取日志分析)按4個方位標注:
- APP Server 發(fā)出SQL(左上)
- MySQL Server 收到SQL(右上)
- MySQL Server 將查詢發(fā)出(右下)
- APP Server 收到查詢結果(左下)
從數據可以準確的看出時間主要花費在MySQL內部,具體時間為22.569285000-21.962634000=0.6066509999999994(秒),約為606ms。
抓包結果: 慢在MySQL Server端。


思路2: 一條SQL進入MySQL Server到查詢結果輸出分哪些階段?
方法: 將MySQL內部對SQL查詢的流程進行梳理,采用排除法定位問題。要 把經典圖拿出來說事了,以下基礎知識主要來自于《高性能MySQL》,“拿來主義”一下。

首先可以看到,MySQL主要有三個組件:連接/線程處理、MySQL Server層、存儲引擎層。
- 最上層主要進行連接處理、授權認證、安全等;
- 第二層包括查詢解析、分析、優(yōu)化(這三個是解決問題最關心的)、緩存管理、所有內置函數、存儲過程、觸發(fā)器、視圖,似乎扯得有點遠;
- 第三層包含了主要的存儲引擎層,MySQL Server層(第二層)通過“存儲引擎API”向存儲引擎層存儲和提取數據,此層主要是數據存儲相關。
接下來通過一個客戶端請求查詢數據,看看MySQL主要做哪些工作吧。
每個客戶端(可能理解為App負責連接數據庫的組件,我們叫DAL)連接到MySQL服務器進程后會擁有一個線程,這個連接的所有查詢都會在該線程中去執(zhí)行,同時服務器會緩存線程,以減少創(chuàng)建或銷毀線程的開銷和頻繁的上下文切換。
當客戶連接到MySQL服務器時,服務器會分配一個線程,之后進行權限認證,認證通過后,MySQL就開始解析該SQL查詢,并創(chuàng)建內部數據數據結構(解析樹),然后對其各種優(yōu)化,***調用存儲引擎API獲取或存儲需要的數據,***將查詢結果返回給客戶端。
通過以上“背書”,我們大概了解了一個SQL請求的執(zhí)行過程,那到底慢在哪個階段呢?
通過“慢SQL特點”的第4條知道,“數據庫的slow log里沒有記錄這類SQL”,那慢SQL發(fā)生的階段就可以排除了。
MySQL slow log是記錄SQL執(zhí)行過程花費的時間,記錄的時間從“SQL解析”到“存儲引擎”返回數據整個過程,所以可以排除該SQL是慢在第二層和第三層,那么只能是把時間花費在***層了?和線程相關?
結果: 很可能慢在MySQL線程管理上。
思路3: 是創(chuàng)建線程慢?thread cache不夠用,需要頻繁的創(chuàng)建線程?
方法:查看當時數據庫的狀態(tài)值

可以看到,當時空閑的thread很多,監(jiān)控圖也沒有抖動,所以并沒有頻繁地創(chuàng)建線程。 慢SQL產生的時間點,空閑的thread很多,并沒有進行大量的線程創(chuàng)建。
那問題到底出現在和線程相關的哪個環(huán)節(jié)呢? 先把所有和thread相關的參數列出來。
- thread_cache_size
- thread_concurrency
- thread_handling
- thread_pool_high_prio_mode
- thread_pool_high_prio_tickets
- thread_pool_idle_timeout
- thread_pool_max_threads
- thread_pool_oversubscribe
- thread_pool_size
- thread_pool_stall_limit
- thread_stack
- thread_statistics
一眼看過去,大部分是和Thread-Pool相關。同時意識到這些問題是隨著升級到MySQL 5.6產生的,5.6引入了 Thread-Pool 功能。
結果: 看來MySQL5.6的 Thread-Pool 有很大嫌疑了。
思路4: 關閉MySQL 5.6的 Thread-Pool ,確認一下問題
方法: 調整MySQL參數 thread_handling = pool-of-threads---- → thread_handling = One-Connection-Per-Thread。
結論: 關閉 Thread-Pool 功能后,減少78%的慢SQL,側面證明是 Thread-Pool 的問題。
以下是具體的證據,以xxx-service這個service為例: 打開 Thread-Pool 功能(2016年9月6日當天數據)。
99line占比:有好多超過100ms的SQL。

慢SQL數量:3788

關閉 Thread-Pool 功能后(2016年9月13日當天數據)。
99line占比:已經看不到超過100ms的sql了,都在10ms以內。

慢SQL數量:818

那么關閉 Thread-Pool ? 答案很顯然,不能! Thread-Pool 是MySQL5.6重要的功能,能夠保證MySQL數據庫高并發(fā)下的性能穩(wěn)定。
思路5: 調優(yōu) Thread-Pool 相關參數
方法:深入了解 Thread-Pool 的工作原理,查找可能產生慢SQL的參數。
結果: 找到了相關參數(thread_pool_stall_limit),并且效果明顯,慢SQL數量從最初的3788減少到63,幾乎全部消滅掉。
以xxx-service這個service為例,調整后的效果,2016年9月20日當天的數據:
99line占比:

慢SQL數量:63

ok,效果有了,總結一下。
問題分析
1、基本原理
沒有引入Thread-Pool前,MySQL使用的是one thread per connection,一旦connection增加到一定程度,MySQL的性能將急劇下降甚至被壓跨。引入Thread-Pool后將會解決上述問題,同時會減少MySQL內部的線程數(節(jié)省內存)及頻繁創(chuàng)建線程的開銷(節(jié)省CPU)。
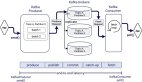
2、Thread-Pool 是如何工作的?
在MySQL內部有一個專用的thread用來監(jiān)聽數據庫連接請求,當一個新的請求過來,如果采用以前的模型(one-thread-per-connection),main listener(這是主線程中的listener,為了避免與thread group 中的listener混淆,我們稱之為“Main listener”)將從thread cache中取出1個thread或創(chuàng)建1個新的thead立即處理該連接請求,由該thread完成該連接的整個生命周期;
而如果采用Thread-Pool模型,這個連接請求將會被隨機放到一個thread group(thread pool由多個thread group 組成)的隊列中,之后該thread group中worker thread從隊列中取出并建立連接,一旦連接建立,該連接對應的socket句柄將與該thread group中的listener關聯起來,之后該連接將在該thread group中完成它的生命周期。
接下來我們來說說Thread Group 。Thread Group是Thread-Pool的核心組件,所有的操作都是發(fā)生在thread group。Thread-Pool由多個(數量由參數thread_pool_size來決定,默認等于cpu個數)thrad group組成。一個連接請求被隨機地綁定到一個thread group,每個thread group獨立工作,并且占用一個核的CPU。所以thread group都會***限度地保持一個thread處于ACTIVE狀態(tài),并且***只有一個,因為太多就有可能壓跨數據庫。
Thread Group中的thread一般有4個狀態(tài):
- TP_STATE_LISTENER
- TP_STATE_IDLE
- TP_STATE_ACTIVE
- TP_STATE_WAITING
當一個線程作為listener運行時就處于“TP_STATE_LISTENER”,它通過epoll的方式監(jiān)聽聯接到該Thread Group的所有連接,當一個socket就緒后,listener將決定是否喚醒一個thread或自己處理該socket。此時如果Thread Group的隊列為空,它將自己處理該socket并將狀態(tài)更改為“ACTIVE”,之后該thread 在MySQL Server內部處理“工作”,當該線程遇到鎖或異步IO(比如將數據頁讀入到buffer pool)這些wait時,該thread將通過回調函數的方式告訴thread pool,讓其把自己標記為“WAITING”狀態(tài)。
此時,假設隊列中有了新的socket準備就緒,是立即創(chuàng)建新的線程還是等待剛才的線程執(zhí)行結束呢?
由于Thread-Pool最初設計的目標是保持一定數量的線程處于“ACTIVE”狀態(tài),具體的實現方式就是控制thread group的數量和thread group內部處于"ACTIVE"狀態(tài)的thread的數量。控制thread group內部的ACTIVE狀態(tài)的數量,方法就是***限度地保證處于ACTIVE狀態(tài)的線程個數是1。很顯然,當前thread group中有一個處于WAITING狀態(tài)的thread了,如果再啟用一個新的線程并且處于ACTIVE狀態(tài),剛才的線程由WAITING變?yōu)锳CTIVE狀態(tài)時,此時將會有2個“ACTIVE”狀態(tài)的線程,和最初的目標似乎相背,但顯然也不能讓后續(xù)就緒的socket一直等待下去,那應該怎么處理?
那么此時需要一個權衡了,提供了這樣的一個方法:對正在ACTIVE或WAITING狀態(tài)的線程啟用一個計數器,超過計數器后將該thread標記為stalled,然后thread group創(chuàng)建新的thread或喚醒sleep的thread處理新的sokcet,這樣將是一個很好的權衡。超時時間該參數thread_pool_stall_limit來決定,默認是500ms。
如果一個線程無事可做,它將保持空閑狀態(tài)(TP_STATE_WAITING)一定時間(thread_pool_idle_timeout參數決定,默認是60秒)后“自殺”。
3、和我們遇到的具體問題相關的點
假設上文提到的由“ACTIVE”轉化為“WAITING”狀態(tài)的線程(標記為“線程A”)所執(zhí)行的“SQL"可能是一個標準的慢SQL(命名為SQLA,執(zhí)行時間較長),那么后續(xù)有連接請求分配到了同一個thread group,那么新連接的SQL(命名SQLB)需要等待線程A結束;如果SQLA執(zhí)行時間超過500ms,該thread group創(chuàng)建新的worker線程來處理SQLB。
不管哪種情況,SQLB都會在線程等待上花費很多時間,此時SQLB就是CAT監(jiān)控系統上看到的慢SQL。又因為SQLA不一定都是慢SQL,所以SQLB也不是每次在線程等待上花費較多的時間,這就吻合我們看到的現象“一定比例的慢SQL”。

解決方法
找到問題了,那么解決辦法就簡單了。調整thread_pool_stall_limit=10,這樣就強迫被SQLA更快被標記為stalled,然后創(chuàng)建新的線程來處理SQLB。
帶來的價值
- 以xxx-service為例,減少了98.3%的慢SQL,效果很明顯;
- 該問題的解決讓百個產品線從中受益,業(yè)務可用性超過了99.99%。

首先我們分析了慢SQL的特點及該SQL花費的時間組成,通過“時間花費在哪”這一通用方法,不斷把問題范圍縮小,最終通過排除法將問題鎖定在MySQL內部線程。
對于MySQL內部線程,我們通過對參數“全量掃描”,發(fā)現了與MySQL 5.6新開啟的參數有關,粗略確定了Thread-Pool是導致慢SQL問題的。
之后通過關閉Thread-Pool進一步確認是開啟該功能引起的。之后我們不斷調整參數和閱讀大量相關的資料,最終將問題解決。
通過以上問題的解決,我們可以學到一些端到端的性能問題解決思路:
定位問題
劃分問題的邊界
每個問題總有它的邊界。當我們無法一眼看出來問題的邊界在哪里時,就需要不斷的通過排除法縮小邊界,在特定的邊界內就用特定的專業(yè)知識來定位問題。
搜集關鍵數據得出靠譜結論
比如生產環(huán)境中會有各種數據,包含監(jiān)控數據、臨時部署工具獲取的數據,充分利用這些數據支撐我們的結論。
對問題產生的時間或影響范圍進行上下文聯想
很多問題是隨著一些改變產生的,就像軟件的生命周期一樣,受到各種環(huán)境的變化影響。通過問題產生的上下去尋找問題的原因,可以發(fā)現大部分問題的產生原因。
解決問題
不斷嘗試
有很多人認為,知道問題的原因了,解決問題是比較容易的。其實我認為這個是反的。因為只有清楚知道問題解決了,才能證明問題的原因是對的。在找到問題的原因之前,其實我們已經通過不斷的調整和測試把問題解決了。所以解決問題很關鍵,貌似是廢話。
合理的理論推斷問題產生的原因
問題解決了,原因也找到了,***一步還要“自圓其說”,這就需要深究技術原理,找到切入點,復現問題了。
解決問題的方法有千萬種,這里列舉了其中一種,希望能夠幫助到大家。