













神奇的神經機器翻譯:從發展脈絡到未來前景(附論文資源)
機器翻譯(MT)是借機器之力「自動地將一種自然語言文本(源語言)翻譯成另一種自然語言文本(目標語言)」[1]。使用機器做翻譯的思想最早由 Warren Weaver 于 1949 年提出。在很長一段時間里(20 世紀 50 年代到 80 年代),機器翻譯都是通過研究源語言與目標語言的語言學信息來做的,也就是基于詞典和語法生成翻譯,這被稱為基于規則的機器翻譯(RBMT)。隨著統計學的發展,研究者開始將統計模型應用于機器翻譯,這種方法是基于對雙語文本語料庫的分析來生成翻譯結果。這種方法被稱為統計機器翻譯(SMT),它的表現比 RBMT 更好,并且在 1980 年代到 2000 年代之間主宰了這一領域。1997 年,Ramon Neco 和 Mikel Forcada 提出了使用「編碼器-解碼器」結構做機器翻譯的想法 [2]。幾年之后的 2003 年,蒙特利爾大學 Yoshua Bengio 領導的一個研究團隊開發了一個基于神經網絡的語言模型 [3],改善了傳統 SMT 模型的數據稀疏性問題。他們的研究工作為未來神經網絡在機器翻譯上的應用奠定了基礎。
神經機器翻譯的誕生
2013 年,Nal Kalchbrenner 和 Phil Blunsom 提出了一種用于機器翻譯的新型端到端編碼器-解碼器結構 [4]。該模型可以使用卷積神經網絡(CNN)將給定的一段源文本編碼成一個連續的向量,然后再使用循環神經網絡(RNN)作為解碼器將該狀態向量轉換成目標語言。他們的研究成果可以說是神經機器翻譯(NMT)的誕生;神經機器翻譯是一種使用深度學習神經網絡獲取自然語言之間的映射關系的方法。NMT 的非線性映射不同于線性的 SMT 模型,而且是使用了連接編碼器和解碼器的狀態向量來描述語義的等價關系。此外,RNN 應該還能得到無限長句子背后的信息,從而解決所謂的「長距離重新排序(long distance reordering)」問題 [29]。但是,「梯度爆炸/消失」問題 [28] 讓 RNN 實際上難以處理長距依存(long distance dependency);因此,NMT 模型一開始的表現并不好。
用于長距問題的記憶
一年后的 2014 年,Sutskever et al. 和 Cho et al. 開發了一種名叫序列到序列(seq2seq)學習的方法,可以將 RNN 既用于編碼器也用于解碼器 [5][6],并且還為 NMT 引入了長短時記憶(LSTM,是一種 RNN)。在門機制(gate mechanism)的幫助下(允許在 LSTM 中刪除和更新明確的記憶),「梯度爆炸/消失」問題得到了控制,從而讓模型可以遠遠更好地獲取句子中的「長距依存」。
LSTM 的引入解決了「長距離重新排序」問題,同時將 NMT 的主要難題變成了「固定長度向量(fixed-length vector)」問題:如圖 1 所示,不管源句子的長度幾何,這個神經網絡都需要將其壓縮成一個固定長度的向量,這會在解碼過程中帶來更大的復雜性和不確定性,尤其是當源句子很長時 [6]。
![沒有「注意」的原始神經機器翻譯機制 [5]](https://s4.51cto.com/wyfs02/M02/A2/8F/wKioL1midnCR90LeAAGePdS-xNw506.jpg "沒有「注意」的原始神經機器翻譯機制 [5]")
圖 1:沒有「注意」的原始神經機器翻譯機制 [5]
注意、注意、注意
自 2014 年 Yoshua Bengio 的團隊為 NMT 引入了「注意力(attention)」機制 [7] 之后,「固定長度向量」問題也開始得到解決。注意力機制最早是由 DeepMind 為圖像分類提出的 [23],這讓「神經網絡在執行預測任務時可以更多關注輸入中的相關部分,更少關注不相關的部分」[24]。當解碼器生成一個用于構成目標句子的詞時,源句子中僅有少部分是相關的;因此,可以應用一個基于內容的注意力機制來根據源句子動態地生成一個(加權的)語境向量(context vector)(如圖 2 所示,紫色線的透明度表示權重大小)。然后網絡會根據這個語境向量而不是某個固定長度的向量來預測詞。自那以后,NMT 的表現得到了顯著提升,「注意力編碼器-解碼器網絡」已經成為了 NMT 領域當前最佳的模型。
![谷歌神經機器翻譯(GNMT)[8] 的「注意力編碼器-解碼器網絡」架構的機制](https://s2.51cto.com/wyfs02/M01/A2/8F/wKioL1midoziwXyFAAEyy5Vp8ew727.jpg "谷歌神經機器翻譯(GNMT)[8] 的「注意力編碼器-解碼器網絡」架構的機制")
圖 2:谷歌神經機器翻譯(GNMT)[8] 的「注意力編碼器-解碼器網絡」架構的機制
NMT vs. SMT
盡管 NMT 已經在特定的翻譯實驗上取得了驚人的成就,但研究者還想知道能否在其它任務上也實現這樣的優良表現,以及 NMT 是否確實能取代 SMT。因此,Junczys-Dowmunt et al. 在「United Nations Parallel Corpus」語料庫上進行了實驗,該語料庫包含 15 個語言對和 30 個翻譯方向;而通過 BLEU 分數(一種自動評估機器翻譯的方法,分數越高越好 [33])對實驗結果的測定,NMT 在這所有 30 個翻譯方向上都得到了與 SMT 媲美或更好的表現。此外,在 2015 年的 Workshop on Statistical Machine Translation(WMT)比賽上,來自蒙特利爾大學的這個團隊使用 NMT 贏得了英語-德語翻譯的第一名和德語-英語、捷克語-英語、英語-捷克語翻譯的第三名 [31]。
與 SMT 相比,NMT 可以聯合訓練多個特征,而無需先驗的領域知識,這可以實現 zero-shot 翻譯 [32]。除了更高的 BLEU 分數和更好的句子結構,NMT 還有助于減少 SMT 上常見的形態學錯誤、句法錯誤和詞序錯誤。另一方面,NMT 還有一些需要解決的問題和挑戰:訓練和解碼過程相當慢;對同一個詞的翻譯風格可能不一致;在翻譯結果上還存在「超出詞匯表(out-of-vocabulary)」的問題;「黑箱」的神經網絡機制的可解釋性很差;訓練所用的參數大多數是根據經驗選擇的。

軍備競賽已經開始
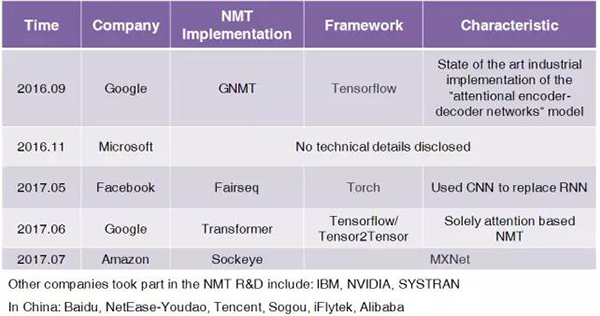
因為 NMT 的特性及其相對于 SMT 的優勢,產業界最近也開始采用 NMT 了:2016 年 9 月,谷歌大腦團隊發布了一篇博客說他們已經在谷歌翻譯產品的漢語-英語語言對上開始使用 NMT 替代基于短語的機器翻譯(PBMT,這是一種 SMT)。他們部署的 NMT 名叫谷歌神經機器翻譯(GNMT),他們也在同一時間發布了一篇論文 [9],對該模型進行了詳細的解釋。之后還不到一年時間(2017 年),Facebook 人工智能研究院(FAIR)就宣布了他們使用 CNN 實現 NMT 的方法,其可以實現與基于 RNN 的 NMT 近似的表現水平 [10][11],但速度卻快 9 倍。作為回應,谷歌在 6 月份發布了一個完全基于注意力(attention)的 NMT 模型;這個模型既沒有使用 CNN,也沒有使用 RNN,而是完全基于注意力機制 [12]。
其它科技巨頭也都各有動作。比如亞馬遜剛在 7 月份發布了他們使用 MXNet 的 NMT 實現 [13];微軟在 2016 年談論過他們對 NMT 的應用,盡管目前還未披露進一步的技術細節 [27]。IBM Watson(機器翻譯領域的老將)、英偉達(人工智能計算的領軍者)和 SYSTRAN(機器翻譯先驅)[35] 全都或多或少地參與到了 NMT 的開發中。在東亞地區,中國這個人工智能領域的新星正在升起,百度、網易有道、騰訊、搜狗、訊飛、阿里巴巴等許多公司甚至已經部署了 NMT。它們全都拼盡全力想在機器翻譯的下一輪演進中取得競爭優勢。
NMT 就是未來嗎?
在高速發展和高度競爭的環境中,NMT 技術正在取得顯著的進展。在最近的 ACL 2017 會議上,機器翻譯類別下接收的 15 篇論文全都與神經機器翻譯有關 [34]。我們可以看到 NMT 還將在許多方面得到不斷完善,其中包括:
- 罕見詞問題 [14][15]
- 單語言數據使用 [16][17]
- 多語言翻譯/多語言 NMT [18]
- 記憶機制 [19]
- 語言融合 [20]
- 覆蓋問題 [21]
- 訓練過程 [22]
- 先驗知識融合 [25]
- 多模態翻譯 [26]
因此,我們有足夠的理由相信 NMT 還將取得更大的突破,還將替代 SMT 逐漸發展成主流的機器翻譯技術,并在不久的將來讓全社會受益。
最后補充
為了幫你了解 NMT 的神奇之處,我們列出了一些 NMT 的開源實現,它們使用了不同的工具:
- Tensorflow [Google-GNMT]: https://github.com/tensorflow/nmt
- Torch [Facebook-fairseq]: https://github.com/facebookresearch/fairseq
- MXNet [Amazon-Sockeye]: https://github.com/awslabs/sockeye
- Theano [NEMATUS]: https://github.com/EdinburghNLP/nematus
- Theano [THUMT]: https://github.com/thumt/THUMT
- Torch [OpenNMT]: https://github.com/opennmt/opennmt
- PyTorch [OpenNMT]: https://github.com/OpenNMT/OpenNMT-py
- Matlab [StanfordNMT]: https://nlp.stanford.edu/projects/nmt/
- DyNet-lamtram [CMU]: https://github.com/neubig/nmt-tips
- EUREKA [MangoNMT]: https://github.com/jiajunzhangnlp/EUREKA-MangoNMT
如果你有興趣進一步了解 NMT,我們鼓勵你閱讀參考文獻中列出的論文:[5][6][7] 是必讀的核心論文,能幫你了解什么是 NMT;[9] 是 NMT 的機制和實現的全面展示。此外,在機器之心正在整理編輯的《人工智能技術報告》中,機器翻譯也是一個重要篇章。
【本文是51CTO專欄機構“機器之心”的原創文章,微信公眾號“機器之心( id: almosthuman2014)”】


















