













SQL優化器原理 - Auto Hash Join
這是MaxCompute有關SQL優化器原理的系列文章之一。我們會陸續推出SQL優化器有關優化規則和框架的其他文章。
本文主要描述MaxCompute優化器實現的Auto Hash Join的功能。
簡介
在MaxCompute中,Join操作符的實現算法之一名為"Hash Join",其實現原理是,把小表的數據全部讀入內存中,并拷貝多份分發到大表數據所在機器,在 map 階段直接掃描大表數據與內存中的小表數據進行匹配。Hash join執行方式效率很高,但是要求小表數據足夠小以便放到內存中,假如小表數據太大,則任務在執行過程中會報OutOfMemory錯誤。
在MapCompute中,可以使用MapJoin關鍵字來實現Hash join,如下所示:
![]()
但是這種通過使用hint的方式還是不夠智能。另外對于query復雜的情況,用戶很可能因為無法確定join的某一路數據量大小而放棄使用mapjoin。在***的MaxCompute SQL 2.0中,基于代價的優化器(Cost Based Optimizer,CBO)包含了一個自動優化join為hash join的優化規則。
實現原理
在CBO中會對所有的operator的cost進行估計,這個cost包含rowcount、cpu、內存等等。有了各個operator的cost,就能估計其對應輸出數據量的大小,公式可以簡單的認為是:data_size = rowcount * averageRowSize。有了dataSize之后,就可以很容易知道這個任務是否適合使用HashJoin,其判定方法就是計算各個parent operator的data size之和是否小于某個閾值。假如估算出的data size在閾值范圍之內,則會產生一個包含HashJoin的計劃。同時對于Join,CBO也會產生一個普通的包含MergeJoin的計劃,***在這兩個計劃中選擇cost最小的作為***計劃。
簡單說來,在CBO中是否選擇HashJoin作為***計劃的步驟有兩個:
- Step1:估算join的輸入數據量大小,判定是否產生一個包含HashJoin的計劃
- Step2:對比HashJoin、MergeJoin相關計劃的cost,選擇cost最小的計劃作為***計劃
舉例,對如下sql進行優化:

上述sql在CBO中會翻譯生成如下operator tree:
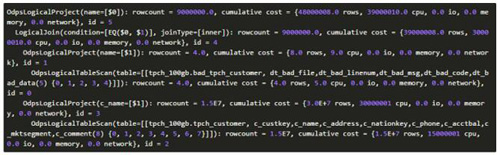
從上可以看到,join的parent operator有兩個:

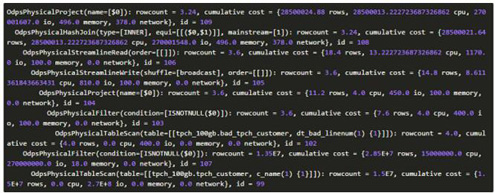
其中id為1的project其輸出記錄數是4行,且其輸出列只有1列(bad_tpch_customer表中有5列),估算其輸出數據量,認為其適合使用HashJoin,因此其產生的計劃中包含兩種:
- 計劃1:HashJoin
- 計劃2:MergeJoin
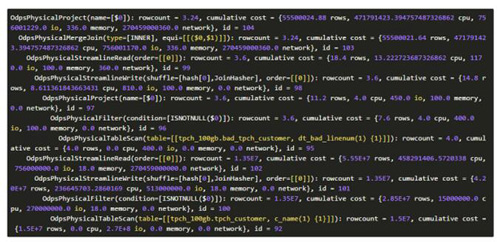
比較上述兩個計劃的cost,明顯計劃1的cost更小,因此選擇包含HashJoin的計劃1作為***計劃。
總結
AutoHashJoin的一個很大的好處是能讓用戶免參與的進行這個優化,同時對于一些復雜的query也更有可能使用HashJoin。但是,因為CBO無法***估計數據量,會出現誤判從而導致任務OOM的情況。針對這種情況,MaxCompute也進行了相應的調整,對于CBO誤判導致HashJoin OOM的任務會關閉HashJoin rule來重試。
目前CBO中使用HashJoin的閾值比較保守,默認是25MB。主要原因是CBO對于數據量的估計有偏差,無法***估計數據量,而估計不準的原因有兩個:
數據是壓縮存儲的,CBO拿到的statistics不準
CBO的估計算法有偏差
這兩個問題也是CBO致力解決的問題。




















