深度學習在電商商品推薦當中的應用
1.常見算法套路
電商行業(yè)中,對于用戶的商品推薦一直是一個非常熱門而且重要的話題,有很多比較成熟的方法,但是也各有利弊,大致如下:
- 基于商品相似度:比如食物A和食物B,對于它們價格、味道、保質期、品牌等維度,可以計算它們的相似程度,可以想象,我買了包子,很有可能順路帶一盒水餃回家。
優(yōu)點:冷啟動,其實只要你有商品的數據,在業(yè)務初期用戶數據不多的情況下,也可以做推薦
缺點:預處理復雜,任何一件商品,維度可以說至少可以上百,如何選取合適的維度進行計算,設計到工程經驗,這些也是花錢買不到的
典型:亞馬遜早期的推薦系統(tǒng)
- 基于關聯規(guī)則:最常見的就是通過用戶購買的習慣,經典的就是“啤酒尿布”的案例,但是實際運營中這種方法運用的也是最少的,首先要做關聯規(guī)則,數據量一定要充足,否則置信度太低,當數據量上升了,我們有更多優(yōu)秀的方法,可以說沒有什么亮點,業(yè)內的算法有apriori、ftgrow之類的
優(yōu)點:簡單易操作,上手速度快,部署起來也非常方便
缺點:需要有較多的數據,精度效果一般
典型:早期運營商的套餐推薦
- 基于物品的協同推薦:假設物品A被小張、小明、小董買過,物品B被小紅、小麗、小晨買過,物品C被小張、小明、小李買過;直觀的看來,物品A和物品C的購買人群相似度更高(相對于物品B),現在我們可以對小董推薦物品C,小李推薦物品A,這個推薦算法比較成熟,運用的公司也比較多
優(yōu)點:相對精準,結果可解釋性強,副產物可以得出商品熱門排序
缺點:計算復雜,數據存儲瓶頸,冷門物品推薦效果差
典型:早期一號店商品推薦
- 基于用戶的協同推薦:假設用戶A買過可樂、雪碧、火鍋底料,用戶B買過衛(wèi)生紙、衣服、鞋,用戶C買過火鍋、果汁、七喜;直觀上來看,用戶A和用戶C相似度更高(相對于用戶B),現在我們可以對用戶A推薦用戶C買過的其他東西,對用戶C推薦用戶A買過買過的其他東西,優(yōu)缺點與基于物品的協同推薦類似,不重復了。
- 基于模型的推薦:svd+、特征值分解等等,將用戶的購買行為的矩陣拆分成兩組權重矩陣的乘積,一組矩陣代表用戶的行為特征,一組矩陣代表商品的重要性,在用戶推薦過程中,計算該用戶在歷史訓練矩陣下的各商品的可能性進行推薦。
優(yōu)點:精準,對于冷門的商品也有很不錯的推薦效果
缺點:計算量非常大,矩陣拆分的效能及能力瓶頸一直是受約束的
典型:惠普的電腦推薦
- 基于時序的推薦:這個比較特別,在電商運用的少,在Twitter,Facebook,豆瓣運用的比較多,就是只有贊同和反對的情況下,怎么進行評論排序,詳細的可以參見我之前寫的一篇文章:應用:推薦系統(tǒng)-威爾遜區(qū)間法
- 基于深度學習的推薦:現在比較火的CNN(卷積神經網絡)、RNN(循環(huán)神經網絡)、DNN(深度神經網絡)都有運用在推薦上面的例子,但是都還是試驗階段,但是有個基于word2vec的方法已經相對比較成熟,也是我們今天介紹的重點。
優(yōu)點:推薦效果非常精準,所需要的基礎存儲資源較少
缺點:工程運用不成熟,模型訓練調參技巧難
典型:蘇寧易購的會員商品推薦
2.item2vec的工程引入
現在蘇寧的商品有約4億個,商品的類目有10000多組,大的品類也有近40個,如果通過傳統(tǒng)的協同推薦,實時計算的話,服務器成本,計算能力都是非常大的局限,之前已經有過幾篇應用介紹:基于推薦的交叉銷售、基于用戶行為的推薦預估。會員研發(fā)部門因為不是主要推薦的應用部門,所以在選擇上,我們期望的是更加高效高速且相對準確的簡約版模型方式,所以我們這邊基于了word2vec的原始算法,仿造了itemNvec的方式。
首先,讓我們對itemNvec進行理論拆分:
part one:n-gram
目標商品的前后商品對目標商品的影響程度
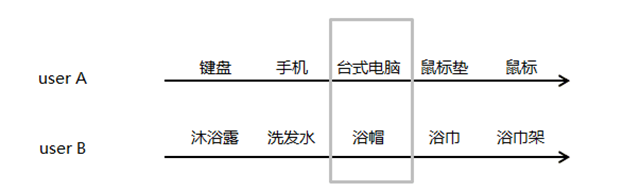
這是兩個用戶userA,userB在易購上面的消費time line,灰色方框內為我們觀察對象,試問一下,如果換一下灰色方框內的userA、userB的購買物品,直觀的可能性有多大?

直觀的體驗告訴我們,這是不可能出現,或者絕對不是常出現的,所以,我們就有一個初始的假設,對于某些用戶在特定的類目下,用戶的消費行為是連續(xù)影響的,換句話說,就是我買了什么東西是依賴我之前買過什么東西。如何通過算法語言解釋上面說的這件事呢?
大家回想一下,naive bayes做垃圾郵件分類的時候是怎么做的?
假設“我公司可以提供發(fā)票、軍火出售、航母維修”這句話是不是垃圾郵件?
- P1(“垃圾郵件”|“我公司可以提供發(fā)票、軍火出售、航母維修”)
- =p(“垃圾郵件”)p(“我公司可以提供發(fā)票、軍火出售、航母維修”/“垃圾郵件”)/p(“我公司可以提供發(fā)票、軍火出售、航母維修”)
- =p(“垃圾郵件”)p(“發(fā)票”,“軍火”,“航母”/“垃圾郵件”)/p(“發(fā)票”,“軍火”,“航母”)
同理
- P2(“正常郵件”|“我公司可以提供發(fā)票、軍火出售、航母維修”)
- =p(“正常郵件”)p(“發(fā)票”,“軍火”,“航母”/“正常郵件”)/p(“發(fā)票”,“軍火”,“航母”)
我們只需要比較p1和p2的大小即可,在條件獨立的情況下可以直接寫成:
- P1(“垃圾郵件”|“我公司可以提供發(fā)票、軍火出售、航母維修”)
- =p(“垃圾郵件”)p(“發(fā)票”/“垃圾郵件”)p(“軍火”/“垃圾郵件”)p(“航母”/“垃圾郵件”)
- P2(“正常郵件”|“我公司可以提供發(fā)票、軍火出售、航母維修”)
- =p(“正常郵件”)p(“發(fā)票”/“正常郵件”)p(“軍火”/“正常郵件”)p(“航母”/“正常郵件”)
但是,我們看到,無論“我公司可以提供發(fā)票、軍火出售、航母維修”詞語的順序怎么變化,不影響它最后的結果判定,但是我們這邊的需求里面前面買的東西對后項的影響會更大。
冰箱=>洗衣機=>衣柜=>電視=>汽水,這樣的下單流程合理
冰箱=>洗衣機=>汽水=>電視=>衣柜,這樣的下單流程相對來講可能性會更低
但是對于naive bayes,它們是一致的。
所以,我們這邊考慮順序,還是上面那個垃圾郵件的問題。
- P1(“垃圾郵件”|“我公司可以提供發(fā)票、軍火出售、航母維修”)
- =p(“垃圾郵件”)p(“發(fā)票”)p(“軍火”/“發(fā)票”)p(“軍火”/“航母”)
- P1(“正常郵件”|“我公司可以提供發(fā)票、軍火出售、航母維修”)
- =p(“正常郵件”)p(“發(fā)票”)p(“軍火”/“發(fā)票”)p(“軍火”/“航母”)
這邊我們每個詞只依賴前一個詞,理論上講依賴1-3個詞通常都是可接受的。以上的考慮順序的bayes就是基于著名的馬爾科夫假設(Markov Assumption):下一個詞的出現僅依賴于它前面的一個或幾個詞下的聯合概率問題,相關詳細的理論數學公式就不給出了,這邊這涉及一個思想。
part two:Huffman Coding
更大的數據存儲形式
我們常用的user到item的映射是通過one hot encoding的形式去實現的,這有一個非常大的弊端就是數據存儲系數且維度災難可能性極大。
回到最初的那組數據:現在蘇寧的商品有約4億個,商品的類目有10000多組,大的品類也有近40個,同時現在會員數目達到3億,要是需要建造一個用戶商品對應的購買關系矩陣做基于用戶的協同推薦的話,我們需要做一個4億X6億的1/0矩陣,這個是幾乎不可能的,Huffman采取了一個近似二叉樹的形式進行存儲:
我們以易購商品購買量為例,講解一下如何以二叉樹的形式替換one hot encoding存儲方式:
假設,818蘇寧大促期間,經過統(tǒng)計,有冰箱=>洗衣機=>烘干機=>電視=>衣柜=>鉆石的用戶下單鏈條(及購買物品順序如上),其中冰箱總售出15萬臺,洗衣機總售出8萬臺,烘干機總售出6萬臺,電視總售出5萬臺,衣柜總售出3萬臺,鉆石總售出1萬顆
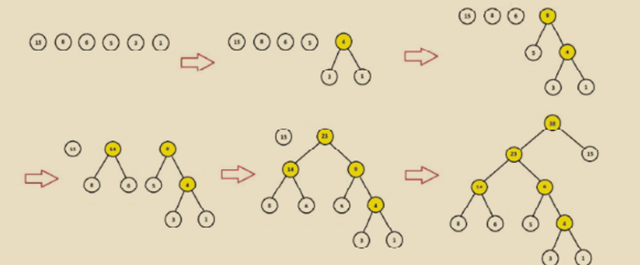
Huffman樹構造過程
1.給定{15,8,6,5,3,1}為二叉樹的節(jié)點,每個樹僅有一個節(jié)點,那就存在6顆單獨的樹
2.選擇節(jié)點權重值最小的兩顆樹進行合并也就是{3}、{1},合并后計算新權重3+1=4
3.將{3},{1}樹從節(jié)點列表刪除,將3+1=4的新組合樹放回原節(jié)點列表
4.重新進行2-3,直到只剩一棵樹為止
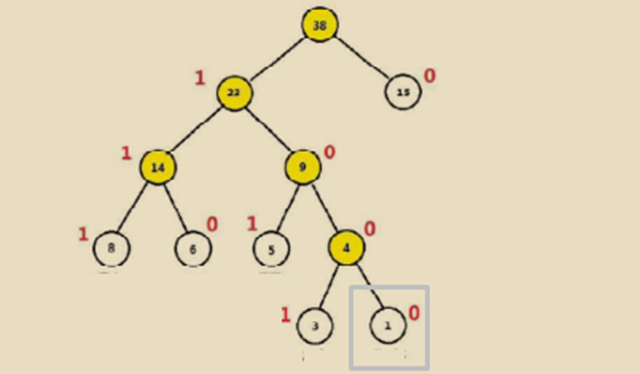
針對每層每次分支過程,我們可以將所有權重大的節(jié)點看做是1,權重小的節(jié)點看做是0,相反亦可。現在,我們比如需要知道鉆石的code,就是1000,也就是灰色方框的位置,洗衣機的code就是111;這樣的存儲利用了0/1的存儲方式,也同時考慮了組合位置的排列長度,節(jié)省了數據的存儲空間。
part three:node probility
最大化當前數據出現可能的概率密度函數
對于鉆石的位置而言,它的Huffman code是1000,那就意味著在每一次二叉選擇的時候,它需要一次被分到1,三次被分到0,而且每次分的過程中,只有1/0可以選擇,這是不是和logistic regression里面的0/1分類相似,所以這邊我們也直接使用了lr里面的交叉熵來作為loss function。
其實對于很多機器學習的算法而言,都是按照先假定一個模型,再構造一個損失函數,通過數據來訓練損失函數求argmin(損失函數)的參數,放回到原模型。
讓我們詳細的看這個鉆石這個例子:

第一步
p(1|No.1層未知參數)=sigmoid(No.1層未知參數)

第二步
- p(0|No.2層未知參數)=sigmoid(No.2層未知參數)
同理,第三第四層:
- p(0|No.3層未知參數)=sigmoid(No.3層未知參數)
- p(0|No.4層未知參數)=sigmoid(No.4層未知參數)
然后求p(1|No.1層未知參數)xp(0|No.2層未知參數)xp(0|No.3層未知參數)xp(0|No.4層未知參數)最大下對應的每層的未知參數即可,求解方式與logistic求解方式近似,未知參數分布偏導,后續(xù)采用梯度下降的方式(極大、批量、牛頓按需使用)
part four:approximate nerual network
商品的相似度
剛才在part three里面有個p(1|No.1層未知參數)這個邏輯,這個NO.1層未知參數里面有一個就是商品向量。
舉個例子:
存在1000萬個用戶有過:“啤酒=>西瓜=>剃須刀=>百事可樂”的商品購買順序
10萬個用戶有過:“啤酒=>蘋果=>剃須刀=>百事可樂”的商品購買順序,如果按照傳統(tǒng)的概率模型比如navie bayes 或者n-gram來看,P(啤酒=>西瓜=>剃須刀=>百事可樂)>>p(啤酒=>蘋果=>剃須刀=>百事可樂),但是實際上這兩者的人群應該是同一波人,他們的屬性特征一定會是一樣的才對。
我們這邊通過了隨機初始化每個商品的特征向量,然后通過part three的概率模型去訓練,最后確定了詞向量的大小。除此之外,還可以通過神經網絡算法去做這樣的事情。

Bengio 等人在 2001 年發(fā)表在 NIPS 上的文章《A Neural Probabilistic Language Model》介紹了詳細的方法。
我們這邊需要知道的就是,對于最小維度商品,我們以商品向量(0.8213,0.8232,0.6613,0.1234,…)的形式替代了0-1點(0,0,0,0,0,1,0,0,0,0…),單個的商品向量無意義,但是成對的商品向量我們就可以比較他們間的余弦相似度,就可以比較類目的相似度,甚至品類的相似度。
3.python代碼實現
1.數據讀取
- # -*- coding:utf-8 -*-
- import pandas as pd
- import numpy as np
- import matplotlib as mt
- from gensim.models import word2vec
- from sklearn.model_selection import train_test_split
- order_data = pd.read_table('C:/Users/17031877/Desktop/SuNing/cross_sell_data_tmp1.txt')
- dealed_data = order_data.drop('member_id', axis=1)
- dealed_data = pd.DataFrame(dealed_data).fillna(value='')
2.簡單的數據合并整理
- # 數據合并
- dealed_data = dealed_data['top10'] + [" "] + dealed_data['top9'] + [" "] + dealed_data['top8'] + [" "] + \
- dealed_data['top7'] + [" "] + dealed_data['top6'] + [" "] + dealed_data['top5'] + [" "] + dealed_data[
- 'top4'] + [" "] + dealed_data['top3'] + [" "] + dealed_data['top2'] + [" "] + dealed_data['top1']
- # 數據分列
- dealed_data = [s.encode('utf-8').split() for s in dealed_data]
- # 數據拆分
- train_data, test_data = train_test_split(dealed_data, test_size=0.3, random_state=42)
3.模型訓練
- # 原始數據訓練
- # sg=1,skipgram;sg=0,SBOW
- # hs=1:hierarchical softmax,huffmantree
- # nagative = 0 非負采樣
- model = word2vec.Word2Vec(train_data, sg=1, min_count=10, window=2, hs=1, negative=0)
接下來就是用model來訓練得到我們的推薦商品,這邊有三個思路,可以根據具體的業(yè)務需求和實際數據量來選擇:
3.1 相似商品映射表
- # 最后一次瀏覽商品最相似的商品組top3
- x = 1000
- result = []
- result = pd.DataFrame(result)
- for i in range(x):
- test_data_split = [s.encode('utf-8').split() for s in test_data[i]]
- k = len(test_data_split)
- last_one = test_data_split[k - 1]
- last_one_recommended = model.most_similar(last_one, topn=3)
- tmp = last_one_recommended[0] + last_one_recommended[1] + last_one_recommended[2]
- last_one_recommended = pd.concat([pd.DataFrame(last_one), pd.DataFrame(np.array(tmp))], axis=0)
- last_one_recommended = last_one_recommended.T
- result = pd.concat([pd.DataFrame(last_one_recommended), result], axis=0)
考慮用戶最后一次操作的關注物品x,干掉那些已經被用戶購買的商品,剩下的商品表示用戶依舊有興趣但是因為沒找到合適的或者便宜的商品,通過商品向量之間的相似度,可以直接計算出,與其高度相似的商品推薦給用戶。
3.2 最大可能購買商品
根據歷史上用戶依舊購買的商品順序,判斷根據當前這個目標用戶近期買的商品,接下來他最有可能買什么?
比如歷史數據告訴我們,購買了手機+電腦的用戶,后一周內最大可能會購買背包,那我們就針對那些近期購買了電腦+手機的用戶去推送電腦包的商品給他,刺激他的潛在規(guī)律需求。
- # 向量庫
- rbind_data = pd.concat(
- [order_data['top1'], order_data['top2'], order_data['top3'], order_data['top4'], order_data['top5'],
- order_data['top6'], order_data['top7'], order_data['top8'], order_data['top9'], order_data['top10']], axis=0)
- x = 50
- start = []
- output = []
- score_final = []
- for i in range(x):
- score = np.array(-100000000000000)
- name = np.array(-100000000000000)
- newscore = np.array(-100000000000000)
- tmp = test_data[i]
- k = len(tmp)
- last_one = tmp[k - 2]
- tmp = tmp[0:(k - 1)]
- for j in range(number):
- tmp1 = tmp[:]
- target = rbind_data_level[j]
- tmp1.append(target)
- test_data_split = [tmp1]
- newscore = model.score(test_data_split)
- if newscore > score:
- score = newscore
- name = tmp1[len(tmp1) - 1]
- else:
- pass
- start.append(last_one)
- output.append(name)
- score_final.append(score)
3.3 聯想記憶推薦
在3.2中,我們根據了這個用戶近期購買行為,從歷史已購用戶的購買行為數據發(fā)現規(guī)律,提供推薦的商品。還有一個近似的邏輯,就是通過目標用戶最近一次的購買商品進行推測,參考的是歷史用戶的單次購買附近的數據,詳細如下:
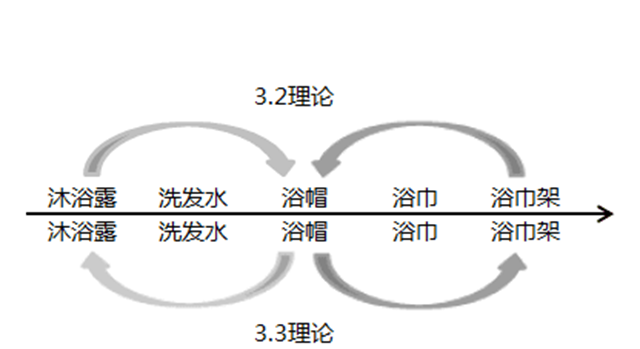
這個實現也非常的簡單,這邊代碼我自己也沒有寫,就不貼了,采用的還是word2vec里面的predict_output_word(context_words_list, topn=10),Report the probability distribution of the center word given the context words as input to the trained model
其實,這邊詳細做起來還是比較復雜的,我這邊也是簡單的貼了一些思路,如果有不明白的可以私信我,就這樣,最后,謝謝閱讀。