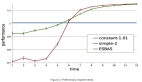
淘寶:三萬字深度剖析強化學習在電商環境下的若干應用與研究
原創
背景
隨著搜索技術的持續發展,我們已經逐漸意識到監督學習算法在搜索場景的局限性:
- 搜索場景中,只有被當前投放策略排到前面的商品,才會獲得曝光機會,從而形成監督學習的正負樣本,而曝光出來的商品,只占總的召回商品中的很小一部分,訓練樣本是高度受當前模型的bias影響的。
- 監督學習的損失函數,和業務關注的指標之間,存在著不一致性
- 用戶的搜索、點擊、購買行為,是一個連續的序列決策過程,監督模型無法對這個過程進行建模,無法優化長期累積獎賞。
與此同時,強化學習的深度學習化,以及以Atari游戲和圍棋游戲為代表的應用在近幾年得到了空前的發展,使得我們開始著眼于這項古老而又時尚的技術,并以此為一條重要的技術發展路線,陸陸續續地在多個業務和場景,進行了強化學習建模,取得了一些初步成果,相關的工作已經在整理發表中。同時我們也深知,目前強化學習的算法理論上限和工業界中大規模噪聲數據之間,還存在著很大的gap,需要有更多的智慧去填補。
基于強化學習的實時搜索排序調控
淘寶的搜索引擎涉及對上億商品的毫秒級處理響應,而淘寶的用戶不僅數量巨大,其行為特點以及對商品的偏好也具有豐富性和多樣性。
因此,要讓搜索引擎對不同特點的用戶作出針對性的排序,并以此帶動搜索引導的成交提升,是一個極具挑戰性的問題。傳統的Learning to Rank(LTR)方法主要是在商品維度進行學習,根據商品的點擊、成交數據構造學習樣本,回歸出排序權重。
盡管Contextual LTR方法可以根據用戶的上下文信息對不同的用戶給出不同的排序結果,但它沒有考慮到用戶搜索商品是一個連續的過程。這一連續過程的不同階段之間不是孤立的,而是有著緊密的聯系。換句話說,用戶最終選擇購買或不夠買商品,不是由某一次排序所決定,而是一連串搜索排序的結果。
本文接下來的內容將對淘寶具體的方案進行詳細介紹。
強化學習為何有用?——延遲獎賞在搜索排序場景中的作用分析
我們用強化學習(Reinforcement Learning,RL)在搜索場景中進行了許多的嘗試,例如:對商品排序策略進行動態調節、控制個性化展示比例、控制價格T變換等。
雖然從順序決策的角度來講,強化學習在這些場景中的應用是合理的,但我們并沒有回答一些根本性的問題,比如:
在搜索場景中采用強化學習和采用多臂老虎機有什么本質區別?
從整體上優化累積收益和分別獨立優化每個決策步驟的即時收益有什么差別?
每當有同行問到這些問題時,我們總是無法給出讓人信服的回答。因為我們還沒思考清楚一個重要的問題,即:在搜索場景的順序決策過程中,任意決策點的決策與后續所能得到的結果之間的關聯性有多大?
從強化學習的角度講,也就是后續結果要以多大的比例進行回傳,以視為對先前決策的延遲激勵。也就是說我們要搞清楚延遲反饋在搜索場景中的作用。
本文將以繼續以搜索場景下調節商品排序策略為例,對這個問題展開探討。
本文余下部分的將組織如下:
- 第二節對搜索排序問題的建模進行回顧。
- 第三節將介紹最近的線上數據分析結果。
- 第四節將對搜索排序問題進行形式化定義。
- 第五節和第六節分別進行理論分析和實驗分析并得出結論。
基于強化學習分層流量調控
今天的淘寶儼然已經成為了一個規模不小的經濟體,因此,社會經濟學里面討論的問題,在我們這幾乎無不例外的出現了。早期的淘寶多數是通過效率優先的方式去優化商品展示的模式,從而產生了給消費者最初的刻板印象:低價爆款,這在當時是有一定的歷史局限性而產生的結果,但肯定不是我們長期希望看到的情形。
因為社會大環境在變化,人們的消費意識也在變化,如果我們不能同步跟上,甚至是超前布局的話,就有可能被競爭對手趕上,錯失良機。因此有了我們近幾年對品牌的經營,以至于現在再搜索“連衣裙”這樣的詞,也很難看到9塊9包郵的商品,而這個在3年之前仍然很常見。
而這里的品牌和客單等因素,是通過一系列的計劃經濟手段來進行干預的,類似于上文福利經濟學第二定理中的稟賦分配,依據的是全局的的觀察和思考,很難而且也不可能通過一個局部的封閉系統(例如搜索的排序優化器)來實現。
因此,越來越多的運營和產品同學,鑒于以上的思考,提出了很多干預的分層,這里的分層指的是商品/商家類型的劃分,可以從不同的維度來劃分,比如,按照對平臺重要性將天貓商家劃分成A、B、C和D類商家;按照品牌影響力將商品劃分為高調性和普通商品;按照價格將商品劃分為高端、中等、低端商品等。
而早期的算法同學對這些可能也不夠重視,一個經典的做法即簡單加權,這通常往往會帶來效率上的損失,因此結果大多也是不了了之。但當我們認真審視這個問題的時候,我們其實可以預料,損失是必然的,因為一個純粹的市場競爭會在當前的供需關系下逐步優化,達到一個局部最優,所以一旦這個局部最優點被一個大的擾動打破,其打破的瞬間必然是有效率損失的,但是其之后是有機會達到比之前的穩定點更優的地方。
虛擬淘寶(聯合研究項目)
在某些場景下中應用強化學習(例如圍棋游戲中的 AlphaGo),進行策略探索的成本是非常低的。而在電商場景下,策略探索的成本會比較昂貴,一次策略評估可能需要一天并且差的策略往往對應著經濟損失,這是在線應用強化學習遇到的一個普遍問題,限制了強化學習在真實場景下的應用。
針對這個問題,我們和強化學習方面的知名專家,南京大學機器學習與數據挖掘研究所的俞揚副教授進行了深度合作,通過逆向建模環境,嘗試構建了一個“淘寶模擬器”,在該模擬器上,策略探索的幾乎沒有成本,并且可以快速進行策略評估。而且在這樣一個模擬器上,不僅可以對各種 RL 算法進行離線嘗試,而且還可以進行各種生態模擬實驗,輔助戰略性決策。
參與人員:阿里巴巴 搜索事業部-AI技術及應用:胡裕靖、詹宇森、潘春香、笪慶、曾安祥
虛擬淘寶合作方 南京大學:侍競成、陳士勇、俞揚(副教授)
這四篇文章,結合淘寶的實踐經驗,用了近三萬字深度剖析了強化學習在電商環境下的若干應用與研究!點擊了解更多細節!