在Airbnb使用機器學習預測房源的價格
位于希臘愛琴海伊莫洛維里的一個 Airbnb 民宿的美好風景
簡介
數據產品一直是 Airbnb 服務的重要組成部分,不過我們很早就意識到開發一款數據產品的成本是很高的。例如,個性化搜索排序可以讓客戶更容易發現中意的房屋,智能定價可以讓房東設定更具競爭力的價格。然而,需要許多數據科學家和工程師付出許多時間和精力才能做出這些產品。
最近,Airbnb 機器學習的基礎架構進行了改進,使得部署新的機器學習模型到生產環境中的成本降低了許多。例如,我們的 ML Infra 團隊構建了一個通用功能庫,這個庫讓用戶可以在他們的模型中應用更多高質量、經過篩選、可復用的特征。數據科學家們也開始將一些自動化機器學習工具納入他們的工作流中,以加快模型選擇的速度以及提高性能標準。此外,ML Infra 還創建了一個新的框架,可以自動將 Jupyter notebook 轉換成 Airflow pipeline 能接受的格式。
在本文中,我將介紹這些工具是如何協同運作來加快建模速度,從而降低開發 LTV 模型(預測 Airbnb 民宿價格)總體成本的。
什么是 LTV?
LTV 全稱 Customer Lifetime Value,意為“客戶終身價值”,是電子商務、市場公司中很流行的一種概念。它定義了在未來一個時間段內用戶預期為公司帶來的收益,通常以美元為單位。
在一些例如 Spotify 或者 Netflix 之類的電子商務公司里,LTV 通常用于制定產品定價(例如訂閱費等)。而在 Airbnb 之類的市場公司里,知曉用戶的 LTV 將有助于我們更有效地分配營銷渠道的預算,更明確地根據關鍵字做在線營銷報價,以及做更好的類目細分。
我們可以根據過去的數據來計算歷史值,當然也可以進一步使用機器學習來預測新登記房屋的 LTV。
LTV 模型的機器學習工作流
數據科學家們通常比較熟悉和機器學習任務相關的東西,例如特征工程、原型制作、模型選擇等。然而,要將一個模型原型投入生產環境中需要的是一系列數據工程技術,他們可能對此不太熟練。
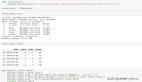
不過幸運的是,我們有相關的機器學習工具,可以將具體的生產部署工作流從機器學習模型的分析建立中分離出來。如果沒有這些神奇的工具,我們就無法輕松地將模型應用于生產環境。下面將通過 4 個主題來分別介紹我們的工作流以及各自用到的工具:
- 特征工程:定義相關特征
- 原型設計與訓練:訓練一個模型原型
- 模型選擇與驗證:選擇模型以及調參
- 生產部署:將選擇好的模型原型投入生產環境使用
特征工程
使用工具:Airbnb 內部特征庫 — Zipline
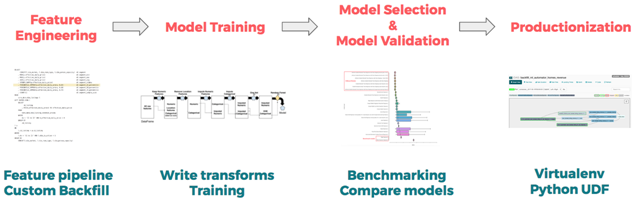
任何監督學習項目的***步都是去找到會影響到結果的相關特征,這一個過程被稱為特征工程。例如在預測 LTV 時,特征可以是某個房源房屋在接下來 180 天內的可使用天數所占百分比,或者也可以是其與同市場其它房屋定價的差異。
在 Airbnb 中,要做特征工程一般得從頭開始寫 Hive 查詢語句來創建特征。但是這個工作相當無聊,而且需要花費很多時間。因為它需要一些特定的領域知識和業務邏輯,也因此這些特征 pipeline 并不容易共享或復用。為了讓這項工作更具可擴展性,我們開發了 Zipline—— 一個訓練特征庫。它可以提供不同粒度級別(例如房主、客戶、房源房屋及市場級別)的特征。
這個內部工具“多源共享”的特性讓數據科學家們可以在過去的項目中找出大量高質量、經過審查的特征。如果沒有找到希望提取的特征,用戶也可以寫一個配置文件來創建他自己需要的特征:
- source: {
- type: hive
- query:"""
- SELECT
- id_listing as listing
- , dim_city as city
- , dim_country as country
- , dim_is_active as is_active
- , CONCAT(ds, ' 23:59:59.999') as ts
- FROM
- core_data.dim_listings
- WHERE
- ds BETWEEN '{{ start_date }}' AND '{{ end_date }}'
- """
- dependencies: [core_data.dim_listings]
- is_snapshot: true
- start_date: 2010-01-01
- }
- features: {
- city: "City in which the listing is located."
- country: "Country in which the listing is located."
- is_active: "If the listing is active as of the date partition."
- }
在構建訓練集時,Zipline 將會找出訓練集所需要的特征,自動的按照 key 將特征組合在一起并填充數據。在構造房源 LTV 模型時,我們使用了一些 Zipline 中已經存在的特征,還自己寫了一些特征。模型總共使用了 150 多個特征,其中包括:
- 位置:國家、市場、社區以及其它地理特征
- 價格:過夜費、清潔費、與相似房源的價格差異
- 可用性:可過夜的總天數,以及房主手動關閉夜間預訂的占比百分數
- 是否可預訂:預訂數量及過去 X 天內在夜間訂房的數量
- 質量:評價得分、評價數量、便利設施
實例數據集
在定義好特征以及輸出變量之后,就可以根據我們的歷史數據來訓練模型了。
原型設計與訓練
使用工具:Python 機器學習庫 — scikit-learn
以前面的訓練集為例,我們在做訓練前先要對數據進行一些預處理:
- 數據插補:我們需要檢查是否有數據缺失,以及它是否為隨機出現的缺失。如果不是隨機現象,我們需要弄清楚其根本原因;如果是隨機缺失,我們需要填充空缺數據。
- 對分類進行編碼:通常來說我們不能在模型里直接使用原始的分類,因為模型并不能去擬合字符串。當分類數量比較少時,我們可以考慮使用 one-hot encoding 進行編碼。如果分類數量比較多,我們就會考慮使用 ordinal encoding, 按照分類的頻率計數進行編碼。
在這一步中,我們還不知道最有效的一組特征是什么,因此編寫可快速迭代的代碼是非常重要的。如 Scikit-Learn、Spark 等開源工具的 pipeline 結構對于原型構建來說是非常方便的工具。Pipeline 可以讓數據科學家們設計藍圖,指定如何轉換特征、訓練哪一個模型。更具體來說,可以看下面我們 LTV 模型的 pipeline:
- transforms = []
- transforms.append(
- ('select_binary', ColumnSelector(features=binary))
- )
- transforms.append(
- ('numeric', ExtendedPipeline([
- ('select', ColumnSelector(features=numeric)),
- ('impute', Imputer(missing_values='NaN', strategy='mean', axis=0)),
- ]))
- )
- for field in categorical:
- transforms.append(
- (field, ExtendedPipeline([
- ('select', ColumnSelector(features=[field])),
- ('encode', OrdinalEncoder(min_support=10))
- ])
- )
- )
- features = FeatureUnion(transforms)
在高層設計時,我們使用 pipeline 來根據特征類型(如二進制特征、分類特征、數值特征等)來指定不同特征中數據的轉換方式。***使用 FeatureUnion 簡單將特征列組合起來,形成最終的訓練集。
使用 pipeline 開發原型的優勢在于,它可以使用 data transforms 來避免繁瑣的數據轉換。總的來說,這些轉換是為了確保數據在訓練和評估時保持一致,以避免將原型部署到生產環境時出現的數據不一致。
另外,pipeline 還可以將數據轉換過程和訓練模型過程分開。雖然上面代碼中沒有,但數據科學家可以在***一步指定一種 estimator(估值器)來訓練模型。通過嘗試使用不同的估值器,數據科學家可以為模型選出一個表現***的估值器,減少模型的樣本誤差。
模型選擇與驗證
使用工具:各種自動機器學習框架
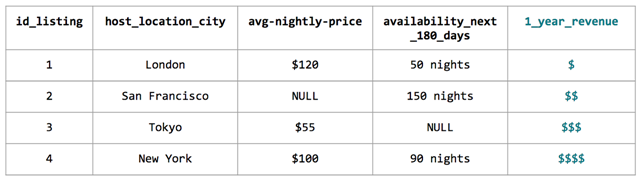
如上一節所述,我們需要確定候選模型中的哪個最適合投入生產。為了做這個決策,我們需要在模型的可解釋性與復雜度中進行權衡。例如,稀疏線性模型的解釋性很好,但它的復雜度太低了,不能很好地運作。一個足夠復雜的樹模型可以擬合各種非線性模式,但是它的解釋性很差。這種情況也被稱為偏差(Bias)和方差(Variance)的權衡。
上圖引用自 James、Witten、Hastie、Tibshirani 所著《R 語言統計學習》
在保險、信用審查等應用中,需要對模型進行解釋。因為對模型來說避免無意排除一些正確客戶是很重要的事。不過在圖像分類等應用中,模型的高性能比可解釋更重要。
由于模型的選擇相當耗時,我們選擇采用各種自動機器學習工具來加速這個步驟。通過探索大量的模型,我們最終會找到表現***的模型。例如,我們發現 XGBoost (XGBoost) 明顯比其他基準模型(比如 mean response 模型、嶺回歸模型、單一決策樹)的表現要好。
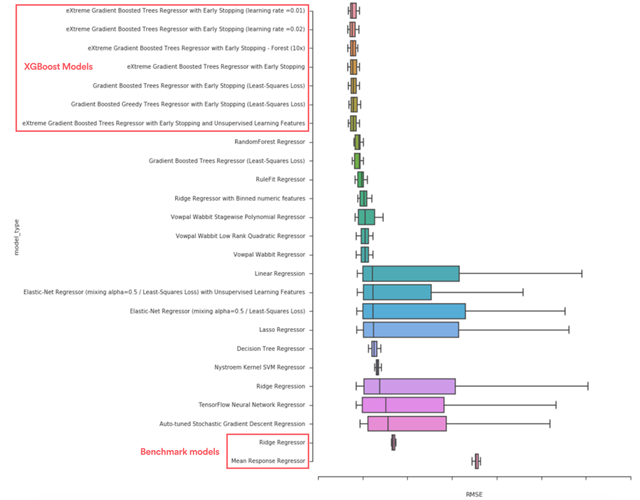
上圖:我們通過比較 RMSE 可以選擇出表現更好的模型
鑒于我們的最初目標是預測房源價格,因此我們很舒服地在最終的生產環境中使用 XGBoost 模型,比起可解釋性它更注重于模型的彈性。
生產部署
使用工具:Airbnb 自己寫的 notebook 轉換框架 — ML Automator
如開始所說,構建生產環境工作流和在筆記本上構建一個原型是完全不同的。例如,我們如何進行定期的重訓練?我們如何有效地評估大量的實例?我們如何建立一個 pipeline 以隨時監視模型性能?
在 Airbnb,我們自己開發了一個名為 ML Automator 的框架,它可以自動將 Jupyter notebook 轉換為 Airflow 機器學習 pipeline。該框架專為熟悉使用 Python 開發原型,但缺乏將模型投入生產環境經驗的數據科學家準備。
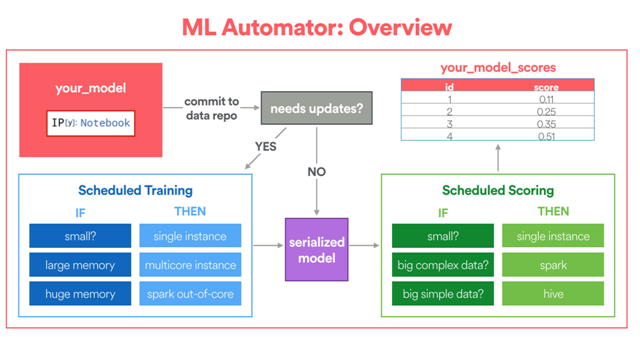
ML Automator 框架概述(照片來源:Aaron Keys)
首先,框架要求用戶在 notebook 中指定模型的配置。該配置將告訴框架如何定位訓練數據表,為訓練分配多少計算資源,以及如何計算模型評價分數。
另外,數據科學家需要自己寫特定的 fit 與 transform 函數。fit 函數指定如何進行訓練,而 transform 函數將被 Python UDF 封裝,進行分布式計算(如果有需要)。
下面的代碼片段展示了我們 LTV 模型中的 fit 與 transform 函數。fit 函數告訴框架需要訓練 XGBoost 模型,同時轉換器將根據我們之前定義的 pipeline 轉換數據。
- def fit(X_train, y_train):
- import multiprocessing
- from ml_helpers.sklearn_extensions import DenseMatrixConverter
- from ml_helpers.data import split_records
- from xgboost import XGBRegressor
- global model
- model = {}
- n_subset = N_EXAMPLES
- X_subset = {k: v[:n_subset] for k, v in X_train.iteritems()}
- model['transformations'] = ExtendedPipeline([
- ('features', features),
- ('densify', DenseMatrixConverter()),
- ]).fit(X_subset)
- # 并行使用轉換器
- Xt = model['transformations'].transform_parallel(X_train)
- # 并行進行模型擬合
- model['regressor'] = XGBRegressor().fit(Xt, y_train)
- def transform(X):
- # return dictionary
- global model
- Xt = model['transformations'].transform(X)
- return {'score': model['regressor'].predict(Xt)}
一旦 notebook 完成,ML Automator 將會把訓練好的模型包裝在 Python UDF 中,并創建一個如下圖所示的 Airflow pipeline。數據序列化、定期重訓練、分布式評價等數據工程任務都將被載入到日常批處理作業中。因此,這個框架顯著降低了數據科學家將模型投入生產的成本,就像有一位數據工程師在與科學家一起工作一樣!
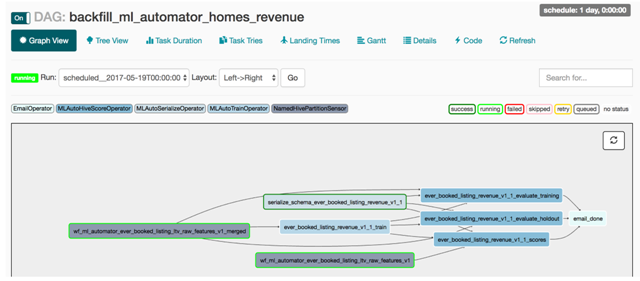
我們 LTV 模型在 Airflow DAG 中的圖形界面,運行于生產環境中
Note:除了模型生產化之外,還有一些其它項目(例如跟蹤模型隨著時間推移的性能、使用彈性計算環境建模等)我們沒有在這篇文章中進行介紹。這些都是正在進行開發的熱門領域。
經驗與展望
過去的幾個月中,我們的數據科學家們與 ML Infra 密切合作,產生了許多很好的模式和想法。我們相信這些工具將會為 Airbnb 開發機器學習模型開辟新的范例。
- 首先,顯著地降低了模型的開發成本:通過組合各種不同的獨立工具的優點(Zipline 用于特征工程、Pipeline 用于模型原型設計、AutoML 用于模型選擇與驗證,以及***的 ML Automator 用于模型生產化),我們大大減短了模型的開發周期。
- 其次,notebook 的設計降低了入門門檻:還不熟悉框架的數據科學家可以立即得到大量的真實用例。在生產環境中,可以確保 notebook 是正確、自解釋、***的。這種設計模式受到了新用戶的好評。
- 因此,團隊將更愿意關注機器學習產品的 idea:在本文撰寫時,我們還有其它幾支團隊在采用類似的方法探索機器學習產品的 idea:為檢查房源隊列進行排序、預測房源是否會增加合伙人、自動標注低質量房源等等。
我們對這個框架和它帶來的新范式的未來感到無比的興奮。通過縮小原型與生產環境間的差距,我們可以讓數據科學家和數據工程師更多去追求端到端的機器學習項目,讓我們的產品做得更好。