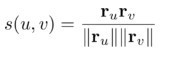教你如何用深度學(xué)習(xí)模型預(yù)測(cè)加密貨幣價(jià)格
編譯:張南星、王夢(mèng)澤、元元、Yawei Xia
如果要評(píng)選2017三大流行金酸梅獎(jiǎng),毫無(wú)疑問(wèn),獲獎(jiǎng)的肯定是指尖陀螺、人工智能以及加密貨幣。加密貨幣是一項(xiàng)顛覆性的技術(shù),它背后的原理引人注目,我十分看好它未來(lái)的發(fā)展。
實(shí)際上,我并沒(méi)有持有任何加密貨幣,但說(shuō)起憑借深度學(xué)習(xí)、機(jī)器學(xué)習(xí)以及人工智能成功預(yù)測(cè)加密貨幣的價(jià)格,我覺(jué)得自己還算是個(gè)老司機(jī)。
一開(kāi)始,我認(rèn)為把深度學(xué)習(xí)和加密貨幣結(jié)合在一起研究是個(gè)非常新穎獨(dú)特的想法,但是當(dāng)我在準(zhǔn)備這篇文章時(shí),我發(fā)現(xiàn)了一篇類(lèi)似的文章。那篇文章只談到比特幣。我在這篇文章中還會(huì)討論到以太幣(它還有一些別名:ether、eth或者lambo-money)。
類(lèi)似文章鏈接:
http://www.jakob-aungiers.com/articles/a/Multidimensional-LSTM-Networks-to-Predict-Bitcoin-Price
我們將使用一個(gè)長(zhǎng)短時(shí)記憶(LSTM)模型,它是深度學(xué)習(xí)中一個(gè)非常適合分析時(shí)間序列數(shù)據(jù)的特定模型(或者任何時(shí)間/空間/結(jié)構(gòu)序列數(shù)據(jù),例如電影、語(yǔ)句等)。
如果你真的想了解其中的基礎(chǔ)理論,那么我推薦你閱讀這三篇文章:《理解LSTM網(wǎng)絡(luò)》、《探究LSTM》、原始白皮書(shū)。出于私心,我主要是想吸引更多的非專(zhuān)業(yè)機(jī)器學(xué)習(xí)愛(ài)好者,所以我會(huì)盡量減少代碼的篇幅。如果你想自己使用這些數(shù)據(jù)或者建立自己的模型,本篇文章同樣提供了Jupyter (Python) 筆記供參考。那么,我們開(kāi)始吧!
- 理解LSTM網(wǎng)絡(luò):http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- 探究LSTM:http://blog.echen.me/2017/05/30/exploring-lstms/
- 原始白皮書(shū):http://www.bioinf.jku.at/publications/older/2604.pdf
- Jupyter (Python) 筆記:https://raw.githubusercontent.com/dashee87/blogScripts/master/Jupyter/2017-11-20-predicting-cryptocurrency-prices-with-deep-learning.ipynb
數(shù)據(jù)
在建立模型之前,我們需要獲取相應(yīng)的數(shù)據(jù)。在Kaggle上有過(guò)去幾年比特幣詳細(xì)到每分鐘的價(jià)格數(shù)據(jù)(以及其他一些相關(guān)的特征,可以在另外一篇博客中看到)。但是如果采用這個(gè)時(shí)間顆粒度,其中的噪音可能會(huì)掩蓋真正的信號(hào),所以我們以天為顆粒度。
另外一篇博客:
http://www.jakob-aungiers.com/articles/a/Multidimensional-LSTM-Networks-to-Predict-Bitcoin-Price
但這樣的話,我們會(huì)面臨數(shù)據(jù)不夠的問(wèn)題(我們的數(shù)據(jù)量只能達(dá)到幾百行,而不是上千或者上百萬(wàn)行)。在深度學(xué)習(xí)中,沒(méi)有模型能夠解決數(shù)據(jù)過(guò)少的問(wèn)題。我也不想依賴(lài)于靜態(tài)文件來(lái)建立模型,因?yàn)檫@會(huì)使未來(lái)注入新數(shù)據(jù)更新模型的流程變得很復(fù)雜。取而代之,我們來(lái)試試從網(wǎng)站和API上爬取數(shù)據(jù)。
因?yàn)槲覀冃枰谝粋€(gè)模型中使用多種加密貨幣,也許從同一個(gè)數(shù)據(jù)源中爬取數(shù)據(jù)是個(gè)不錯(cuò)方法。我們將使用網(wǎng)站coinmarketcap.com。
截至目前,我們只考慮比特幣和以太幣,但是用同樣的渠道獲取最近火爆的Altcoin相關(guān)數(shù)據(jù)也不難。在我們導(dǎo)入數(shù)據(jù)之前,我們必須載入一些python包,它們會(huì)讓分析過(guò)程便捷很多。
- import pandas as pd
- import time
- import seaborn as sns
- import matplotlib.pyplot as plt
- import datetime
- import numpy as np
- # get market info for bitcoin from the start of 2016 to the current day
- bitcoin_market_info = pd.read_html("https://coinmarketcap.com/currencies/bitcoin/historical-data/?start=20130428&end="+time.strftime("%Y%m%d"))[0]
- # convert the date string to the correct date format
- bitcoin_market_infobitcoin_market_info = bitcoin_market_info.assign(Date=pd.to_datetime(bitcoin_market_info['Date']))
- # when Volume is equal to '-' convert it to 0
- bitcoin_market_info.loc[bitcoin_market_info['Volume']=="-",'Volume']=0
- # convert to int
- bitcoin_market_info['Volume'] = bitcoin_market_info['Volume'].astype('int64')
- # look at the first few rows
- bitcoin_market_info.head()
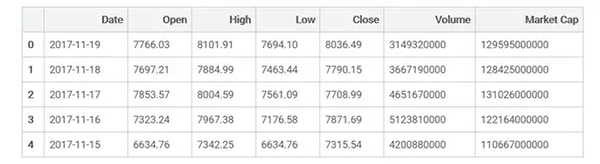
解釋一下剛才發(fā)生了什么,我們加載了一些python包,并導(dǎo)入了在這個(gè)網(wǎng)站(鏈接見(jiàn)下)上看到的表格。經(jīng)過(guò)簡(jiǎn)單的數(shù)據(jù)清理,我們得到了上面的這張表。通過(guò)簡(jiǎn)單地把URL地址(此處代碼忽略)中的“bitcoin”換成“ethereum”,就可以相應(yīng)的獲得以太幣的數(shù)據(jù)。
網(wǎng)站鏈接:https://coinmarketcap.com/currencies/bitcoin/historical-data/
為了驗(yàn)證數(shù)據(jù)的準(zhǔn)確性,我們可以作出兩種貨幣的價(jià)格和成交量時(shí)間線圖。
格和成交量時(shí)間線圖")
圖注:上半部分-收盤(pán)價(jià); 下半部分-成交量
格和成交量時(shí)間線圖")
圖注:上半部分-收盤(pán)價(jià); 下半部分-成交量
訓(xùn)練,測(cè)試以及隨機(jī)游走
我們有了數(shù)據(jù),現(xiàn)在可以開(kāi)始創(chuàng)建模型了。在深度學(xué)習(xí)領(lǐng)域中,數(shù)據(jù)一般分為訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù),用訓(xùn)練數(shù)據(jù)集建立模型,然后用訓(xùn)練樣本之外的測(cè)試數(shù)據(jù)集進(jìn)行評(píng)估。
在時(shí)間序列模型中,一般我們用一段時(shí)間的數(shù)據(jù)訓(xùn)練,然后使用另一段時(shí)間的數(shù)據(jù)測(cè)試。我比較隨意的把時(shí)間節(jié)點(diǎn)設(shè)為2017年6月1日(也就是說(shuō)模型將用6月1日之前的數(shù)據(jù)訓(xùn)練,用其后的數(shù)據(jù)進(jìn)行評(píng)估)。
練集; 藍(lán)色線-測(cè)試集")
圖注:紫色線-訓(xùn)練集; 藍(lán)色線-測(cè)試集
上半部分-比特幣價(jià)格($); 下半部分-以太幣價(jià)格($)
你可以觀察到,訓(xùn)練集的數(shù)據(jù)大多處于貨幣價(jià)格較低的時(shí)候,因此,訓(xùn)練數(shù)據(jù)的分布也許并不能很好地代表測(cè)試數(shù)據(jù)的分布,這將削弱模型推廣到樣本外數(shù)據(jù)的能力(你可以參照這個(gè)網(wǎng)站把數(shù)據(jù)變換成平穩(wěn)的時(shí)間序列)。
網(wǎng)站鏈接:
https://dashee87.github.io/data%2520science/general/A-Road-Incident-Model-Analysis/
但是為什么要讓不如人意的現(xiàn)實(shí)干擾我們的分析呢?在我們帶著深度人工智能機(jī)器模型起飛前,討論一個(gè)更簡(jiǎn)單的模型是很有必要的。最簡(jiǎn)單的模型就是假設(shè)明天的價(jià)格相等于今天的價(jià)格,我們簡(jiǎn)單粗暴地稱(chēng)之為遞延模型。下面我們用數(shù)學(xué)語(yǔ)言來(lái)定義這個(gè)模型:
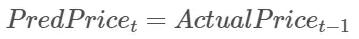
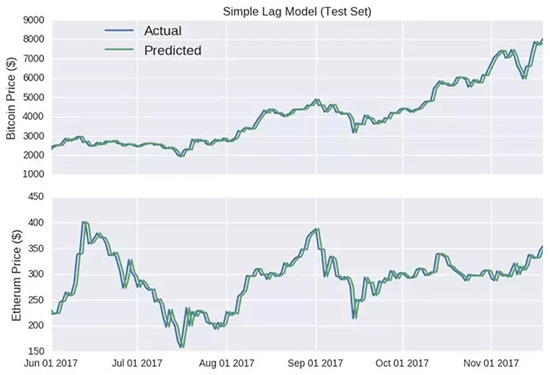
圖:簡(jiǎn)單遞延模型
上半部分-比特幣價(jià)格($); 下半部分-以太幣價(jià)格($)
稍稍拓展一下這個(gè)簡(jiǎn)單的模型,一般人們認(rèn)為股票的價(jià)格是隨機(jī)漫步的,用數(shù)學(xué)模型表示為:
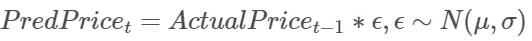
我們將從訓(xùn)練數(shù)據(jù)集中獲取μ和σ的取值,然后在比特幣和以太幣的測(cè)試數(shù)據(jù)集上應(yīng)用隨機(jī)漫步模型。
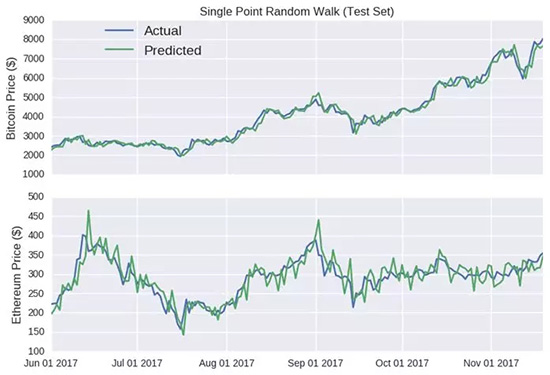
圖:?jiǎn)吸c(diǎn)隨機(jī)游走模型(測(cè)試數(shù)據(jù))
上半部分-比特幣價(jià)格($); 下半部分-以太幣價(jià)格($)
哈哈,看看這些預(yù)測(cè)線,除了一些彎折,它基本追隨了每個(gè)貨幣的實(shí)際收盤(pán)價(jià)格,它甚至預(yù)測(cè)了以太幣在六月中旬及八月下旬的漲勢(shì)(以及隨后的跌勢(shì))。
那些僅僅只預(yù)測(cè)未來(lái)某個(gè)點(diǎn)的模型展現(xiàn)出來(lái)的準(zhǔn)確性都很誤導(dǎo)人,因?yàn)檎`差并不會(huì)延續(xù)到后續(xù)的預(yù)測(cè)中。無(wú)論上一個(gè)值有多大的誤差,由于每個(gè)時(shí)間點(diǎn)的輸入都是真實(shí)值,誤差都會(huì)被重置。
比特幣隨機(jī)漫步模型尤其具有欺騙性,因?yàn)閥軸的范圍很大,讓這個(gè)預(yù)測(cè)曲線看上去非常平滑。
不幸的是,單點(diǎn)預(yù)測(cè)在時(shí)間序列模型的評(píng)估中十分常見(jiàn)(比如文章一、文章二)。更好的做法是用多點(diǎn)預(yù)測(cè)來(lái)評(píng)估它的準(zhǔn)確性,用這種方法,之前的誤差不會(huì)被重置,而是被納入之后的預(yù)測(cè)中。越是預(yù)測(cè)能力差的模型受到的限制也越嚴(yán)重。數(shù)學(xué)模型如下:
- 文章一鏈接:https://medium.com/@binsumi/neural-networks-and-bitcoin-d452bfd7757e
- 文章二鏈接:https://blog.statsbot.co/time-series-prediction-using-recurrent-neural-networks-lstms-807fa6ca7f
我們基于所有的測(cè)試數(shù)據(jù)集得到了隨機(jī)漫步模型,并對(duì)收盤(pán)價(jià)格進(jìn)行了預(yù)測(cè)。
間隨機(jī)模型")
圖:完全區(qū)間隨機(jī)模型
上半部分-比特幣價(jià)格($); 下半部分-以太幣價(jià)格($)
模型預(yù)測(cè)對(duì)隨機(jī)種子的選取極度敏感,我已經(jīng)選擇了一個(gè)預(yù)測(cè)以太幣結(jié)果較好的完全區(qū)間隨機(jī)漫步模型。在相應(yīng)的Jupyter筆記中,你可以通過(guò)交互界面嘗試下面動(dòng)圖中的種子值,看看隨機(jī)漫步模型表現(xiàn)差的情況。
漫步模型/完全區(qū)間隨機(jī)模型對(duì)比")
圖:?jiǎn)吸c(diǎn)漫步模型/完全區(qū)間隨機(jī)模型對(duì)比
縱坐標(biāo)-以太幣價(jià)格($)
需要注意的是,單點(diǎn)隨機(jī)漫步總是看上去非常準(zhǔn)確,即使其背后沒(méi)有任何含義。希望你能夠帶著懷疑的眼光看任何宣稱(chēng)能夠準(zhǔn)確預(yù)測(cè)價(jià)格的文章。但也許我不需要擔(dān)心,加密貨幣的愛(ài)好者們似乎并不會(huì)被虛有其表的廣告語(yǔ)所誘惑。
長(zhǎng)短期記憶(LSTM)
就像我之前所說(shuō)的,如果你對(duì)LSTM的原理感興趣,可以閱讀:《理解LSTM網(wǎng)絡(luò)》、《探究LSTM》、原始白皮書(shū)。(鏈接見(jiàn)上文)
幸運(yùn)的是,我們不需要從頭開(kāi)始建立網(wǎng)絡(luò)(甚至不需要理解它),我們可以運(yùn)用一些包含多種深度學(xué)習(xí)算法標(biāo)準(zhǔn)實(shí)現(xiàn)的函數(shù)包(例如TensorFlow、 Keras,、PyTorch等等)。我將采用Keras,因?yàn)槲野l(fā)現(xiàn)對(duì)于非專(zhuān)業(yè)的愛(ài)好者來(lái)說(shuō),它是最直觀的。如果你對(duì)Keras不熟悉,那么可以看看我之前推出的教程。
- TensorFlow:https://www.tensorflow.org/get_started/get_started
- Keras:https://keras.io/#keras-the-python-deep-learning-library
- PyTorch:http://pytorch.org/
- 之前的教程:https://dashee87.github.io/data%2520science/deep%2520learning/python/another-keras-tutorial-for-neural-network-beginners/
model_data.head()
")
我建好了一個(gè)新數(shù)據(jù)表格model_data,移除了部分列(開(kāi)盤(pán)價(jià),當(dāng)日的價(jià)***價(jià)、當(dāng)日***價(jià)),重新安排了新的列:close_off_high代表當(dāng)天收盤(pán)價(jià)格和***價(jià)格的差值,-1和1的值分別代表收盤(pán)價(jià)格與每日***或者***價(jià)格相等。
volatility列就是***價(jià)和***價(jià)的差值除以開(kāi)盤(pán)價(jià)。你可能還會(huì)注意到model_data數(shù)據(jù)集是按照時(shí)間由古至今排列的。實(shí)際上模型輸入不包括Date,所以我們不再需要這一列了。
我們的LSTM模型將會(huì)使用以往數(shù)據(jù)(比特幣和以太幣均有)來(lái)預(yù)測(cè)某一特定貨幣第二天的收盤(pán)價(jià)格。我們需要決定在模型中使用以往多少天的數(shù)據(jù)。
同樣的,我又隨意地決定選擇使用之前10天的數(shù)據(jù),因?yàn)?0是一個(gè)很好的整數(shù)。我們用連續(xù)10天的數(shù)據(jù)(稱(chēng)之為窗口)建立了多個(gè)小數(shù)據(jù)表格,***個(gè)窗口將由訓(xùn)練數(shù)據(jù)集中的第0-9行組成(Python從0開(kāi)始計(jì)數(shù)),下一個(gè)窗口由1-10行組成,以此類(lèi)推。
選擇較小的窗口規(guī)模意味著我們能在模型中使用更多的窗口,不利之處在于這個(gè)模型沒(méi)有充足的信息以預(yù)測(cè)復(fù)雜長(zhǎng)期行為(如果能夠預(yù)測(cè)的話)。
深度學(xué)習(xí)并不喜歡變化范圍大的輸入值。觀察一下這些列,有些值在-1到1之間,其他的值則達(dá)到了上百萬(wàn)。我們需要進(jìn)行數(shù)據(jù)標(biāo)準(zhǔn)化,保證我們的輸入值的變化范圍是一致的。
一般-1到1的值是最理想的,off_high列和 volatility列的值是符合要求的,但是對(duì)于其他的列,我們需要把輸入值按照窗口的***行值進(jìn)行標(biāo)準(zhǔn)化。
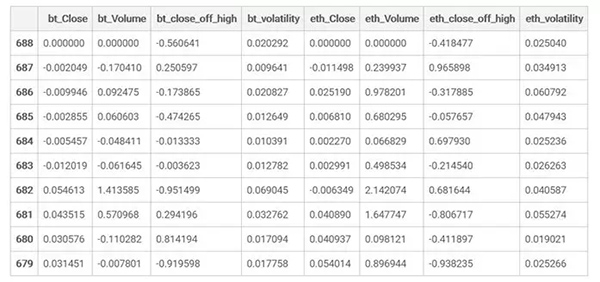
表格展示了LSTM模型的輸入的一部分(實(shí)際上會(huì)有幾百個(gè)相似的表格)。我們對(duì)一些列進(jìn)行了標(biāo)準(zhǔn)化處理,使它們?cè)?**個(gè)時(shí)間點(diǎn)的值為0,以便預(yù)測(cè)相較此時(shí)間點(diǎn)而言?xún)r(jià)格的變動(dòng)。
現(xiàn)在我們準(zhǔn)備構(gòu)建LSTM模型,實(shí)際上使用Keras來(lái)構(gòu)建會(huì)非常簡(jiǎn)單,你只需將幾個(gè)模塊堆疊在一起。
更好的解釋請(qǐng)戳這里:
代碼如下:
- # import the relevant Keras modules
- from keras.models import Sequential
- from keras.layers import Activation, Dense
- from keras.layers import LSTM
- from keras.layers import Dropout
- def build_model(inputs, output_size, neurons, activ_func = "linear",
- dropout =0.25, loss="mae", optimizer="adam"):
- model = Sequential()
- model.add(LSTM(neurons, input_shape=(inputs.shape[1], inputs.shape[2])))
- model.add(Dropout(dropout))
- model.add(Dense(units=output_size))
- model.add(Activation(activ_func))
- model.compile(lossloss=loss, optimizeroptimizer=optimizer)
- return model
不出所料,build_model 函數(shù)建立了一個(gè)空模型,名字為model(即這行代碼model= Sequential),LSTM層已加在模型中,大小與輸入相匹配(n * m的表格,n和m分別代表時(shí)間點(diǎn)/行和列)。
函數(shù)也包含了更通用的神經(jīng)網(wǎng)絡(luò)特征,例如 dropout和activation functions。現(xiàn)在我們只需確定放置到LSTM層中的神經(jīng)元個(gè)數(shù)(我選擇了20個(gè)以便保證合理的運(yùn)行時(shí)間)和創(chuàng)建模型的訓(xùn)練數(shù)據(jù)。
代碼如下:
- # random seed for reproducibility
- np.random.seed(202)
- # initialise model architecture
- eth_model = build_model(LSTM_training_inputs, output_size=1, neurons = 20)
- # model output is next price normalised to 10th previous closing price
- LSTM_training_outputs = (training_set['eth_Close'][window_len:].values/training_set['eth_Close'][:-window_len].values)-1
- # train model on data
- # note: eth_history contains information on the training error per epoch
- eth_history = eth_model.fit(LSTM_training_inputs, LSTM_training_outputs,
- epochs=50, batch_size=1, verbose=2, shuffle=True)
- #eth_preds = np.loadtxt('eth_preds.txt')
結(jié)果:
- Epoch 50/50
- 6s - loss: 0.0625
我們建好了一個(gè)LSTM模型,可以預(yù)測(cè)以太幣明日的收盤(pán)價(jià)。讓我們來(lái)看看模型表現(xiàn)如何。首先檢驗(yàn)?zāi)P驮谟?xùn)練集上的表現(xiàn)情況(2017年6月前的數(shù)據(jù))。代碼下面的數(shù)字是對(duì)訓(xùn)練集進(jìn)行50次訓(xùn)練迭代(或周期)后,模型的平均絕對(duì)誤差(mae)。我們可將模型的輸出結(jié)果視為每日的收盤(pán)價(jià),而不是相對(duì)的變化。
練集:?jiǎn)螘r(shí)間點(diǎn)預(yù)測(cè)")
訓(xùn)練集:?jiǎn)螘r(shí)間點(diǎn)預(yù)測(cè)
藍(lán)色線-實(shí)際價(jià)格;綠色線-預(yù)測(cè)價(jià)格 縱坐標(biāo):以太幣價(jià)格($) 平均絕對(duì)誤差:0.0583
正如我們所期待的,準(zhǔn)確性看起來(lái)很高。訓(xùn)練過(guò)程中,模型可以了解其誤差來(lái)源并相應(yīng)地做出調(diào)整。
實(shí)際上,訓(xùn)練誤差達(dá)到幾乎為零不會(huì)很難,我們只需用上幾百個(gè)神經(jīng)元并且訓(xùn)練數(shù)千個(gè)周期(這就是過(guò)度擬合,實(shí)際上是在預(yù)測(cè)噪音,我在build_model 函數(shù)中加入了Dropout() , 可以為我們相對(duì)小的模型降低過(guò)度擬合的風(fēng)險(xiǎn))。
我們應(yīng)該更關(guān)注模型在測(cè)試集上的表現(xiàn),因?yàn)榭梢钥吹侥P吞幚砣聰?shù)據(jù)的表現(xiàn)。
試集:?jiǎn)螘r(shí)間點(diǎn)預(yù)測(cè)")
測(cè)試集:?jiǎn)螘r(shí)間點(diǎn)預(yù)測(cè)
藍(lán)色線-實(shí)際價(jià)格;綠色線-預(yù)測(cè)價(jià)格 縱坐標(biāo):以太幣價(jià)格($) 平均絕對(duì)誤差:0.0531
撇開(kāi)單點(diǎn)預(yù)測(cè)誤導(dǎo)性的局限,LSTM模型似乎在測(cè)試集中表現(xiàn)良好。但它最明顯的缺陷是以太幣的價(jià)格在暴增后(例如六月中旬和十月)不可避免的下降,模型無(wú)法探測(cè)出來(lái)。
實(shí)際上這個(gè)問(wèn)題一直存在,只是在這些劇烈變化的時(shí)間點(diǎn)更加明顯。預(yù)測(cè)價(jià)格曲線幾乎是實(shí)際價(jià)格曲線向未來(lái)平移一天的結(jié)果(例如七月中旬的下跌)。此外,模型似乎整體高估了以太幣的未來(lái)價(jià)值(我們也是~),預(yù)測(cè)曲線總是高于實(shí)際曲線。
我懷疑這是由于訓(xùn)練集所屬的時(shí)間范圍內(nèi),以太幣的價(jià)格以天文數(shù)字增長(zhǎng),因此模型推斷這種趨勢(shì)仍會(huì)持續(xù)(我們也是~)。我們也建立了一個(gè)相似的LSTM模型用來(lái)預(yù)測(cè)比特幣,測(cè)試集的預(yù)測(cè)圖如下
完整代碼的Jupyter notebook鏈接:
https://github.com/dashee87/blogScripts/blob/master/Jupyter/2017-11-20-predicting-cryptocurrency-prices-with-deep-learning.ipynb
試集:?jiǎn)螘r(shí)間點(diǎn)預(yù)測(cè)")
測(cè)試集:?jiǎn)螘r(shí)間點(diǎn)預(yù)測(cè)
藍(lán)色線-實(shí)際價(jià)格;綠色線-預(yù)測(cè)價(jià)格 縱坐標(biāo):比特幣價(jià)格($) 平均絕對(duì)誤差:0.0392
正如我之前所說(shuō)的,單點(diǎn)預(yù)測(cè)會(huì)有欺騙作用。如果仔細(xì)觀察你會(huì)注意到,預(yù)測(cè)值通常會(huì)反映出先前的值(例如十月)。深度學(xué)習(xí)模型LSTM已經(jīng)部分推導(dǎo)出了p元自回歸模型(autoregression model,AR),未來(lái)的值僅僅是先前p個(gè)值的加權(quán)和。AR模型的數(shù)學(xué)公式如下:
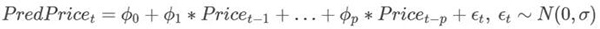
好的方面是,AR模型常運(yùn)用于時(shí)間序列中 ,因此LSTM模型似乎有了合理的用武之地。壞消息是,這是對(duì)LSTM能力的浪費(fèi),我們可以建立更加簡(jiǎn)單的AR模型,花費(fèi)時(shí)間更少,可能會(huì)得到相似的結(jié)果。
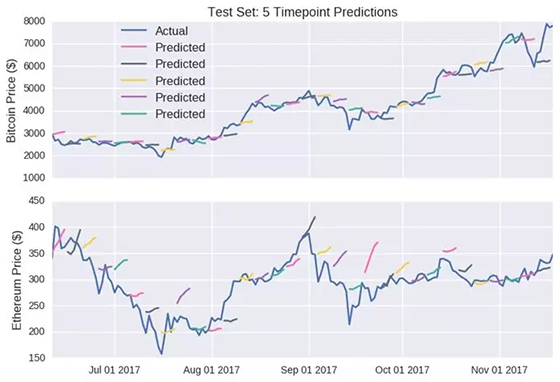
測(cè)試集:5個(gè)時(shí)間點(diǎn)的預(yù)測(cè)
藍(lán)色連續(xù)線:實(shí)際價(jià)格 其他顏色線:預(yù)測(cè)價(jià)格
上半部分:比特幣價(jià)格($);下半部分:以太幣價(jià)格($)
這個(gè)預(yù)測(cè)結(jié)果顯然沒(méi)有單點(diǎn)預(yù)測(cè)的結(jié)果吸引眼球。然而,我很開(kāi)心這個(gè)模型輸出有些微妙的狀況(例如以太幣的第二條線);它并沒(méi)有簡(jiǎn)單的預(yù)測(cè)價(jià)格會(huì)朝著一個(gè)方向統(tǒng)一移動(dòng),這是個(gè)好現(xiàn)象。
回過(guò)頭來(lái)看一下單點(diǎn)預(yù)測(cè),深度機(jī)器人工神經(jīng)模型運(yùn)行的還可以,但隨機(jī)漫步模型也不差。和隨機(jī)漫步模型一樣,LSTM模型對(duì)隨機(jī)種子的選擇也很敏感(模型的權(quán)重最初是隨機(jī)分配的)。
因此,如果我們想去比較這兩個(gè)模型,就需要多次運(yùn)行(大約25次)之后獲取模型誤差的估計(jì)值,測(cè)試集中實(shí)際和預(yù)測(cè)的收盤(pán)價(jià)之間差值的絕對(duì)值記為誤差。
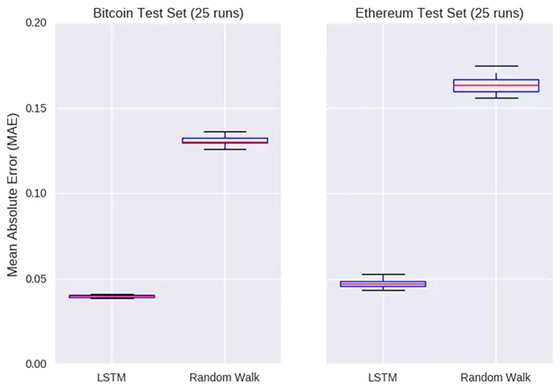
左圖:比特幣測(cè)試集(運(yùn)行25次)縱坐標(biāo):平均絕對(duì)誤差橫坐標(biāo):LSTM模型,隨機(jī)游走模型
右圖:以太幣測(cè)試集(運(yùn)行25次)縱坐標(biāo):平均絕對(duì)誤差橫坐標(biāo):LSTM模型,隨機(jī)游走模型
也許AI還是值得廣而告之的,上圖顯示了對(duì)每個(gè)模型進(jìn)行25次初始化后測(cè)試集的誤差。LSTM模型在比特幣和以太幣上價(jià)格的平均誤差分別是0.04和0.05,這個(gè)結(jié)果完勝隨機(jī)漫步模型。
戰(zhàn)勝隨機(jī)漫步模型是很低的標(biāo)準(zhǔn),將LSTM與更合適的時(shí)間序列模型做比較會(huì)更有趣(比如加權(quán)平均,AR,ARIMA 或Facebook的 Prophet algorithm)。另一方面,我相信改進(jìn)LSTM模型并不難(嘗試加入更多層和/或神經(jīng)元,改變批次的大小,學(xué)習(xí)率等)。
也就是說(shuō),希望你已經(jīng)發(fā)現(xiàn)了我對(duì)應(yīng)用深度學(xué)習(xí)預(yù)測(cè)加密貨幣的價(jià)格變化的疑慮。這是因?yàn)槲覀兒鲆暳?**的框架:人類(lèi)智能。顯然,預(yù)測(cè)加密貨幣的***模型*應(yīng)是:

(譯者注:如果在時(shí)過(guò)境遷之后,加密貨幣的價(jià)格接近月球的高度,那么所有不在OmiseGo區(qū)塊鏈中的加密貨幣會(huì)一直升值)
*本篇文章不涉及財(cái)務(wù)建議,也不應(yīng)該做財(cái)務(wù)建議使用。盡管加密貨幣的投資在長(zhǎng)時(shí)間的范圍看肯定會(huì)增值,但它們也可能會(huì)貶值。
總結(jié)
我們收集了一些加密貨幣數(shù)據(jù),并將其輸入到酷炫的深度智能機(jī)器學(xué)習(xí)LSTM模型中,不幸的是,預(yù)測(cè)值與先前的輸入值并無(wú)太大差別。那么問(wèn)題來(lái)了,如何使模型學(xué)習(xí)更復(fù)雜的行為?
- 改變損失函數(shù):平均絕對(duì)誤差(MAE)使模型中規(guī)中矩,得不到“出格”的結(jié)果。例如,如果采用均方誤差(MSE),LSTM模型會(huì)被迫更加重視檢測(cè)高峰值/低谷值。 許多定制交易的損失函數(shù)也會(huì)使模型朝著沒(méi)那么保守的方向演化。
- 限制保守的AR類(lèi)模型:這會(huì)激勵(lì)深度學(xué)習(xí)算法來(lái)探索更具風(fēng)險(xiǎn)/有趣的模型。不過(guò)說(shuō)起來(lái)容易做起來(lái)難啊。
- 獲取更多且/或更好的數(shù)據(jù):如果過(guò)去的價(jià)格已經(jīng)足以預(yù)測(cè)較為準(zhǔn)確的未來(lái)價(jià)格,那么我們需要引入其他具有相當(dāng)預(yù)測(cè)能力的特征。這樣LSTM模型不會(huì)過(guò)度依賴(lài)過(guò)去的價(jià)格,也許會(huì)解鎖更復(fù)雜的行為,這可能是最可靠同時(shí)也是最難完成的解決方案。
如果以上是積極的一面,那接下來(lái)的負(fù)面消息是,有可能加密貨幣的價(jià)格變化模式根本找不出來(lái);沒(méi)有任何模型(無(wú)論多么深)可以將信號(hào)與噪音分開(kāi)(這與利用深度學(xué)習(xí)預(yù)測(cè)地震類(lèi)似),即使出現(xiàn)了某種模式也會(huì)很快消失 。
想想看2016年和2017年末狂熱的比特幣差別多么大,任何建立在2016年數(shù)據(jù)的模型肯定難以復(fù)刻2017年***的變化。以上討論就是在建議你,不妨節(jié)省些時(shí)間,還是堅(jiān)持研究AR模型吧。
但我相信他們最終會(huì)為深度學(xué)習(xí)找到用武之地,與此同時(shí),你可以通過(guò)下載 Python 代碼建立自己的LSTM模型。
Python 代碼:
https://github.com/dashee87/blogScripts/blob/master/Jupyter/2017-11-20-predicting-cryptocurrency-prices-with-deep-learning.ipynb
原文鏈接:
https://dashee87.github.io/deep%20learning/python/predicting-cryptocurrency-prices-with-deep-learning/
【本文是51CTO專(zhuān)欄機(jī)構(gòu)大數(shù)據(jù)文摘的原創(chuàng)譯文,微信公眾號(hào)“大數(shù)據(jù)文摘( id: BigDataDigest)”】