從Caffe2到TensorFlow,十種框架構建相同神經網絡效率對比
近日,Ilia Karmanov 在 Medium 發表了一篇題為《Neural Net in 10 Frameworks (Lessons Learned)》的文章,其內容源自一個 GitHub 項目,其中作者通過構建同一個神經網絡,對比了當前***的 10 種深度學習框架,其中 Caffe2 和 MXNet 在準確度和訓練時長上處于領先位置。該項目甚至還得到了 FAIR 研究者、各大框架創始人(比如賈揚清)的支持。機器之心對該文進行了編譯。
項目GitHub鏈接:https://github.com/ilkarman/DeepLearningFrameworks
除卻所有的技術元素之外,我發現關于這一項目最有趣的事情是來自開源社區的驚人貢獻。社區發起的請求(pull request)、提出的問題(issue)非常有助于在準確度和訓練時間方面統合所有框架。看到 FAIR 研究者、框架的創始人(比如賈揚清)以及 GitHub 的其他用戶所做出的貢獻,我很震驚。沒有他們,就不會有這個項目的完成。他們不僅給出了代碼建議,還提供了不同框架的整個 notebook。
你可以在這里看到貢獻之前該項目的最初狀態:
https://github.com/ilkarman/DeepLearningFrameworks/tree/0143957489e8adbecaa975f9b541443421db5c4b
問題
搜索 Tensorflow + MNIST 會出現這個看起來很復雜的教程,它規避了更高級的 API(tf.layers or tf.nn),并且似乎沒有從輸入數據中充分分離,因此使用 CIFAR(舉例來說)替代 MNIST 更加讓人舒服。一些教程為了避免冗長加載 MNIST 有一個自定義的封裝器,比如 framework.datasets.mnist,但是對此我有兩個問題:
- 初學者可能并不太清楚如何在數據上重新運行。
- 將其與另一個框架對比也許更加棘手(預處理會有所不同嗎?)
其他教程把 MNIST 作為文本文件(或自定義數據庫)保存到硬盤,接著使用 TextReaderDataLoader 再次加載。這個想法表明,如果用戶有一個大型數據集,它太大以至于無法加載到 RAM,并且需要大量的即時轉換,那么會發生什么。對于初學者來說,這也許是誤導性的,使人膽怯;我經常被問到:「為什么我需要保存它,我明明有一個數組!」
目標
本文的目標是如何使用 10 個***的框架(在一個常見的自定義數據集上)構建相同的神經網絡——一個深度學習框架的羅塞塔石碑,從而允許數據科學家在不同框架之間(通過轉譯而不是從頭學習)發揮其專長。不同框架具有相同模型的一個結果就是框架在訓練時間和默認選項上變得越發透明,我們甚至可以對比特定的元素。
能夠快速地把你的模型轉換為另一個框架意味著你能夠交換 hats。如果另一個框架有一個層需要你從頭編寫,用更有效的方式處理數據資源,或者使其更匹配正運行于其上的平臺(比如安卓)。
對于這些教程,我嘗試不顧違反默認選項,使用***級別的 API,從而更加便捷地對比不同框架。這意味著 notebook 并不是專為速度而寫。
這將證明如果使用更高級的 API,代碼結構將變得相似,并可被大體表征為:
- Load data into RAM; x_train, x_test, y_train, y_test = cifar_for_library(channel_first=?, one_hot=?)
- 把數據加載到 RAM;x_train, x_test, y_train, y_test = cifar_for_library(channel_first=?, one_hot=?)
- 生成 CNN 符號(在***的密集層上通常沒有激活)
- 指定損失(交叉熵通常與 softmax 綁定)、優化器和初始化權重,也許還有 session
- 使用自定義迭代器(所有框架的通用數據源)在訓練集的小批量上進行訓練
- 對測試集的小批量進行預測,也許為層(比如 dropout)指定測試標記
- 評估準確率
注意事項
我們實際上比較了一系列確定的數學操作(盡管初始化比較隨意),因此比較框架的準確率并無意義,相反,我們想匹配框架的準確率,來確保我們在對同樣的模型架構進行對比。
我說比較速度沒有意義的原因是:使用數據裝載器(僅)可以減少幾秒,因為 shuffling 應該異步執行。但是,對于一個合適的項目,你的數據不可能適合 RAM,可能需要大量預處理和操作(數據增強)。這就是數據裝載器的作用。賈揚清認為:
我們在多個網絡中經歷了主要瓶頸 I/O,因此告訴人們如果他想要***的性能,使用異步 I/O 會有很大幫助。
這一實例中僅使用若干個層(conv2d、max_pool2d、dropout、全連接)。對于一個合適的項目,你也許有 3D 卷積、GRU、LSTM 等等。
輕松添加自定義層(或者層的可用性,比如 k ***池化或者分層 softmax),及其運行速度可以促成或毀掉你的框架選擇。能夠用 python 代碼寫一個自定義層并快速執行它對研究項目至關重要。
結果
在 CIFAR-10 上的 VGG-style CNN

IMDB 上的 LSTM(GRU)
")
心得體會(匹配準確率/時間)
下列是我對多個框架測試準確率進行匹配,并根據 GitHub 收集到的問題/PR 得到的一些觀點。
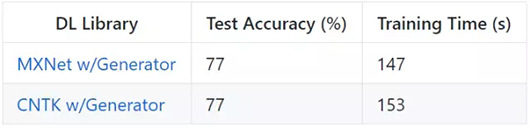
1. 為方便對比,上文中的實例(除了 Keras)使用同等水平的 API 和同樣的生成器函數。我在 MXNet 和 CNTK 的實驗中使用了更高水平的 API,在該 API 上使用框架的訓練生成器函數。該實例中的速度提升幾乎微不足道,原因在于整個數據集作為 NumPy 數組在 RAM 中加載,每個 epoch 所做的唯一的處理是 shuffle。我懷疑該框架的生成器也在異步執行 shuffle 操作。奇怪的是,似乎框架在一個批次水平上進行 shuffle,而不是在觀察層面上,因此測試準確率稍稍降低(至少在 10 epoch 之后)。在框架運行時進行的 IO 活動、預處理和數據增強的場景中,自定義生成器對性能的影響更大。
2. 啟用 CuDNN 的自動調整/窮舉搜索參數(對固定大小的圖像選擇***效的 CNN 算法)會使性能大幅提升。在 Caffe2、PyTorch 和 Theano 中,必須手動啟用。而在 CNTK、MXNet 和 Tensorflow 中,該操作默認進行。我不確定 Chainer 是什么情況。賈揚清提到 cudnnGet(默認)和 cudnnFindi 之間的性能提升比 Titan X GPU 上要小;看起來 K80 + new cudnn 使該問題在這種情況下更加突出。在目標檢測的每一次規模連接中運行 cudnnFind 會帶來嚴重的性能回歸,但是,正因如此,可以在目標檢測時禁用 exhaustive_search。
3. 使用 Keras 時,選擇匹配后端框架的 [NCHW] 排序很重要。CNTK 首先使用通道運行,我錯誤地將 Keras 配置為***使用通道。之后,Keras 在每一批次必須改變順序,這引起性能的嚴重下滑。
4. Tensorflow、PyTorch、Caffe2 和 Theano 要求向池化層提供一個布爾值,來表明我們是否在訓練(這對測試準確率帶來極大影響,72% vs 77%)。
5. Tensorflow 有一點麻煩,它需要兩個改變:啟用 TF_ENABLE_WINOGRAD_NONFUSED 來提升速度;首先改變通道的維度,而不是***再改變(data_format=』channels_first』)。TF 作為后端時,在卷積層上啟用 WINOGRAD 自然也能改善 Keras 的性能。
6. 對于大多數函數,Softmax 通常與 cross_entropy_loss() 綁定在一起,有必要檢查一下***的全連接層是否需要激活,以省下應用兩次激活的時間。
7. Kernel 初始程序在不同的框架中會發生改變(我發現這對準確率有+/- 1% 的影響),我試圖在可能/不是很長的情況下指定統一的 xavier/gloro。
8. SGD 動量實現的動量類型。我必須關閉 unit_gain(只在 CNTK 中默認開啟),以匹配其他框架的實現。
9. Caffe2 在網絡***層需要額外的優化(no_gradient_to_input=1),通過不計算輸入的梯度產生小幅提速。有可能 Tensorflow 和 MXNet 已經默認啟用該項。計算梯度對搜索和 deep-dream 網絡有用。
10. 在***池化之后(而不是之前)應用 ReLU 激活意味著你在降維之后執行計算,并減少幾秒時間。這幫助 MXNet 時間減少了 3 秒。
11. 一些可能有用的進一步檢查:
- 指定 kernel 為 (3) 變成對稱元組 (3, 3) 或 1D 卷積 (3, 1)?
- 步幅(用于***池化)默認為 (1, 1),還是等同于 kernel(Keras 會這樣做)?
- 默認填充通常是 off (0, 0)/valid,但是對檢查它不是 on/』same』很有用
- 卷積層上的默認激活是『None』還是『ReLu』(Lasagne)?
- 偏差初始程序可能會改變(有時不包含任何偏差)。
- 不同框架中的梯度截斷和 inifinty/NaNs 處理可能會不同。
- 一些框架支持稀疏標簽,而不是獨熱標簽(如,Tensorflow 中有 f.nn.sparse_softmax_cross_entropy_with_logits)。
- 數據類型的假設可能會不同:我嘗試使用 float32 和 int32 作為 X、y。但是,舉例來說,torch 需要 y 變成 2 倍(強制轉換成 torch.LongTensor(y).cuda)
- 如果框架 API 的水平稍微低了一點,請確保你在測試過程中,不通過設置 training=False 等來計算梯度。
原文:
https://medium.com/@iliakarmanov/neural-net-in-8-frameworks-lessons-learned-6a5e8e78b481
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】