如何使用TensorFlow構建、訓練和改進循環神經網絡
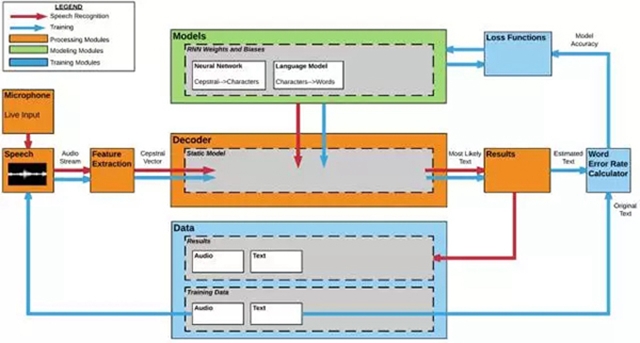
來自 Silicon Valley Data Science 公司的研究人員為我們展示了循環神經網絡(RNN)探索時間序列和開發語音識別模型的能力。目前有很多人工智能應用都依賴于循環深度神經網絡,在谷歌(語音搜索)、百度(DeepSpeech)和亞馬遜的產品中都能看到RNN的身影。
然而,當我們開始著手構建自己的 RNN 模型時,我們發現在使用神經網絡處理語音識別這樣的任務上,幾乎沒有簡單直接的先例可以遵循。一些可以找到的例子功能非常強大,但非常復雜,如 Mozilla 的 DeepSpeech(基于百度的研究,使用 TensorFlow);抑或極其簡單抽象,無法應用于實際數據。
本文將提供一個有關如何使用 RNN 訓練語音識別系統的簡短教程,其中包括代碼片段。本教程的靈感來自于各類開源項目。
本項目 GitHub 地址:https://github.com/silicon-valley-data-science/RNN-Tutorial
首先,在開始閱讀本文以前,如果你對 RNN 還不了解,可以閱讀 Christopher Olah 的 RNN 長短期記憶網絡綜述:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
一、語音識別:聲音和轉錄
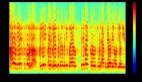
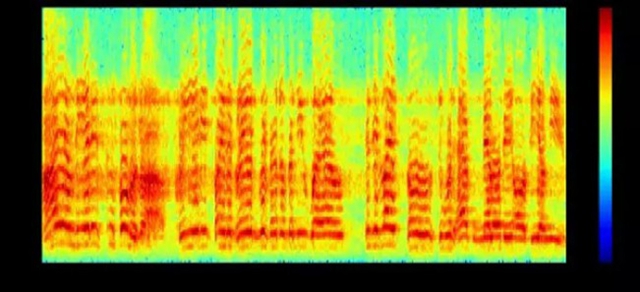
直到 2010 年時,***秀的語音識別模型仍是基于語音學(Phonetics)的方法,它們通常包含拼寫、聲學和語言模型等單獨組件。不論是過去還是現在,語音識別技術都依賴于使用傅里葉變換將聲波分解為頻率和幅度,產生如下所示的頻譜圖:
在訓練語音模型時,使用隱馬爾科夫模型(Hidden Markov Models,HMM)需要語音+文本數據,同時還需要單詞與音素的詞典。HMM 用于順序數據的生成概率模型,通常使用萊文斯坦距離來評估(Levenshtein 距離,是編輯距離的一種。指兩個字串之間,由一個轉成另一個所需的最少編輯操作次數。可以進行的編輯操作包括將一個字符替換成另一個字符,插入一個字符,刪除一個字符)。
這些模型可以被簡化或通過音素關聯數據的訓練變得更準確,但那是一些乏味的手工任務。因為這個原因,音素級別的語音轉錄在大數據集的條件下相比單詞級別的轉錄更難以實現。有關語音識別工具和模型的更多內容可以參考這篇博客:
二、連接時間分類(CTC)損失函數
幸運的是,當使用神經網絡進行語音識別時,通過能進行字級轉錄的連接時間分類(Connectionist Temporal Classification,CTC)目標函數,我們可以丟棄音素的概念。簡單地說,CTC 能夠計算多個序列的概率,而序列是語音樣本中所有可能的字符級轉錄的集合。神經網絡使用目標函數來***化字符序列的概率(即選擇最可能的轉錄),隨后把預測結果與實際進行比較,計算預測結果的誤差,以在訓練中不斷更新網絡權重。
值得注意的是,CTC 損失函數中的字符級錯誤與通常被用于常規語音識別模型的萊文斯坦錯詞距離。對于字符生成 RNN 來說,字符和單詞錯誤距離在表音文字(phonetic language)中是相同的(如世界語、克羅地亞語),這些語言的不同發音對應不同字符。與之相反的是,字符與單詞錯誤距離在其他拼音文字中(如英語)有著顯著不同。
如果你希望了解 CTC 的更多內容和百度對它***的研究,以下是一些鏈接:
- http://suo.im/tkh2e
- http://suo.im/3WuVwV
- https://arxiv.org/abs/1703.00096
為了優化算法,構建傳統/深度語音識別模型,SVDS 的團隊開發了語音識別平臺:
三、數據的重要性
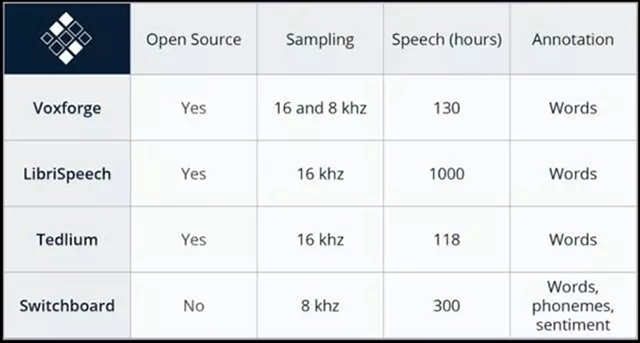
毫無疑問,訓練一個將語音轉錄為文字的系統需要數字語音文件和這些錄音的轉錄文本。因為模型終將被用于解釋新的語音,所以越多的訓練意味著越好的表現。SVDS 的研究人員使用了大量帶有轉錄的英文語音對模型進行訓練;其中的一些數據包含 LibriSpeech(1000 小時)、TED-LIUM(118 小時)和 VoxForge(130 小時)。下圖展示了這些數據集的信息,包括時長,采樣率和注釋。
- LibriSpeech:http://www.openslr.org/12/
- TED-LIUM:http://www.openslr.org/7/
- VoxForge:http://www.voxforge.org/
為了讓模型更易獲取數據,我們將所有數據存儲為同一格式。每條數據由一個.wav 文件和一個.txt 文件組成。例如:Librispeech 的『211-122425-0059』 在 Github 中對應著 211-122425-0059.wav 與 211-122425-0059.txt。這些數據的文件使用數據集對象類被加載到 TensorFlow 圖中,這樣可以讓 TensorFlow 在加載、預處理和載入單批數據時效率更高,節省 CPU 和 GPU 內存負載。數據集對象中數據字段的示例如下所示:
- class DataSet:
- def __init__(self, txt_files, thread_count, batch_size, numcep, numcontext):
- # ...
- def from_directory(self, dirpath, start_idx=0, limit=0, sort=None):
- return txt_filenames(dirpath, start_idxstart_idx=start_idx, limitlimit=limit, sortsort=sort)
- def next_batch(self, batch_size=None):
- idx_list = range(_start_idx, end_idx)
- txt_files = [_txt_files[i] for i in idx_list]
- wav_files = [x.replace('.txt', '.wav') for x in txt_files]
- # Load audio and text into memory
- (audio, text) = get_audio_and_transcript(
- txt_files,
- wav_files,
- _numcep,
- _numcontext)
四、特征表示
為了讓機器識別音頻數據,數據必須先從時域轉換為頻域。有幾種用于創建音頻數據機器學習特征的方法,包括任意頻率的 binning(如 100Hz),或人耳能夠感知的頻率的 binning。這種典型的語音數據轉換需要計算 13 位或 26 位不同倒譜特征的梅爾倒頻譜系數(MFCC)。在轉換之后,數據被存儲為時間(列)和頻率系數(行)的矩陣。
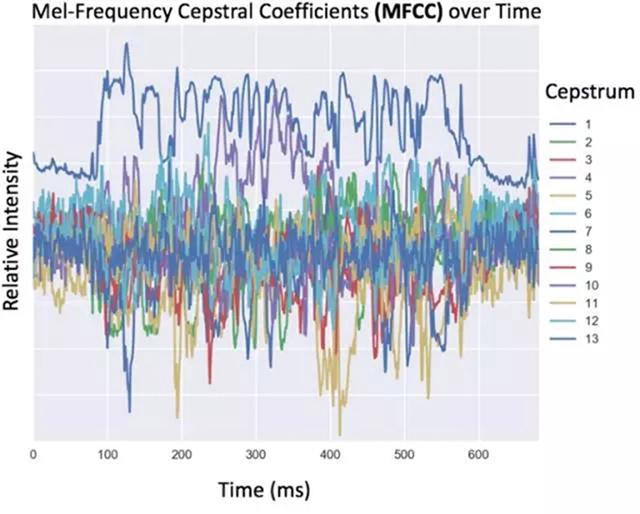
因為自然語言的語音不是獨立的,它們與字母也不是一一對應的關系,我們可以通過訓練神經網絡在聲音數據上的重疊窗口(前后 10 毫秒)來捕捉協同發音的效果(一個音節的發音影響了另一個)。以下代碼展示了如何獲取 MFCC 特征,以及如何創建一個音頻數據的窗口。
- Load wav files
- fs, audio = wav.read(audio_filename)
- # Get mfcc coefficients
- orig_inputs = mfcc(audio, samplerate=fs, numcepnumcep=numcep)
- # For each time slice of the training set, we need to copy the context this makes
- train_inputs = np.array([], np.float32)
- train_inputs.resize((orig_inputs.shape[0], numcep + 2 * numcep * numcontext))
- for time_slice in range(train_inputs.shape[0]):
- # Pick up to numcontext time slices in the past,
- # And complete with empty mfcc features
- need_empty_past = max(0, ((time_slices[0] + numcontext) - time_slice))
- empty_source_past = list(empty_mfcc for empty_slots in range(need_empty_past))
- data_source_past = orig_inputs[max(0, time_slice - numcontext):time_slice]
- assert(len(empty_source_past) + len(data_source_past) == numcontext)
- ...
對于這個 RNN 例子來說,我們在每個窗口使用前后各 9 個時間點——共 19 個時間點。有 26 個倒譜系數,在 25 毫秒的時間里共 494 個數據點。根據數據采樣率,我們建議在 16,000 Hz 上有 26 個倒譜特征,在 8,000 Hz 上有 13 個倒譜特征。以下是一個 8,000 Hz 數據的加載窗口:
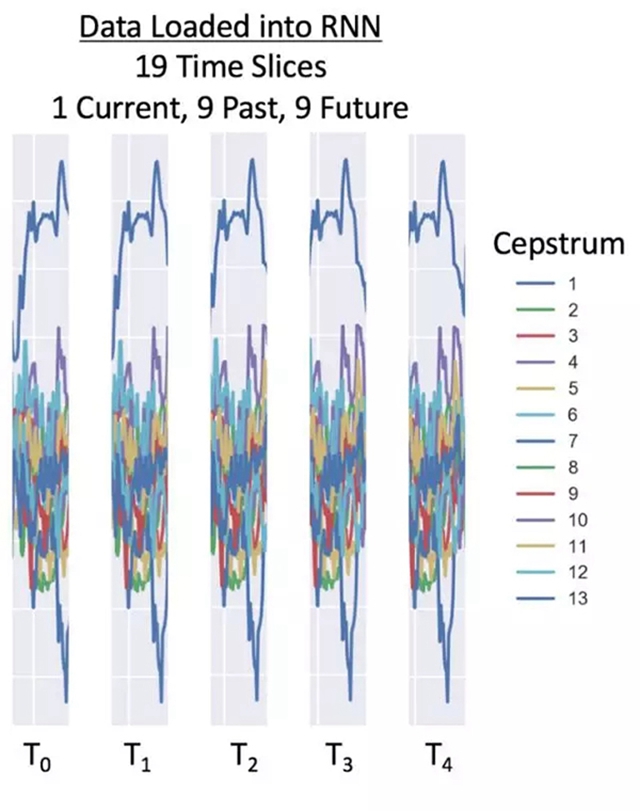
如果你希望了解更多有關轉換數字音頻用于 RNN 語音識別的方法,可以看看 Adam Geitgey 的介紹:http://suo.im/Wkp8B
五、對語音的序列本質建模
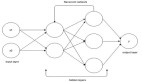
長短期記憶(LSTM)是循環神經網絡(RNN)的一種,它適用于對依賴長期順序的數據進行建模。它對于時間序列數據的建模非常重要,因為這種方法可以在當前時間點保持過去信息的記憶,從而改善輸出結果,所以,這種特性對于語音識別非常有用。如果你想了解在 TensorFlow 中如何實例化 LSTM 單元,以下是受 DeepSpeech 啟發的雙向循環神經網絡(BiRNN)的 LSTM 層示例代碼:
- with tf.name_scope('lstm'):
- # Forward direction cell:
- lstm_fw_cell = tf.contrib.rnn.BasicLSTMCell(n_cell_dim, forget_bias=1.0, state_is_tuple=True)
- # Backward direction cell:
- lstm_bw_cell = tf.contrib.rnn.BasicLSTMCell(n_cell_dim, forget_bias=1.0, state_is_tuple=True)
- # Now we feed `layer_3` into the LSTM BRNN cell and obtain the LSTM BRNN output.
- outputs, output_states = tf.nn.bidirectional_dynamic_rnn(
- cell_fw=lstm_fw_cell,
- cell_bw=lstm_bw_cell,
- # Input is the previous Fully Connected Layer before the LSTM
- inputs=layer_3,
- dtype=tf.float32,
- time_major=True,
- sequence_length=seq_length)
- tf.summary.histogram("activations", outputs)
關于 LSTM 網絡的更多細節,可以參閱 RNN 與 LSTM 單元運行細節的概述:
- http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/
此外,還有一些工作探究了 RNN 以外的其他語音識別方式,如比 RNN 計算效率更高的卷積層:https://arxiv.org/abs/1701.02720
六、訓練和監測網絡
因為示例中的網絡是使用 TensorFlow 訓練的,我們可以使用 TensorBoard 的可視化計算圖監視訓練、驗證和進行性能測試。在 2017 TensorFlow Dev Summit 上 Dandelion Mane 給出了一些有用的幫助:https://www.youtube.com/watch?v=eBbEDRsCmv4
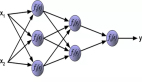
我們利用 tf.name_scope 添加節點和層名稱,并將摘要寫入文件,其結果是自動生成的、可理解的計算圖,正如下面的雙向神經網絡(BiRNN)所示。數據從左下角到右上角在不同的操作之間傳遞。為了清楚起見,不同的節點可以用命名空間進行標記和著色。在這個例子中,藍綠色 fc 框對應于完全連接的層,綠色 b 和 h 框分別對應于偏差和權重。
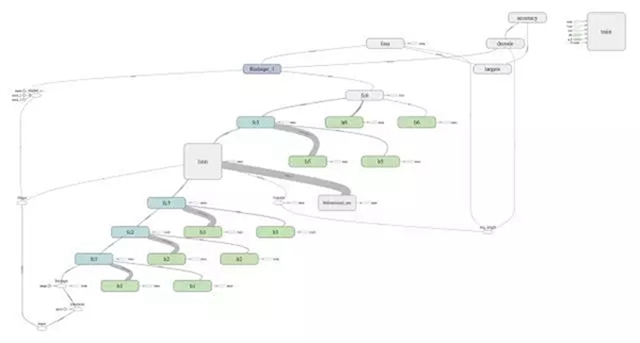
我們利用 TensorFlow 提供的 tf.train.AdamOptimizer 來控制學習速度。AdamOptimizer 通過使用動量(參數的移動平均數)來改善傳統梯度下降,促進超參數動態調整。我們可以通過創建標簽錯誤率的摘要標量來跟蹤丟失和錯誤率:
- Create a placeholder for the summary statistics
- with tf.name_scope("accuracy"):
- # Compute the edit (Levenshtein) distance of the top path
- distance = tf.edit_distance(tf.cast(self.decoded[0], tf.int32), self.targets)
- # Compute the label error rate (accuracy)
- self.ler = tf.reduce_mean(distance, name='label_error_rate')
- self.ler_placeholder = tf.placeholder(dtype=tf.float32, shape=[])
- self.train_ler_op = tf.summary.scalar("train_label_error_rate", self.ler_placeholder)
- self.dev_ler_op = tf.summary.scalar("validation_label_error_rate", self.ler_placeholder)
- self.test_ler_op = tf.summary.scalar("test_label_error_rate", self.ler_placeholder)
七、如何改進 RNN
現在我們構建了一個簡單的 LSTM RNN 網絡,下一個問題是:如何繼續改進它?幸運的是,在開源社區里,很多大公司都開源了自己的***語音識別模型。在 2016 年 9 月,微軟的論文《The Microsoft 2016 Conversational Speech Recognition System》展示了在 NIST 200 Switchboard 數據中單系統殘差網絡錯誤率 6.9% 的新方式。他們在卷積+循環神經網絡上使用了幾種不同的聲學和語言模型。微軟的團隊和其他研究人員在過去 4 年中做出的主要改進包括:
- 在基于字符的 RNN 上使用語言模型
- 使用卷積神經網絡(CNN)從音頻中獲取特征
- 使用多個 RNN 模型組合
值得注意的是,在過去幾十年里傳統語音識別模型獲得的研究成果,在目前的深度學習語音識別模型中仍然扮演著自己的角色。

修改自: A Historical Perspective of Speech Recognition, Xuedong Huang, James Baker, Raj Reddy Communications of the ACM, Vol. 57 No. 1, Pages 94-103, 2014
八、訓練你的***個 RNN 模型
在本教程的 Github 里,作者提供了一些介紹以幫助讀者在 TensorFlow 中使用 RNN 和 CTC 損失函數訓練端到端語音識別系統。大部分事例數據來自 LibriVox。數據被分別存放于以下文件夾中:
- Train: train-clean-100-wav (5 examples)
- Test: test-clean-wav (2 examples)
- Dev: dev-clean-wav (2 examples)
當訓練這些示例數據時,你會很快注意到訓練數據的詞錯率(WER)會產生過擬合,而在測試和開發集中詞錯率則有 85% 左右。詞錯率不是 100% 的原因在于每個字母有 29 種可能性(a-z、逗號、空格和空白),神經網絡很快就能學會:
- 某些字符(e,a,空格,r,s,t)比其他的更常見
- 輔音-元音-輔音是英文的構詞特征
- MFCC 輸入聲音信號振幅特征的增加只與字母 a-z 有關
使用 Github 中默認設置的訓練結果如下:
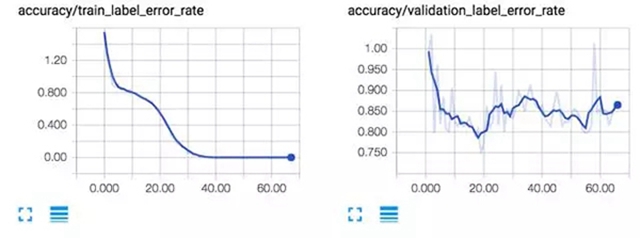
如果你想訓練一個更強大的模型,你可以添加額外的.wav 和.txt 文件到這些文件夾里,或創建一個新的文件夾,并更新 configs / neural_network.ini 的文件夾位置。注意:幾百小時的音頻也需要大量時間來進行訓練,即使你有一塊強大的 GPU。