生成對抗網絡初學入門:一文讀懂GAN的基本原理(附資源)
生成對抗網絡是現在人工智能領域的當紅技術之一。近日,Sigmoidal.io 的博客發表了一篇入門級介紹文章,對 GAN 的原理進行了解釋說明。另外,在該文章的最后還附帶了一些能幫助初學者自己上手開發實驗的資源(包含演講、教程、代碼和論文),其中部分資源機器之心也曾有過報道或解讀,讀者可訪問對應鏈接查閱。
你怎么教一臺從未見過人臉的機器學會繪出人臉?計算機可以存儲拍字節級的照片,但它卻不知道怎樣一堆像素組合才具有與人類外表相關的含義。
多年以來,已經出現了很多各種各樣旨在解決這一問題的生成模型。它們使用了各種不同的假設來建模數據的基本分布,有的假設太強,以至于根本不實用。
對于我們目前的大多數任務來說,這些方法的結果僅僅是次優的。使用隱馬爾可夫模型生成的文本顯得很笨拙,而且可以預料;變分自編碼器生成的圖像很模糊,而且盡管這種方法的名字里面有「變」,但生成的圖像卻缺乏變化。所有這些缺陷都需要一種全新的方法來解決,而這樣的方法最近已經誕生了。
在這篇文章中,我們將對生成對抗網絡(GAN)背后的一般思想進行全面的介紹,并向你展示一些主要的架構以幫你很好地開始學習,另外我們還將提供一些有用的技巧,可以幫你顯著改善你的結果。
GAN 的發明
生成模型的基本思想是輸入一個訓練樣本集合,然后形成這些樣本的概率分布的表征。常用的生成模型方法是直接推斷其概率密度函數。
在我第一次學習生成模型時,我就禁不住想:既然我們已經有如此多的真實訓練樣本了,為什么還要麻煩地做這種事呢?答案很有說服力,這里給出了幾個需要優秀生成模型的可能的應用:
- 模擬實驗的可能結果,降低成本,加速研究
- 使用預測出的未來狀態來規劃行動——比如「知道」道路下一時刻狀況的 GAN
- 生成缺失的數據和標簽——我們常常缺乏格式正確的規整數據,而這會導致過擬合
- 高質量語音生成
- 自動提升照片的質量(圖像超分辨率)
2014 年,Ian Goodfellow 及其蒙特利爾大學的同事引入了生成對抗網絡(GAN)。這是一種學習數據的基本分布的全新方法,讓生成出的人工對象可以和真實對象之間達到驚人的相似度。
GAN 背后的思想非常直觀:生成器和鑒別器兩個網絡彼此博弈。生成器的目標是生成一個對象(比如人的照片),并使其看起來和真的一樣。而鑒別器的目標就是找到生成出的結果和真實圖像之間的差異。

這張圖給出了生成對抗網絡的一個大致概覽。目前最重要的是要理解 GAN 差不多就是把兩個網絡放到一起工作的方法——生成器和鑒別器都有它們自己的架構。要更好地理解這種思想的根源,我們需要回憶一些基本的代數知識并且問我們自己一個問題:如果一個網絡分類圖像的能力比大多數人還好,那么我們該怎么欺騙它?
對抗樣本
在我們詳細描述 GAN 之前,我們先看看一個有些近似的主題。給定一個訓練后的分類器,我們能生成一個能騙過該網絡的樣本嗎?如果我們可以,那看起來又會如何?
事實證明,我們可以。
不僅如此,對于幾乎任何給定的圖像分類器,都可以通過圖像變形的方式,在新圖像看起來和原圖像基本毫無差別的情況下,讓網絡得到有很高置信度的錯誤分類結果!這個過程被稱為對抗攻擊(adversarial attack),而這種生成方式的簡單性能夠給 GAN 提供很多解釋。
對抗樣本(adversarial example)是指經過精心計算得到的旨在誤導分類器的樣本。下圖是這一過程的一個示例。左邊的熊貓所屬的分類就和右邊的不一樣——右邊的圖被分類為了長臂猿。

圖片來自:Goodfellow, 2017
圖像分類器本質上是高維空間中的一個復雜的決策邊界。當然,在涉及到圖像分類時,我們沒法畫出這樣的邊界線。但我們可以肯定地假設,當訓練完成后,得到的網絡無法泛化到所有的圖像上——只能用于那些在訓練集中的圖像。這樣的泛化很可能不能很好地近似真實情況。換句話說,它與我們的數據過擬合了——而我們可以利用這一點。
讓我們首先向圖像加入一些隨機噪聲,并且確保噪聲非常接近于 0。我們可以通過控制噪聲的 L2 范數來實現這一點。你不用擔心 L2 范數這個數學概念,對于大多數實際應用而言,你可以將其看作是一個向量的長度。這里的訣竅是你的圖像中的像素越多,其平均 L2 范數就越大。所以,如果你的噪聲的范數足夠低,你就可以認為它在視覺上是不可感知的;但是在向量空間中,加入噪聲的圖像可以與原始圖像相距非常遠。
為什么會這樣呢?
如果 H×W 的圖像是一個向量,那么我們加入其中的 H×W 噪聲也是一個向量。原始圖像有各種各樣相當密集的顏色——這會增加 L2 范數。另一方面,噪聲則從視覺上看起來是一張混亂的而且相當蒼白的圖像——一個小范數的向量。最后我們將它們加到一起,得到的受損圖像看起來和原圖像很接近,但卻會被錯誤地分類!
現在,如果原始類別「狗」的決策邊界沒有那么遠(在 L2 范數角度來看),那么增加的這點噪聲會將新的圖像帶到決策邊界之外。
你不需要成為世界級的拓撲學家,也能理解特定類別的流形或決策邊界。因為每張圖像只是高維空間中的一個向量,在它們之上訓練的分類器就是將「所有猴子」定義為「這個用隱含參數描述的高維 blob(二進制大對象)中的所有向量」。我們將這個 blob 稱為該類別的決策邊界。
好了,也就是說我們可以通過添加隨機噪聲來輕松欺騙網絡。那生成新圖像還必須做什么?
生成器和鑒別器
現在我們已經簡單了解了對抗樣本,我們離 GAN 只有一步之遙了!那么,如果我們前面部分描述的分類器網絡是為二分類(真和加)設計的呢?根據 Goodfellow 等人那篇原始論文的說法,我們稱之為鑒別器(Discriminator)。
現在讓我們增加一個網絡,讓其可以生成會讓鑒別器錯誤分類為「真」的圖像。這個過程和我們在對抗樣本部分使用的過程完全一樣。這個網絡稱為生成器(Generator)。對抗訓練這個過程為其賦予了一些迷人的特性。
在訓練的每一步,鑒別器都要區分訓練集和一些假樣本的圖像,這樣它區分真假的能力就越來越強。在統計學習理論中,這本質上就意味著學習到了數據的底層分布。
那當鑒別器非常擅長識別真假時,欺騙它能有什么好處呢?沒錯!能用來學習以假亂真的贗品!

圖片來自:Goodfellow, 2016
有一個古老但睿智的數學結果最小最大定理(Minimax theorem)開啟了我們所知的博弈論的先河,其表明:對于零和博弈中的兩個玩家而言,最小最大解決方案與納什均衡是一樣的。
哇!這都說的啥!
簡單來說,當兩個玩家(D 和 G)彼此競爭時(零和博弈),雙方都假設對方采取最優的步驟而自己也以最優的策略應對(最小最大策略),那么結果就已經預先確定了,玩家無法改變它(納什均衡)。
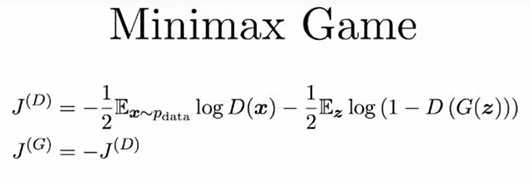
圖片來自:Goodfellow, 2017
所以,對于我們的網絡而言,這意味著如果我們訓練它們足夠長時間,那么生成器將會學會如何從真實「分布」中采樣,這意味著它開始可以生成接近真實的圖像,同時鑒別器將無法將其與真實圖像區分開。
上手學習的最佳架構
理論歸理論,當涉及到實踐時,尤其是在機器學習領域,很多東西就是沒法起效。幸運的是,我們收集了一些有用的小點子,可以幫助得到更好的結果。在這篇文章中,我們將首先回顧一些經典的架構,并提供一些相關鏈接。
1. 深度卷積生成對抗網絡(DCGAN)
在 GAN 的第一篇論文出來之后的大概一年時間里,訓練 GAN 與其說是科學,倒不如說是藝術——模型很不穩定,需要大量調整才能工作。2015 年時,Radford 等人發表了題為《使用深度卷積生成對抗網絡的無監督表征學習(Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks)》的論文,描述了之后被稱為 DCGAN 的著名模型。
")
圖片來自:Radford et al., 2015
關于 DCGAN,最值得一提的是這個架構在大多數情況下都是穩定的。這是第一篇使用向量運算描述生成器學習到的表征的固有性質的論文:這與 Word2Vec 中的詞向量使用的技巧一樣,但卻是對圖像操作的!
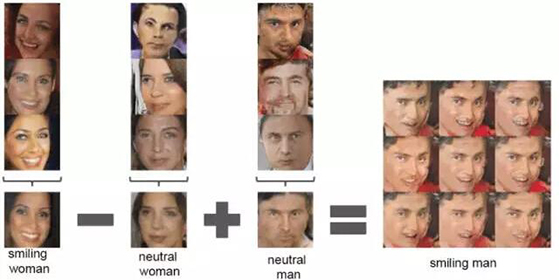
圖片來自:Radford et al., 2015
DCGAN 是最簡單的穩定可靠的模型,我們推薦從它開始上手。后面我們給出了一些訓練和實現的有用技巧,并提供了代碼示例的鏈接。
2. 條件 GAN(Conditional GAN)
這是研究者提出的一種 GAN 的元架構的擴展,以便提升生成圖像的質量,你也可以把它稱為一個小技巧,百分之百沒問題。其思想是,如果你的一些數據點有標簽,你可以使用它們來構建顯著的表征。這和你使用了哪種架構無關——這個擴展每次都是一樣的。你需要做的全部事情就是為其生成器添加另一個輸入。
")
圖片來自:Mirza, 2014
所以,現在又如何呢?現在假如你的模型可以生成各種各樣的動物,但你其實喜歡貓。現在你不再為生成器傳遞生成的噪聲然后期待有最好的結果,而是為第二個輸入增加一些標簽,比如「貓」類別的 ID 或詞向量。在這種情況下,就說生成器是以預期輸入的類別為條件的。
訣竅和技巧
在真正實踐時,你在上面讀到的描述可不夠用。只是介紹該算法的概況的教程也不行——通常他們的方法僅在用于演示的小數據集上才有效。在這篇文章中,我們的目標是為你提供一整套能讓你自己上手研究 GAN 的工具,讓你能立馬開始自己開發炫酷的東西。
所以,你已經實現了你自己的 GAN 或從 GitHub 上克隆了一個(說實話,這是我力挺的開發方式)。在哪種隨機梯度下降(SGD)的效果最好上,目前還不存在普遍共識,所以最好就選擇你自己最喜歡的(我使用 Adam),并且在你實施長時間的訓練之前要對學習率進行仔細的調節——這可以節省你大量時間。一般的工作流程很簡單直接:
- 采樣訓練樣本的一個 minibatch,然后計算它們的鑒別器分數;
- 得到一個生成樣本 minibatch,然后計算它們的鑒別器分數;
- 使用這兩個步驟累積的梯度執行一次更新。
應該分開處理訓練和生成的 minibatch,并且分別為不同的 batch 計算 batch norm,這是很關鍵,可以確保鑒別器有快速的初始訓練。
有時候,當生成器執行一步時,讓鑒別器執行一步以上的效果更好。如果你的生成器在損失函數方面開始「獲勝」了,不妨試試這么做。
如果你在生成器中使用了 BatchNorm 層,這可能會導致 batch 之間出現很強的相關性,如下圖所示:

圖片來自:Goodfellow, 2016
基本而言,每一個 batch 都會得到同樣的結果,其中只是稍微有些不同。你怎么防止這種情況發生?一種方法是預計算平均像素和標準差,然后每次都使用,但這常常會導致過擬合。作為替代,還有一種被稱為虛擬批歸一化(Virtual Batch Normalization)的妙招:在你開始訓練之前預定義一個 batch(讓我們稱其為 R),對于每一個新 batch X,都使用 R 和 X 的級聯來計算歸一化參數。
另一個有趣的技巧是從一個球體上采樣輸入噪聲,而不是從一個立方體上。我們可以通過控制噪聲向量的范數來近似地實現這一目標,但是從高維立方體上真正均勻地采樣會更好一點。
下一個訣竅是避免使用稀疏梯度,尤其是在生成器中。只需將特定的層換成它們對應的「平滑」的類似層就可以了,比如:
- ReLU 換成 LeakyReLU
- 最大池化換成平均池化、卷積+stride
- Unpooling 換成去卷積
結論
在這篇文章中,我們解釋了生成對抗網絡,并且給出了一些訓練和實現的實用技巧。在下面的資源一節中,你可以找到一些 GAN 實現,能幫你上手你自己的實驗。
資源
演講
- Ian Goodfellow 在 NIPS 2016 的演講《生成對抗網絡》:參閱機器之心報道《獨家 | GAN 之父 NIPS 2016 演講現場直擊:全方位解讀生成對抗網絡的原理及未來》
- Ian Goodfellow 演講《對抗樣本和對抗訓練》:https://www.youtube.com/watch?v=CIfsB_EYsVI
- Soumith Chintala 在 NIPS 2016 的演講《如何訓練 GAN》:https://www.youtube.com/watch?v=X1mUN6dD8uE
教程
- 來自 O'Reilly 的全面教程《生成對抗網絡初學者》:https://www.oreilly.com/learning/generative-adversarial-networks-for-beginners
- 極簡教程,有很多可以發揮的空間:https://github.com/uclaacmai/Generative-Adversarial-Network-Tutorial
代碼庫
- TensorFlow 實現 DCGAN:https://github.com/carpedm20/DCGAN-tensorflow
- PyTorch 實現 DCGAN:https://github.com/pytorch/examples/tree/master/dcgan
- 使用條件 GAN 生成動畫人物:https://github.com/m516825/Conditional-GAN
論文
- 生成對抗網絡(Generative Adversarial Networks):https://arxiv.org/abs/1406.2661)
- 使用深度卷積生成對抗網絡的無監督表征學習)Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks):https://arxiv.org/abs/1511.06434
- 條件生成對抗網絡(Conditional Generative Adversarial Nets):https://arxiv.org/abs/1411.1784
原文:https://sigmoidal.io/beginners-review-of-gan-architectures/
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】