一文搞懂HBase的基本原理
本文轉載自微信公眾號「大數據技術與數倉」,作者西貝。轉載本文請聯系大數據技術與數倉公眾號。
本文會對HBase的基本原理進行剖析,通過本文你可以了解到:
- CAP理論
- NoSQL出現的原因
- HBase的特點及使用場景
- HBase的數據模型和基本原理
- 客戶端API的基本使用
- 易混淆知識點面試總結
溫馨提示:本文內容較長,如果覺得有用,建議收藏。另外記得分享、點贊、在看,素質三連哦!
從BigTable說起
HBase是在谷歌BigTable的基礎之上進行開源實現的,是一個高可靠、高性能、面向列、可伸縮的分布式數據庫,可以用來存儲非結構化和半結構化的稀疏數據。HBase支持超大規模數據存儲,可以通過水平擴展的方式處理超過10億行數據和百萬列元素組成的數據表。
BigTable是一個分布式存儲系統,利用谷歌提出的MapReduce分布式并行計算模型來處理海量數據,使用谷歌分布式文件系統GFS作為底層的數據存儲,并采用Chubby提供協同服務管理,具備廣泛的應用型、可擴展性、高可用性及高性能性等特點。關于BigTable與HBase的對比,見下表:
| 依賴 | BigTbale | HBase |
|---|---|---|
| 數據存儲 | GFS | HDFS |
| 數據處理 | MapReduce | Hadoop的MapReduce |
| 協同服務 | Chubby | Zookeeper |
CAP理論
2000年,Berkerly大學有位Eric Brewer教授提出了一個CAP理論,在2002年,麻省理工學院的Seth Gilbert(賽斯·吉爾伯特)和Nancy Lynch(南希·林奇)發表了布魯爾猜想的證明,證明了CAP理論的正確性。所謂CAP理論,是指對于一個分布式計算系統來說,不可能同時滿足以下三點:
- 一致性(Consistency)
等同于所有節點訪問同一份最新的數據副本。即任何一個讀操作總是能夠讀到之前完成的寫操作的結果,也就是說,在分布式環境中,不同節點訪問的數據是一致的。
- 可用性(Availability)
每次請求都能獲取到非錯的響應——但是不保證獲取的數據為最新數據。即快速獲取數據,可以在確定的時間內返回操作結果。
- 分區容錯性(Partition tolerance)
以實際效果而言,分區相當于對通信的時限要求。系統如果不能在時限內達成數據一致性,就意味著發生了分區的情況,必須就當前操作在C和A之間做出選擇。即指當出現網絡分區時(系統中的一部分節點無法與其他的節點進行通信),分離的系統也能夠正常運行,即可靠性。
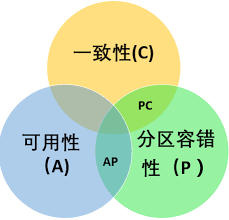
如上圖所示:一個分布式的系統不可能同時滿足一致性、可用性和分區容錯性,最多同時滿足兩個。當處理CAP的問題時,可以有一下幾個選擇:
- 滿足CA,不滿足P。將所有與事務相關的內容都放在同一個機器上,這樣會影響系統的可擴展性。傳統的關系型數據庫。如MySQL、SQL Server 、PostgresSQL等都采用了此種設計原則。
- 滿足AP,不滿足C。不滿足一致性(C),即允許系統返回不一致的數據。其實,對于WEB2.0的網站而言,更加關注的是服務是否可用,而不是一致性。比如你發了一篇博客或者寫一篇微博,你的一部分朋友立馬看到了這篇文章或者微博,另一部分朋友卻要等一段時間之后才能刷出這篇文章或者微博。雖然有延時,但是對于一個娛樂性質的Web 2.0網站而言,這幾分鐘的延時并不重要,不會影響用戶體驗。相反,當發布一篇文章或微博時,不能夠立即發布(不滿足可用性),用戶對此肯定不爽。所以呢,對于WEB2.0的網站而言,可用性和分區容錯性的優先級要高于數據一致性,當然,并沒有完全放棄一致性,而是最終的一致性(有延時)。如Dynamo、Cassandra、CouchDB等NoSQL數據庫采用了此原則。
- 滿足CP,不滿足A。強調一致性性(C)和分區容錯性(P),放棄可用性性(A)。當出現網絡分區時,受影響的服務需要等待數據一致,在等待期間無法對外提供服務。如Neo4J、HBase 、MongoDB、Redis等采用了此種設計原則。
為什么出現NoSQL
所謂NoSQL,即Not Only SQL的縮寫,意思是不只是SQL。上面提到的CAP理論正是NoSQL的設計原則。那么,為什么會興起NoSQL數據庫呢?因為WEB2.0以及大數據時代的到來,關系型數據庫越來越不能滿足需求。大數據、物聯網、移動互聯網和云計算的發展,使得非結構化的數據比例高達90%以上,關系型數據庫由于模型不靈活以及擴展水平較差,在面對大數據時,暴露出了越來越多的缺陷。由此NoSQL數據庫應運而生,更好地滿足了大數據時代及WEB2.0的需求。
面對WEB2.0以及大數據的挑戰,關系型數據庫在以下幾個方面表現欠佳:
- 對于海量數據的處理性能較差
WEB2.0時代,尤其是移動互聯網的發展,UGC(用戶生成內容,User Generated Content)以及PGC(公眾生成內容,Public Generated Content)占據了我們的日常。現如今,自媒體發展遍地開花,幾乎每個人都成了內容的創造者,比如博文、評論、意見、新聞消息、視頻等等,不一而足。可見,這些數據產生的速度之快,數據量之大。比如微博、公眾號、抑或是淘寶,在一分鐘內產生的數據可能就會非常的驚人,面對這些千萬級、億級的數據記錄,關系型數據庫的查詢效率顯然是不能接受的。
- 無法滿足高并發需求
WEB1.0時代,大部分是靜態網頁(即提供什么就看什么),從而在大規模用戶訪問時,可以實現較好的響應能力。但是,在WEB2.0時代,強調的是用戶的交互性(用戶創造內容),所有信息都需要事實動態生成,會造成高并發的數據庫訪問,可能每秒上萬次的讀寫請求,對于很多關系型數據庫而言,這顯示是難以承受的。
- 無法滿足擴展性和高可用性的需求
在當今娛樂至死的時代,熱點問題(吸引人眼球,滿足獵奇心理)會引來一窩蜂的流量,比如微博曝出某明星出軌,熱搜榜會迅速引來大批用戶圍觀(俗稱吃瓜群眾),從而產生大量的互動交流(蹭熱點),這些都會造成數據庫的讀寫負荷急劇增加,從而需要數據庫能夠在短時間內迅速提升性能以應對突發需求(畢竟宕機會非常影響戶體驗)。但是關系型數據庫通常難以水平擴展,不能夠像網頁服務器和應用服務器那樣簡單地通過增加更多的硬件和服務節點來擴展性能和負載能力。
綜上,NoSQL數據庫應運而生,是IT發展的必然。
HBase的特點及使用場景
特點
- 強一致性讀寫
HBase 不是 最終一致性(eventually consistent) 數據存儲. 這讓它很適合高速計數聚合類任務
- 自動分片(Automatic sharding)
HBase 表通過region分布在集群中。數據增長時,region會自動分割并重新分布
- RegionServer 自動故障轉移
- Hadoop/HDFS 集成
HBase 支持本機外HDFS 作為它的分布式文件系統
- MapReduce集成
HBase 通過MapReduce支持大并發處理, HBase 可以同時做源(Source)和匯(Sink)
- Java 客戶端 API
HBase 支持易于使用的 Java API 進行編程訪問
- Thrift/REST API
支持Thrift 和 REST 的方式訪問HBase
- Block Cache 和 布隆過濾器(Bloom Filter)
HBase支持 Block Cache 和 布隆過濾器進行查詢優化,提升查詢性能
- 運維管理
HBase提供內置的用于運維的網頁和JMX 指標
使用場景
HBase并不適合所有場景
首先,**數據量方面 **。確信有足夠多數據,如果有上億或十億行數據,至少單表數據量超過千萬,HBase會是一個很好的選擇。如果只有上千或上百萬行,用傳統的RDBMS可能是更好的選擇。
其次,關系型數據庫特性方面。確信可以不依賴所有RDBMS的額外特性 (如列數據類型、二級索引、事務、高級查詢語言等) 。一個建立在RDBMS上應用,并不能通過簡單的改變JDBC驅動就能遷移到HBase,需要一次完全的重新設計。
再次,硬件方面。確信你有足夠硬件。比如由于HDFS 的默認副本是3,所以一般至少5個數據節點才能夠發揮其特性,另外 還要加上一個 NameNode節點。
最后,數據分析方面。數據分析是HBase的弱項,因為對于HBase乃至整個NoSQL生態圈來說,基本上都是不支持表關聯的。如果主要需求是數據分析,比如做報表,顯然HBase是不太合適的。
HBase的數據模型
基本術語
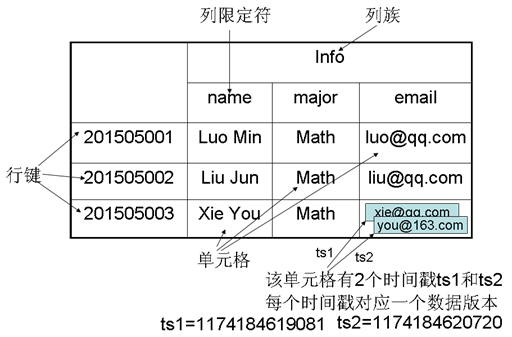
HBase是一個稀疏、多維、持久化存儲的映射表,采用的row key、列族、列限定符合時間戳進行索引,每個cell的值都是字節數組byte[]。了解HBase需要先知道下面的一些概念:
- Namespace
Namespace,即命名空間,是表的邏輯分組,類似于關系型數據庫管理系統的database。HBase存在兩個預定義的特殊的命名空間:hbase和default,其中hbase屬于系統命名空間,用來存儲HBase的內部的表。default屬于默認的命名空間,即如果建表時不指定命名空間,則默認使用default。
- 表
由行和列組成,列劃分為若干個列族
- 行
row key是未解釋的字節數組,在HBase內部,row key是按字典排序由低到高存儲在表中的。每個HBase的表由若干行組成,每個行由行鍵(row key)標識。可以利用這一特性,將經常一起讀取的行存儲在一起。
- 列族
HBase中,列是由列族進行組織的。一個列族所有列成員是有著相同的前綴,比如,列courses:history 和 courses:math都是 列族 courses的成員。冒號(:)是列族的分隔符,用來區分前綴和列名。列族必須在表建立的時候聲明,而列則可以在使用時進行聲明。另外,存儲在一個列族中的所有數據,通常都具有相同的數據類型,這可以極大提高數據的壓縮率。在物理上,一個的列族成員在文件系統上都是存儲在一起。
- 列
列族里面的數據通過列限定符來定位。列通常不需要在創建表時就去定義,也不需要在不同行之間保持一致。列沒有明確的數據類型,總是被視為字節數組byte[]。
- cell
單元格,即通過row key、列族、列確定的具體存儲的數據。單元格中存儲的數據也沒有明確的數據類型,總被視為字節數組byte[]。另外,每個單元格的數據是多版本的,每個版本會對應一個時間戳。
- 時間戳
由于HBase的表數據是具有版本的,這些版本是通過時間戳進行標識的。每次對一個單元格進行修改或刪除時,HBase會自動為其生成并存儲一個時間戳。一個單元格的不同版本是根據時間戳降序的順序進行存儲的,即優先讀取最新的數據。
關于HBase的數據模型,詳見下圖:
概念模型
在HBase概念模型中,一個表可以被看做是一個稀疏的、多維的映射關系,如下圖所示:
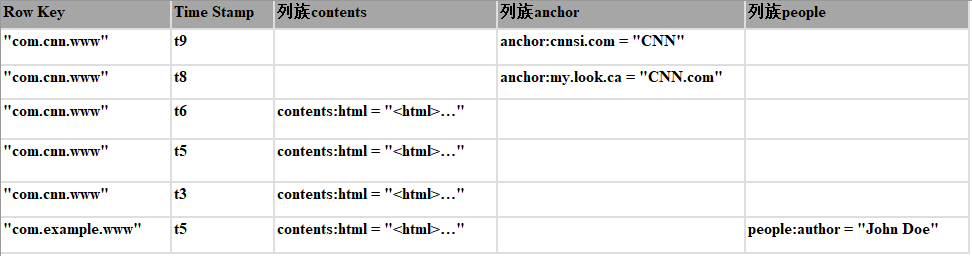
如上表所示:
該表包含兩行數據,分別為com.cnn.www和com.example.www;
三個列族,分別為:contents, anchor 和people。
對于第一行數據(對應的row key為com.cnn.www),列族anchor包含兩列:anchor:cssnsi.com和anchor:my.look.ca;列族contents包含一列:contents:html;
對于第一行數據(對應的row key為com.cnn.www),包含5個版本的數據
對于第二行數據(對應的row key為com.example.www),包含1個版本的數據
上表中可以通過一個四維坐標定位一個單元格數據:[row key,列族,列,時間戳],比如[com.cnn.www,contents,contents:html,t6]
物理模型
從概念模型上看,HBase的表是稀疏的。在物理存儲的時候,是按照列族進行存儲的。一個列限定符(column_family:column_qualifier)可以被隨時添加到已經存在的列族上。
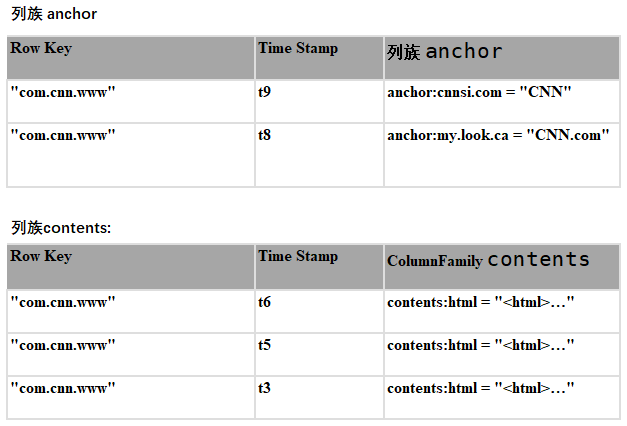
從物理模型上看,概念模型中存在的空單元格是不會被存儲的。比如要訪問contents:html,時間戳為t8,則不會返回值。值得注意的是,如果訪問數據時沒有指定時間戳,則默認訪問最新版本的數據,因為數據是按照版本時間戳降序排列的。
如上表:如果訪問行com.cnn.www,列contents:html,在沒有指定時間戳的情況下,則返回t6對應的數據;同理如果訪問anchor:cnnsi.com,則返回t9對應的數據。
HBase的原理及運行機制
整體架構
通過上面的描述,應該對HBase有了一定的了解。現在我們在來看一下HBase的宏觀架構,如下圖:
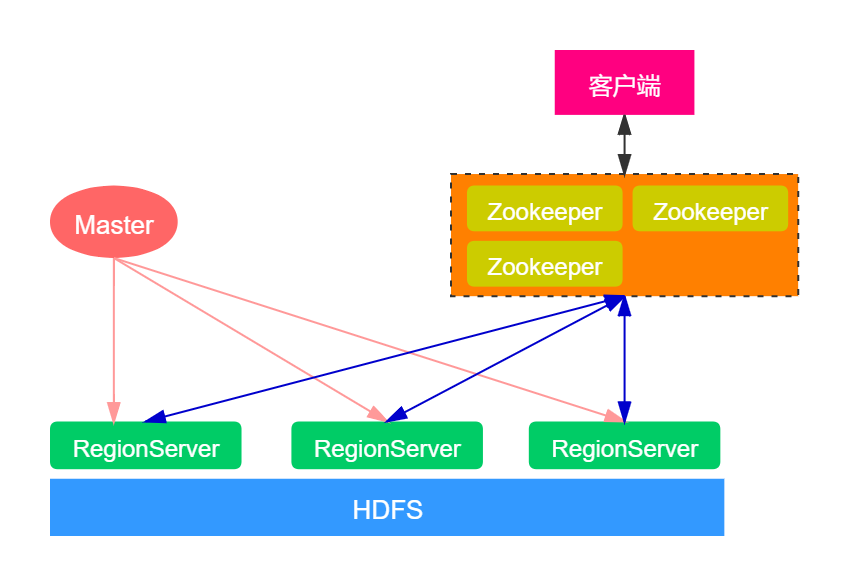
我們先從宏觀的角度看一下HBase的整體架構。從HBase的部署架構上來說,HBase有兩種服務器:Master服務器和RegionServer服務器。一般一個HBase集群有一個Master服務器和幾個RegionServer服務器。
Master服務器負責維護表結構信息,實際的數據都存儲在RegionServer服務器上。在HBase的集群中,客戶端獲取數據由客戶端直連RegionServer的,所以你會發現Master掛掉之后你依然可以查詢數據,但是不能創建新的表了。
- Master
我們都知道,在Hadoop采用的是master-slave架構,即namenode節點為主節點,datanode節點為從節點。namenode節點對于hadoop集群而言至關重要,如果namenode節點掛了,那么整個集群也就癱瘓了。
但是,在HBase集群中,Master服務的作用并沒有那么的重要。雖然是Master節點,其實并不是一個leader的角色。Master服務更像是一個‘打雜’的,類似于一個輔助者的角色。因為當我們連接HBase集群時,客戶端會直接從Zookeeper中獲取RegionServer的地址,然后從RegionServer中獲取想要的數據,不需要經過Master節點。除此之外,當我們向HBase表中插入數據、刪除數據等操作時,也都是直接跟RegionServer交互的,不需要Master服務參與。
那么,Master服務有什么作用呢?Master只負責各種協調工作,比如建表、刪表、移動Region、合并等操作。這些操作有一個共性的問題:就是需要跨RegionServer。所以,HBase就將這些工作分配給了Master服務。這種結構的好處是大大降低了集群對Master的依賴。而Master節點一般只有一個到兩個,一旦宕機,如果集群對Master的依賴度很大,那么就會產生單點故障問題。在HBase中即使Master宕機了,集群依然可以正常地運行,依然可以存儲和刪除數據。
- RegionServer
RegionServer就是存放Region的容器,直觀上說就是服務器上的一個服務。RegionServer是真正存儲數據的節點,最終存儲在分布式文件系統HDFS。當客戶端從ZooKeeper獲取RegionServer的地址后,它會直接從RegionServer獲取數據。對于HBase集群而言,其重要性要比Master服務大。
- Zookeeper
RegionServer非常依賴ZooKeeper服務,ZooKeeper在HBase中扮演的角色類似一個管家。ZooKeeper管理了HBase所有RegionServer的信息,包括具體的數據段存放在哪個RegionServer上。客戶端每次與HBase連接,其實都是先與ZooKeeper通信,查詢出哪個RegionServer需要連接,然后再連接RegionServer。
我們可以通過zkCli訪問hbase節點的數據,通過下面命名可以獲取hbase:meta表的信息:
[zk: localhost:2181(CONNECTED) 17] get /hbase/meta-region-server
簡單總結Zookeeper在HBase集群中的作用如下:對于服務端,是實現集群協調與控制的重要依賴。對于客戶端,是查詢與操作數據必不可少的一部分。
需要注意的是:當Master服務掛掉時,依然可以進行能讀能寫操作;但是把ZooKeeper一旦掛掉,就不能讀取數據了,因為讀取數據所需要的元數據表hbase:meata的位置存儲在ZooKeeper上。可見zookeeper對于HBase而言是至關重要的。
Region
Region就是一段數據的集合。HBase中的表一般擁有一個到多個Region。Region不能跨服務器,一個RegionServer上有一個或者多個Region。當開始創建表時,數據量小的時候,一個Region足以存儲所有數據,等到數據量逐漸增加,會拆分為多個region;當HBase在進行負載均衡的時候,也有可能會從一臺RegionServer上把Region移動到另一臺RegionServer上。Region是存儲在HDFS的,它的所有數據存取操作都是調用了HDFS的客戶端接口來實現的。一個Region就相當于關系型數據庫中分區表的一個分區。
微觀架構
上一小節對HBase的整體架構進行了說明,接下來再看一下內部細節,如下圖所示:展示了一臺RegionServer的內部架構。
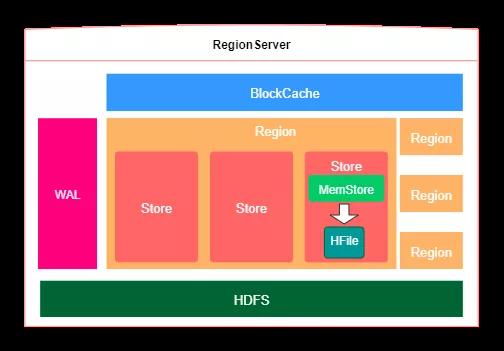
如上圖所示:一個RegionServer可以存儲多個region,Region相當于一個數據分片。每一個Region都有起 始rowkey和結束rowkey,代表了它所存儲的row范圍。在一個region內部,包括多個store,其中一個store對應一個列族,每個store的內部又包含一個MemStore,主要負責數據排序,等超過一定閾值之后將MemStore的數據刷到HFile文件,HFile文件時最終存儲數據的地方。
值得注意的是:一臺RegionServer共用一個WAL(Write-Ahead Log)預寫日志,如果開啟了WAL,那么當寫數據時會先寫進WAL,可以起到容錯作用。WAL是一個保險機制,數據在寫到Memstore之前,先被寫到WAL了。這樣當故障恢復的時候可以從WAL中恢復數據。另外,每個Store都有一個MemStore,用于數據排序。一臺RegionServer也只有一個BlockCache,用于讀數據是進行緩存。
- WAL預寫日志
**Write Ahead Log (WAL)**會記錄HBase中的所有數據,WAL起到容錯恢復的作用,并不是必須的選項。在HDFS上,WAL的默認路徑是/hbase/WALs/,用戶可以通過hbase.wal.dir進行配置。
WAL默認是開啟的,如果關閉,可以使用下面的命令Mutation.setDurability(Durability.SKIP_WAL)。WAL支持異步和同步的寫入方式,異步方式通過調用下面的方法Mutation.setDurability(Durability.ASYNC_WAL)。同步方式通過調用下面的方法:Mutation.setDurability(Durability.SYNC_WAL),其中同步方式是默認的方式。
關于異步WAL,當有Put、Delete、Append操作時,并不會立即觸發同步數據。而是要等到一定的時間間隔,該時間間隔可以通過參數hbase.regionserver.optionallogflushinterval進行設定,默認是1000ms。
- MemStore
每個Store中有一個MemStore實例。數據寫入WAL之后就會被放入MemStore。MemStore是內存的存儲對象,只有當MemStore滿了的時候才會將數據刷寫(flush)到HFile中。
為了讓數據順序存儲從而提高讀取效率,HBase使用了LSM樹結構來存儲數據。數據會先在Memstore中 整理成LSM樹,最后再刷寫到HFile上。
關于MemStore,很容易讓人混淆。數據在被刷到HFile之前,已經被存儲到了HDFS的WAL上了,那么為什么還要在放入MemStore呢?其實很簡單,我們都知道HDFS是不能修改的,而HBase的數據又是按照Row Key進行排序的,其實這個排序的過程就是在MemStore中進行的。值得注意的是:MemStore的作用不是為了加快寫速度,而是為了對Row Key進行排序。
- HFile
HFile是數據存儲的實際載體,我們創建的所有表、列等數據都存儲在HFile里面。當Memstore達到一定閥值,或者達到了刷寫時間間隔閥值的時候,HBaes會被這個Memstore的內容刷寫到HDFS系統上,稱為一個存儲在硬盤上的HFile文件。至此,我們數據真正地被持久化到硬盤上。
Region的定位
在開始講解HBase的數據讀寫流程之前,先來看一下Region是怎么定位的。我們知道Region是HBase非常重要的一個概念,Region存儲在RegionServer中,那么客戶端在讀寫操作時是如何定位到所需要的region呢?關于這個問題,老版本的HBase與新版本的HBase有所不同。
老版本HBase(0.96.0之前)
老版本的HBase采用的是為三層查詢架構,如下圖所示:
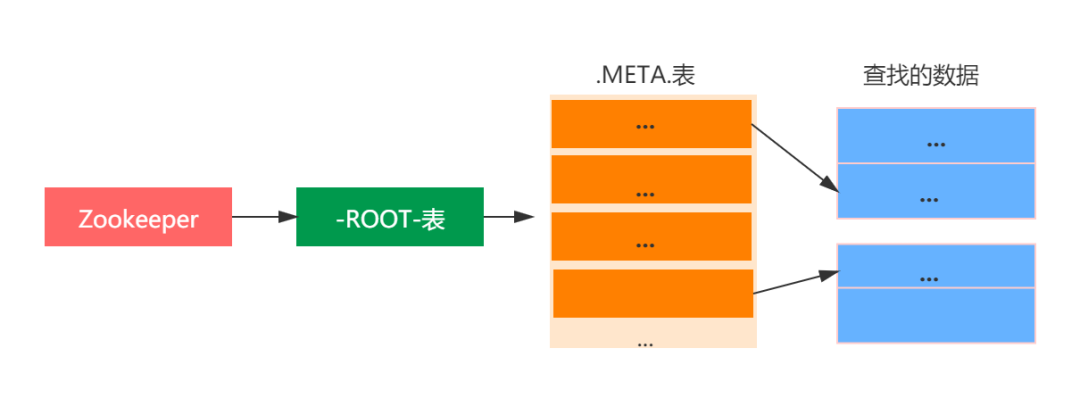
如上圖:第一層定位是Zookeeper中的節點數據,記錄了-ROOT-表的位置信息;
第二層-ROOT-表記錄了.META.region位置信息,-ROOT-表只有一個region,通過-ROOT-表可以訪問.META.表中的數據
第三層.META.表,記錄了用戶數據表的region位置信息,.META.表可以有多個region。
整個查詢步驟如下:
第一步:用戶通過查找zk(ZooKeeper)的/hbase/root-regionserver節點來知道-ROOT-表的RegionServer位置。
第二步:訪問-ROOT-表,查找所需要的數據表的元數據信息存在哪個.META.表上,這個.META.表在哪個RegionServer上。
第四步:訪問.META.表來看你要查詢的行鍵在什么Region范圍里面。
第五步:連接具體的數據所在的RegionServer,這個一步才開始在很正的查詢數據。
新版本HBase
老版本的HBase尋址存在很多弊端,在新版本中進行了改進。采用的是二級尋址的方式,僅僅使用 hbase:meta表來定位region,那么 從哪里獲取hbase:meta的信息呢,答案是zookeeper。在zookeeper中存在一個/hbase/meta-region-server節點,可以獲取hbase:meta表的位置信息,然后通過hbase:meta表查詢所需要數據所在的region位置信息。
整個查詢步驟如下:
第一步:客戶端先通過ZooKeeper的/hbase/meta-region-server節點查詢hbase:meta表的位置。
第二步:客戶端連接hbase:meta表所在的RegionServer。hbase:meta表存儲了所有Region的行鍵范圍信息,通過這個表就可以查詢出你要存取的rowkey屬于哪個Region的范圍里面,以及這個Region屬于哪個 RegionServer。
第三步:獲取這些信息后,客戶端就可以直連擁有你要存取的rowkey的RegionServer,并直接對其操作。
第四步:客戶端會把meta信息緩存起來,下次操作就不需要進行以上加載hbase:meta的步驟了。
客戶端API基本使用
- public class Example {
- private static final String TABLE_NAME = "MY_TABLE_NAME_TOO";
- private static final String CF_DEFAULT = "DEFAULT_COLUMN_FAMILY";
- public static void createOrOverwrite(Admin admin, HTableDescriptor table) throws IOException {
- if (admin.tableExists(table.getTableName())) {
- admin.disableTable(table.getTableName());
- admin.deleteTable(table.getTableName());
- }
- admin.createTable(table);
- }
- public static void createSchemaTables(Configuration config) throws IOException {
- try (Connection connection = ConnectionFactory.createConnection(config);
- Admin admin = connection.getAdmin()) {
- HTableDescriptor table = new HTableDescriptor(TableName.valueOf(TABLE_NAME));
- table.addFamily(new HColumnDescriptor(CF_DEFAULT).setCompressionType(Algorithm.NONE));
- System.out.print("Creating table. ");
- createOrOverwrite(admin, table);
- System.out.println(" Done.");
- }
- }
- public static void modifySchema (Configuration config) throws IOException {
- try (Connection connection = ConnectionFactory.createConnection(config);
- Admin admin = connection.getAdmin()) {
- TableName tableName = TableName.valueOf(TABLE_NAME);
- if (!admin.tableExists(tableName)) {
- System.out.println("Table does not exist.");
- System.exit(-1);
- }
- HTableDescriptor table = admin.getTableDescriptor(tableName);
- // 更新table
- HColumnDescriptor newColumn = new HColumnDescriptor("NEWCF");
- newColumn.setCompactionCompressionType(Algorithm.GZ);
- newColumn.setMaxVersions(HConstants.ALL_VERSIONS);
- admin.addColumn(tableName, newColumn);
- // 更新column family
- HColumnDescriptor existingColumn = new HColumnDescriptor(CF_DEFAULT);
- existingColumn.setCompactionCompressionType(Algorithm.GZ);
- existingColumn.setMaxVersions(HConstants.ALL_VERSIONS);
- table.modifyFamily(existingColumn);
- admin.modifyTable(tableName, table);
- // 禁用table
- admin.disableTable(tableName);
- // 刪除column family
- admin.deleteColumn(tableName, CF_DEFAULT.getBytes("UTF-8"));
- // 刪除表,首先要禁用表
- admin.deleteTable(tableName);
- }
- }
- public static void main(String... args) throws IOException {
- Configuration config = HBaseConfiguration.create();
- config.addResource(new Path(System.getenv("HBASE_CONF_DIR"), "hbase-site.xml"));
- config.addResource(new Path(System.getenv("HADOOP_CONF_DIR"), "core-site.xml"));
- createSchemaTables(config);
- modifySchema(config);
- }
- }
易混淆知識點總結
Q1:MemStore的作用是什么?
在HBase中,一個表可以有多個列族,一個列族在物理上是存儲在一起的,一個列族會對應一個store,在store的內部會存在一個MemStore,其作用并不是為了提升讀寫速度,而是為了對RowKey進行排序。我們知道,HBase的數據是存儲在HDFS上的,而HDFS是不支持修改的,HBase為了按RowKey進行排序,首先會將數據寫入MemStore,數據會先在Memstore中整理成LSM樹,最后再刷寫到HFile上。
總之一句話:Memstore的實現目的不是加速數據寫入或讀取,而是維持數據結構。
Q2:讀取數據時會先從MemStore讀取嗎?
MemStore的作用是為了按RowKey進行排序,其作用不是為了提升讀取速度的。讀取數據的時候是有專門的緩存叫BlockCache,如果開啟了BlockCache,就是先讀BlockCache,然后才是讀HFile+Memstore的數據。
Q3:BlockCache有什么用?
塊緩存(BlockCache)使用內存來記錄數據,適用于提升讀取性能。當開啟了塊緩存后,HBase會優先從塊緩存中查詢是否有記錄,如果沒有才去檢索存儲在硬盤上的HFile。
值得注意的是,一個RegionServer只有一個BlockCache。BlockCache不是數據存儲的必須組成部分,只是用來優化讀取性能的。
BlockCache的基本原理是:在讀請求到HBase之后,會先嘗試查詢BlockCache,如果獲取不到所需的數據,就去HFile和Memstore中去獲取。如果獲取到了,則在返回數據的同時把Block塊緩存到BlockCache中。
Q4:HBase是怎么刪除數據的?
HBase刪除記錄并不是真的刪除了數據,而是標識了一個墓碑標記(tombstone marker),把這個版本連同之前的版本都標記為不可見了。這是為了性能著想,這樣HBase就可以定期去清理這些已經被刪除的記錄,而不用每次都進行刪除操作。所謂定期清理,就是按照一定時間周期在HBase做自動合并(compaction,HBase整理存儲文件時的一個操作,會把多個文件塊合并成一個文件)。這樣刪除操作對于HBase的性能影響被降到了最低,即便是在很高的并發負載下大量刪除記錄也是OK的。
合并操作分為兩種:Minor Compaction和Major Compaction。
其中Minor Compaction是將Store中多個HFile合并為一個HFile。在這個過程中達到TTL的數據會被移除,但是被手動刪除的數據不會被移除。這種合并觸發頻率較高。
而Major Compaction合并Store中的所有HFile為一個HFile。在這個過程中被手動刪除的數據會被真正地移除。同時被刪除的還有單元格內超過MaxVersions的版本數據。這種合并觸發頻率較低,默認為7天一次。不過由于Major Compaction消耗的性能較大,一般建議手動控制MajorCompaction的時機。
需要注意的是:Major Compaction刪除的是那些帶墓碑標記的數據,而Minor Compaction合并的時候直接會忽略過期數據文件,所以過期的這些文件會在Minor Compaction的時候就被刪除。
Q5:為什么HBase具有高性能的讀寫能力?
因為HBase使用了一種LSM的存儲結構,在LSM樹的實現方式中,會在數據存儲之前先對數據進行排序。LSM樹是Google BigTable和HBase的基本存儲算法,它是傳統關系型數據庫的B+樹的改進。算法的核心在于盡量保證數據是順序存儲到磁盤上的,并且會有頻率地對數據進行整理,確保其順序性。
LSM樹就是一堆小樹,在內存中的小樹即memstore,每次flush,內存中的memstore變成磁盤上一個新的storefile。這種批量的讀寫操作使得HBase的性能較高。
Q6:Store與列簇是什么關系?
Region是HBase的核心模塊,而Store則是Region的核心模塊。每個Store對應了表中的一個列族存儲。每個Store包含一個MemStore和若干個HFile。
Q7:WAL是RegionServer共享的,還是Region級別共享的?
在HBase中,每個RegionServer只需要維護一個WAL,所有Region對象共用一個WAL,而不是每個Region都維護一個WAL。這種方式對于多個Region的更新操作所發生的的日志修改,只需要不斷地追加到單個日志文件中,不需要同時打開并寫入多個日志文件,這樣可以減少磁盤尋址次數,提高寫性能。
但是這種方式也存在一個缺點,如果RegionServer發生故障,為了恢復其上的Region對象,需要將RegionServer上的WAL按照其所屬的Region對象進行拆分,然后分發到其他RegionServer上執行恢復操作。
Q8:Master掛掉之后,還能查詢數據嗎?
可以的。Master服務主要負責表和Region的管理工作。主要作用有:
- 管理用戶對表的增加、刪除、修改操作
- 實現不同RegionServer之前的負載均衡
- Region的分裂與合并
- 對發生故障的RegionServer的Region進行遷移
客戶端訪問HBase時,不需要Master的參與,只需要連接zookeeper獲取hbase:meta地址,然后直連RegionServer進行數據讀寫操作,Master僅僅維護表和Region的元數據信息,負載很小。但是Master節點也不能長時間的宕機。
總結
本文首先從谷歌的BigTable說起,然后介紹了CAP相關理論,并分析了NoSQL出現的原因。接著對HBase的數據模型進行了剖析,然后詳細描述了HBase的原理和運行機制。最后給出了客戶端API的基本使用,并對常見的、易混淆的知識點進行了解釋。