













將未來信息作為正則項,Twin Networks加強RNN對長期依賴的建模能力
Yoshua Bengio 等人提出了一種新型循環(huán)神經(jīng)網(wǎng)絡(luò),該網(wǎng)絡(luò)由前向和反向循環(huán)網(wǎng)絡(luò)組成,并且前向和反向隱藏狀態(tài)之間有一定的緊密度而共同預(yù)測相同的符號。因為前向 RNN 包含了前面序列的信息,而反向 RNN 在同一位置包含了未來的信息,所以利用正則項連接這兩種信息將有助于 RNN 獲取學(xué)習(xí)長期依賴的能力。

論文地址:https://arxiv.org/abs/1708.06742
對序列數(shù)據(jù)(如文本)的長期依賴(long-term dependencies)建模一直是循環(huán)神經(jīng)網(wǎng)絡(luò)中長期存在的問題。這個問題和目前循環(huán)神經(jīng)網(wǎng)絡(luò)架構(gòu)沒有明確的規(guī)劃是嚴(yán)格相關(guān)的,更具體來說,循環(huán)神經(jīng)網(wǎng)絡(luò)只是在給定前一個符號(token)的基礎(chǔ)上預(yù)測下一個符號。在本論文中,我們介紹了一種鼓勵 RNN 規(guī)劃未來的簡單方法。為了實現(xiàn)這種規(guī)劃,我們引進了一種反向訓(xùn)練和生成序列的附加神經(jīng)網(wǎng)絡(luò),并且要求前向 RNN 和反向 RNN 中的狀態(tài)有一定的緊密度以預(yù)測相同的符號。在每一步中,前向 RNN 的狀態(tài)要求匹配包含在反向狀態(tài)中的未來信息。我們假設(shè)這種方法簡化了長期依賴關(guān)系的建模,因此更有助于生成全局一致的樣本。該模型在語音識別任務(wù)上實現(xiàn)了 12% 的相對提升(相對于基線 7.6,CER 達到了 6.7)。
模型
給定數(shù)據(jù)集 X = {x^1 , . . . , x^ n },其中 x={x_1, . . . , x_T } 為觀察序列,RNN 模型對序列空間的概率 p(x) 及其概率密度進行建模,通常我們會訓(xùn)練 P 以***化觀察數(shù)據(jù)的對數(shù)似然函數(shù) :
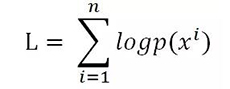
RNN 會將序列的概率分解為:
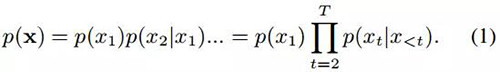
也就是說,RNN 在給定前面所有元素的情況下預(yù)測下一個元素。在每一步中,RNN 迭代地總結(jié)時間步 t 之前的序列值而更新一個隱藏狀態(tài)![]() (下文用 h_ft 代表)。即
(下文用 h_ft 代表)。即![]() ,其中 f 代表網(wǎng)絡(luò)前向地讀取序列,而Φ_f 為典型的非線性函數(shù),如 LSTM 單元。預(yù)測值 x_t 在 h_ft 的頂部執(zhí)行另一個非線性轉(zhuǎn)換,即 p_f(x_t|x<t)=ψ_f(h_ft)。因此,h_ft 總結(jié)了前面序列中的信息。該方法的基本思想是提升 h_ft,以令其不僅包含對預(yù)測 x_t 有用的信息同時還兼容序列中將要出現(xiàn)的符號信息。
,其中 f 代表網(wǎng)絡(luò)前向地讀取序列,而Φ_f 為典型的非線性函數(shù),如 LSTM 單元。預(yù)測值 x_t 在 h_ft 的頂部執(zhí)行另一個非線性轉(zhuǎn)換,即 p_f(x_t|x<t)=ψ_f(h_ft)。因此,h_ft 總結(jié)了前面序列中的信息。該方法的基本思想是提升 h_ft,以令其不僅包含對預(yù)測 x_t 有用的信息同時還兼容序列中將要出現(xiàn)的符號信息。
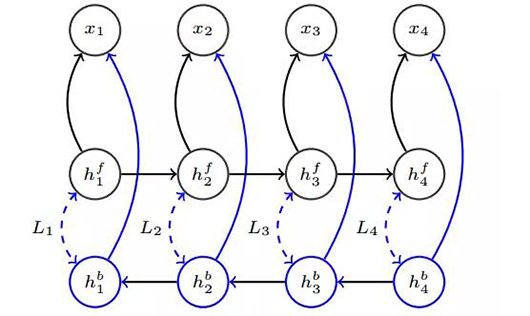
如上圖 1 所示,前向和反向網(wǎng)絡(luò)獨立地預(yù)測序列 {x1, ..., x4}。正則化罰項將匹配前向(或前向參數(shù)函數(shù))和反向隱藏狀態(tài)。前向網(wǎng)絡(luò)會從對數(shù)似然目標(biāo)函數(shù)接收到梯度信號,并且狀態(tài)之間的 L_i 是預(yù)測相同的符號。反向網(wǎng)絡(luò)僅通過***化數(shù)據(jù)對數(shù)似然度而進行訓(xùn)練。在評估階段中,部分網(wǎng)絡(luò)(藍色表達)將會被丟棄。L_i 的成本為歐幾里德距離或通過仿射變換 g 學(xué)到的度量![]() 。
。
正則化損失
我們最開始試驗是使用 L2 損失來匹配前向和反向隱藏狀態(tài)。雖然這給我們一定的提升,但是我們發(fā)現(xiàn)這種損失太嚴(yán)格而不允許模型有足夠的靈活性來生成稍微不同的前向和反向隱藏狀態(tài)。因此,我們試驗了參數(shù)方程以匹配前向和反向狀態(tài)。這種情況下,我們簡單地使用了一個參數(shù)仿射轉(zhuǎn)換(parametric affine transformation),以允許前向路徑不一定精確地匹配反向路徑。雖然不一定完全精確,但這種方法只允許前向隱藏狀態(tài)包含反向隱藏狀態(tài)的信息。實驗上,我們發(fā)現(xiàn)參數(shù)損失在語音-文本生成任務(wù)中給模型很大的提升。具體來說,我們首先使用 L2 正則項為![]() ,而我們使用的參數(shù)正則項為
,而我們使用的參數(shù)正則項為![]() ,其中 g(·) 為 h_ft 上的簡單仿射變換。
,其中 g(·) 為 h_ft 上的簡單仿射變換。
據(jù)集上的平均字符錯誤率(CER%)")
表 1:WSJ 數(shù)據(jù)集上的平均字符錯誤率(CER%)
我們在表 1 中總結(jié)了實驗結(jié)果。從仿射變換學(xué)到的度量方法展現(xiàn)了非常好的性能,并且我們從網(wǎng)絡(luò)中解碼并沒有使用任何外部的語言模型,這進一步強調(diào)了該正則化方法的重要性。我們的模型相對于基線模型在性能上提升了 12%。
【本文是51CTO專欄機構(gòu)“機器之心”的原創(chuàng)譯文,微信公眾號“機器之心( id: almosthuman2014)”】


















