NLP入門之語音模型原理
這一篇文章其實是參考了很多篇文章之后寫出的一篇對于語言模型的一篇科普文,目的是希望大家可以對于語言模型有著更好地理解,從而在接下來的NLP學習中可以更順利的學習.
1:傳統(tǒng)的語音識別方法:
這里我們講解一下是如何將聲音變成文字,如果有興趣的同學,我們可以深入的研究.
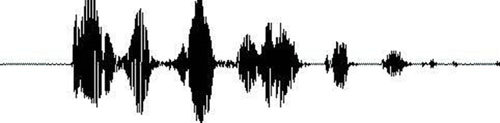
首先我們知道聲音其實是一種波,常見的MP3等都是壓縮的格式,必須要轉化成非壓縮的純波形的文件來處理,下面以WAV的波形文件來示例:
在進行語音識別之前,有的需要把首尾段的靜音進行切除,進行強制對齊,以此來降低對于后續(xù)步驟的干擾,整個靜音的切除技術一般稱為VAD,需要用到對于信號處理的一些技術.
如果要對于聲音進行分析,就需要對于聲音進行分幀,也就是把聲音切成一小塊一小塊,每一小塊稱為一幀,分幀并不是簡單地切開,而是使用的移動窗函數(shù)來實現(xiàn)的,并且?guī)蛶g一般是有交疊的
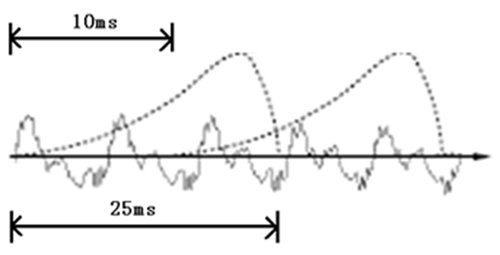
就像上圖這樣
分幀之后,語音就變成了很多個小段,但是波形在時域上是沒有什么描述能力的,因此就必須要將波形進行變換,常見的一種變換方法就是提取MFCC特征,然后根據(jù)人耳的生理特性,把每一幀波變成一個多維度向量,這個向量里是包含了這塊語音的內(nèi)容信息,這個過程叫做聲學特征的提取,但是實際方法有很多,基本類似.
至此,聲音就成了一個12行(假設聲學特征是12維)、N列的一個矩陣,稱之為觀察序列,這里N為總幀數(shù)。觀察序列如下圖所示,圖中,每一幀都用一個12維的向量表示,色塊的顏色深淺表示向量值的大小。
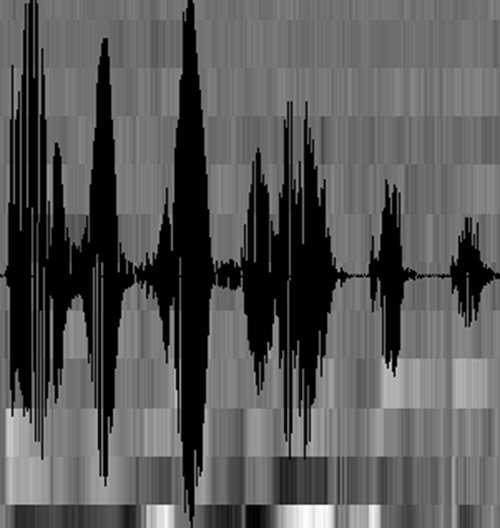
接下來就要介紹怎樣把這個矩陣變成文本了。首先要介紹兩個概念:
1:音素:
單詞的發(fā)音由音素構成。對英語,一種常用的音素集是卡內(nèi)基梅隆大學的一套由39個音素構成的音素集,參見The CMU Pronouncing Dictionary。漢語一般直接用全部聲母和韻母作為音素集,另外漢語識別還分有調無調,不詳述。
1. 狀態(tài):這里理解成比音素更細致的語音單位就行啦。通常把一個音素劃分成3個狀態(tài)。
語音識別是怎么工作的呢?實際上一點都不神秘,無非是:
把幀識別成狀態(tài)(難點)。
把狀態(tài)組合成音素。
把音素組合成單詞。
如下圖所示:
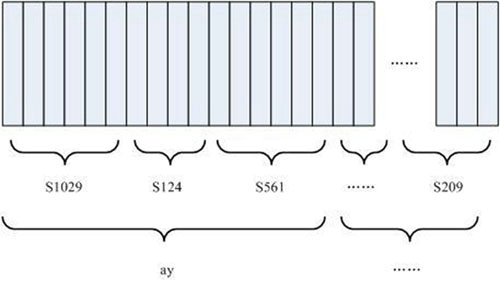
圖中,每個小豎條代表一幀,若干幀語音對應一個狀態(tài),每三個狀態(tài)組合成一個音素,若干個音素組合成一個單詞。也就是說,只要知道每幀語音對應哪個狀態(tài)了,語音識別的結果也就出來了。
那每幀音素對應哪個狀態(tài)呢?有個容易想到的辦法,看某幀對應哪個狀態(tài)的概率最大,那這幀就屬于哪個狀態(tài)。比如下面的示意圖,這幀在狀態(tài)S3上的條件概率最大,因此就猜這幀屬于狀態(tài)S3。
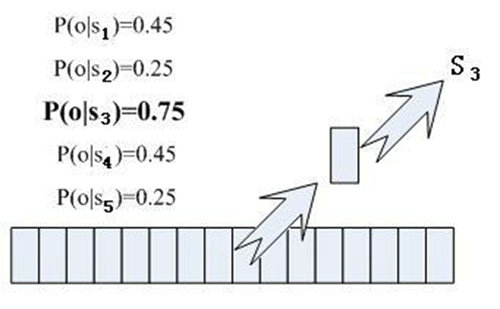
那這些用到的概率從哪里讀取呢?有個叫“聲學模型”的東西,里面存了一大堆參數(shù),通過這些參數(shù),就可以知道幀和狀態(tài)對應的概率。獲取這一大堆參數(shù)的方法叫做“訓練”,需要使用巨大數(shù)量的語音數(shù)據(jù),訓練的方法比較繁瑣,這里不講。
但這樣做有一個問題:每一幀都會得到一個狀態(tài)號,最后整個語音就會得到一堆亂七八糟的狀態(tài)號。假設語音有1000幀,每幀對應1個狀態(tài),每3個狀態(tài)組合成一個音素,那么大概會組合成300個音素,但這段語音其實根本沒有這么多音素。如果真這么做,得到的狀態(tài)號可能根本無法組合成音素。實際上,相鄰幀的狀態(tài)應該大多數(shù)都是相同的才合理,因為每幀很短。
解決這個問題的常用方法就是使用隱馬爾可夫模型(Hidden Markov Model,HMM)。這東西聽起來好像很高深的樣子,實際上用起來很簡單: 第一步,構建一個狀態(tài)網(wǎng)絡。 第二步,從狀態(tài)網(wǎng)絡中尋找與聲音最匹配的路徑。
這樣就把結果限制在預先設定的網(wǎng)絡中,避免了剛才說到的問題,當然也帶來一個局限,比如你設定的網(wǎng)絡里只包含了“今天晴天”和“今天下雨”兩個句子的狀態(tài)路徑,那么不管說些什么,識別出的結果必然是這兩個句子中的一句。
那如果想識別任意文本呢?把這個網(wǎng)絡搭得足夠大,包含任意文本的路徑就可以了。但這個網(wǎng)絡越大,想要達到比較好的識別準確率就越難。所以要根據(jù)實際任務的需求,合理選擇網(wǎng)絡大小和結構。
搭建狀態(tài)網(wǎng)絡,是由單詞級網(wǎng)絡展開成音素網(wǎng)絡,再展開成狀態(tài)網(wǎng)絡。語音識別過程其實就是在狀態(tài)網(wǎng)絡中搜索一條最佳路徑,語音對應這條路徑的概率最大,這稱之為“解碼”。路徑搜索的算法是一種動態(tài)規(guī)劃剪枝的算法,稱之為Viterbi算法,用于尋找全局最優(yōu)路徑。
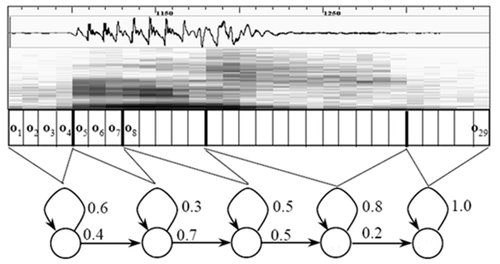
這里所說的累積概率,由三部分構成,分別是:
觀察概率:每幀和每個狀態(tài)對應的概率
轉移概率:每個狀態(tài)轉移到自身或轉移到下個狀態(tài)的概率
語言概率:根據(jù)語言統(tǒng)計規(guī)律得到的概率
其中,前兩種概率從聲學模型中獲取,最后一種概率從語言模型中獲取。語言模型是使用大量的文本訓練出來的,可以利用某門語言本身的統(tǒng)計規(guī)律來幫助提升識別正確率。語言模型很重要,如果不使用語言模型,當狀態(tài)網(wǎng)絡較大時,識別出的結果基本是一團亂麻。
這樣基本上語音識別過程就完成了。
2:端到端的模型
現(xiàn)階段深度學習在模式識別領域取得了飛速的發(fā)展,特別是在語音和圖像的領域,因為深度學習的特性,在語音識別領域中,基于深度學習的聲學模型現(xiàn)如今已經(jīng)取代了傳統(tǒng)的混合高斯模型GMM對于狀態(tài)的輸出進行建模,因此在普通的深度神經(jīng)網(wǎng)絡的基礎之上,基于長短記憶網(wǎng)絡的遞歸神經(jīng)網(wǎng)絡對語音序列的強大的建模能力進一步提高了語音識別的性能,但是這些方法依舊包含著最基礎的隱馬爾可夫HMM的基本結構,因此依舊會出現(xiàn)隱馬爾科夫模型的訓練和解碼的復雜度問題.
基于深度學習的聲學模型訓練過程必須是由傳統(tǒng)的混合高斯模型開始的,然后對訓練數(shù)據(jù)集合進行強制的對齊,然后進行切分得到不同的聲學特征,其實傳統(tǒng)的方式并不利于對于整句話的全局優(yōu)化,并且這個方法也需要額外的語音學和語言學的知識,比如發(fā)音詞典,決策樹單元綁定建模等等,搭建系統(tǒng)的門檻較高等問題.
一些科學家針對傳統(tǒng)的聲學建模的缺點,提出了鏈接時序分類技術,這個技術是將語音識別轉換為序列的轉換問題,這樣一來就可以拋棄了傳統(tǒng)的基于HMM的語音識別系統(tǒng)的一系列假設,簡化了系統(tǒng)的搭建流程,從而可以進一步提出了端到端的語音識別系統(tǒng),減少了語音對于發(fā)音詞典的要求.
端到端的系統(tǒng)是由LSTM的聲學建模方法和CTC的目標函數(shù)組成的,在CTC的準則下,LSTM可以在訓練過程中自動的學習聲學的特征和標注序列的對應關系,也就不需要再進行強制的對數(shù)據(jù)集合進行對齊的過程了.并且可以根據(jù)各種語種的特點,端到端識別直接在字或者單詞上進行建模,但是因為端到端的識別可能是意味著發(fā)展的趨勢,但是因為完全崛棄了語音學的知識,現(xiàn)如今在識別性能上仍然和傳統(tǒng)的基于深度學習的建模方法有著一定的差距,不過我最近在看的一篇論文中,基于端到端的藏語識別已經(jīng)達到甚至超過了現(xiàn)有的通用算法.
就拿藏語舉例,藏語是一種我國的少數(shù)民族語言,但是因為藏族人口較少,相比起對于英文,漢語這樣的大語種來說,存在著語音數(shù)據(jù)收集困難的問題,在上一篇文章中我們可以知道,自然語言處理的最重要的需求就是語料,如果有很好的語料庫自然會事半功倍,這樣就導致了藏語的語音識別研究工作起步較晚,并且因為藏語的語言學知識的匱乏進一步阻礙了藏語語音識別的研究的進展,在我國,藏語是屬于一種單音節(jié)字的語言,在端到端的語音過程中,藏語是建模起來非常簡單的一種語言,但是作為一種少數(shù)民族語言,語料不足會在訓練過程中出現(xiàn)嚴重的稀疏性問題,并且很多人在研究現(xiàn)有的藏語詞典中發(fā)現(xiàn),如果完全崛棄現(xiàn)有的藏語發(fā)音詞典,完全不利用這樣的先驗知識,這樣其實也是不利于技術的發(fā)現(xiàn)的,因此現(xiàn)階段下,采用CTC和語言知識結合的方式來建模,可以解決在資源受限的情況下聲學的建模問題,使得基于端到端的聲學模型方法的識別率超過當下基于隱馬爾科夫的雙向長短時記憶模型.
在基于CD-DNN-HMM架構的語音識別聲學模型中,訓練DNN通常需要幀對齊標簽。在GMM中,這個對齊操作是通過EM算法不斷迭代完成的,而訓練DNN時需要用GMM進行對齊則顯得非常別扭。因此一種不需要事先進行幀對齊的方法呼之欲出。此外對于HMM假設一直受到詬病,等到RNN出現(xiàn)之后,使用RNN來對時序關系進行描述來取代HMM成為當時的熱潮。隨著神經(jīng)網(wǎng)絡優(yōu)化技術的發(fā)展和GPU計算能力的不斷提升,最終使用RNN和CTC來進行建模實現(xiàn)了end-to-end語音識別的聲學模型。CTC的全稱是Connectionist Temporal Classification,中文翻譯大概是連接時序分類。它要達到的目標就是直接將語音和相應的文字對應起來,實現(xiàn)時序問題的分類。
這里仍然可以描述為EM的思想:
E-step:使用BPTT算法優(yōu)化神經(jīng)網(wǎng)絡參數(shù);
M-step:使用神經(jīng)網(wǎng)絡的輸出,重新尋找最有的對齊關系。
CTC可以看成是一個分類方法,甚至可以看作是目標函數(shù)。在構建end-to-end聲學模型的過程中,CTC起到了很好的自動對齊的效果。同傳統(tǒng)的基于CD-DNN-HMM的方法相比,對齊效果引用文章[Alex Graves,2006]中的圖是這樣的效果:
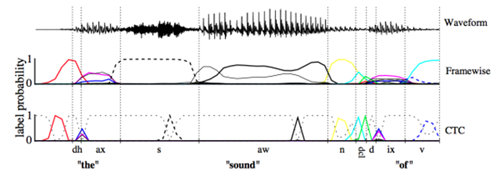
這幅圖可以理解:基于幀對齊的方法強制要求切分好的幀對齊到對應的標簽上去,而CTC則可以時幀的輸出為空,只有少數(shù)幀對齊到對應的輸出標簽上。這樣帶來的差別就是幀對齊的方法即使輸出是正確的,但是在邊界區(qū)域的切分也很難準確,從而給DNN的訓練引入錯誤。c) End-to-end模型由于神經(jīng)網(wǎng)絡強大的建模能力,End-to-end的輸出標簽也不再需要像傳統(tǒng)架構一樣的進行細分。例如對于中文,輸出不再需要進行細分為狀態(tài)、音素或者聲韻母,直接將漢字作為輸出即可;對于英文,考慮到英文單詞的數(shù)量龐大,可以使用字母作為輸出標簽。從這一點出發(fā),我們可以認為神經(jīng)網(wǎng)絡將聲學符號到字符串的映射關系也一并建模學習了出來,這部分是在傳統(tǒng)的框架中時詞典所應承擔的任務。針對這個模塊,傳統(tǒng)框架中有一個專門的建模單元叫做G2P(grapheme-to-phoneme),來處理集外詞(out of vocabulary,OOV)。在end-to-end的聲學模型中,可以沒有詞典,沒有OOV,也沒有G2P。這些全都被建模在一個神經(jīng)網(wǎng)絡中。另外,在傳統(tǒng)的框架結構中,語音需要分幀,加窗,提取特征,包括MFCC、PLP等等。在基于神經(jīng)網(wǎng)絡的聲學模型中,通常使用更裸的Fbank特征。在End-to-en的識別中,使用更簡單的特征比如FFT點,也是常見的做法。或許在不久的將來,語音的采樣點也可以作為輸入,這就是更加徹底的End-to-end聲學模型。除此之外,End-to-end的聲學模型中已經(jīng)帶有了語言模型的信息,它是通過RNN在輸出序列上學習得到的。但這個語言模型仍然比較弱,如果外加一個更大數(shù)據(jù)量的語言模型,解碼的效果會更好。因此,End-to-end現(xiàn)在指聲學模型部分,等到不需要語言模型的時候,才是完全的end-to-end。3、 語言模型(Language Model, LM)語言模型的作用可以簡單理解為消解多音字的問題,在聲學模型給出發(fā)音序列之后,從候選的文字序列中找出概率最大的字符串序列。
4、 解碼傳統(tǒng)的語音識別解碼都是建立在WFST的基礎之上,它是將HMM、詞典以及語言模型編譯成一個網(wǎng)絡。解碼就是在這個WFST構造的動態(tài)網(wǎng)絡空間中,找到最優(yōu)的輸出字符序列。搜索通常使用Viterbi算法,另外為了防止搜索空間爆炸,通常會采用剪枝算法,因此搜索得到的結果可能不是最優(yōu)結果。在end-to-end的語音識別系統(tǒng)中,最簡單的解碼方法是beam search。盡管end-to-end的聲學模型中已經(jīng)包含了一個弱語言模型,但是利用額外的語言模型仍然能夠提高識別性能,因此將傳統(tǒng)的基于WFST的解碼方式和Viterbi算法引入到end-to-end的語音識別系統(tǒng)中也是非常自然的。然而由于聲學模型中弱語言模型的存在,解碼可能不是最優(yōu)的。文章[yuki Kanda, 2016]提出在解碼的時候,需要將這個若語言模型減掉才能得到最優(yōu)結果。