如何使用Python對Instagram進行數據分析?
我寫此文的目的在于展示以編程的方式使用Instagram的基本方法。我的方法可用于數據分析、計算機視覺以及任何你所能想到的酷炫項目中。
Instagram是最大的圖片分享社交媒體平臺,每月活躍用戶約五億,每日有九千五百萬的圖片和視頻被上傳到Instagram。其數據規模巨大,具有很大的潛能。本文將給出如何將Instagram作為數據源而非一個平臺,并介紹在項目中使用本文所給出的開發方法。
API和工具簡介
Instagram提供了官方API,但是這些API有些過時,并且當前所提供的功能也非常有限。因此在本文中,我使用了LevPasha提供的非Instagram官方API。該API支持所有關鍵特性,例如點贊、加粉、上傳圖片和視頻等。它使用Python編寫,本文中我只關注數據端的操作。
我推薦使用Jupyter Notebook和IPython。使用官方Python雖然沒有問題,但是它不提供圖片顯示等特性。
安裝
你可以使用pip安裝該軟件庫,命令如下:
- python -m pip install -e git+https://github.com/LevPasha/Instagram-API-python.git#egg=InstagramAPI
如果系統中尚未安裝ffmpeg,那么在Linux上,可以使用如下命令安裝:
- sudo apt-get install ffmpeg
對于Windows系統,需在Python解釋器中運行如下命令:
- import imageio
- imageio.plugins.ffmpeg.download()
下面使用API,實現登入Instragram:
- from InstagramAPI import InstagramAPI
- username="YOURUSERNAME"
- InstagramAPI = InstagramAPI(username, "YOURPASSWORD")
- InstagramAPI.login()
如果登錄成功,那么你會收到“登陸成功”的消息。
基本請求
做好上面的準備工作后,我們可以著手實現首次請求:
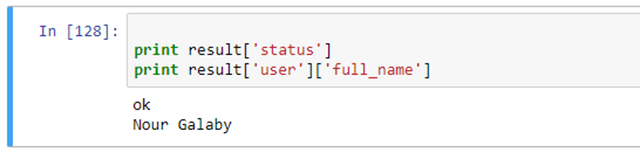
- InstagramAPI.getProfileData()
- result = InstagramAPI.LastJson
- {u'status': u'ok',
- u'user': {u'biography': u'',
- u'birthday': None,
- u'country_code': 20,
- u'email': aaa@hotmail.com',
- u'external_url': u'',
- u'full_name': u'Nour Galaby',
- u'gender': 1,
- u'has_anonymous_profile_picture': False,
- u'hd_profile_pic_url_info': {u'height': 1080,
- u'url': u'https://instagram.fcai2-1.fna.fbcdn.net/t51.2885-1aaa7448121591_1aa.jpg',
- u'width': 1080},
- u'hd_profile_pic_versions': [{u'height': 320,
- u'url': u'https://instagram.fcai2-1.fna.fbcdn.net/t51.2885-19/s320x320/19aa23237_4337448121591_195310aaa32_a.jpg',
- u'width': 320},
- {u'height': 640,
- u'url': u'https://instagram.fcai2-1.fna.fbcdn.net/t51.2885-19/s640x640/19623237_45581744812153_44_a.jpg',
- u'width': 640}],
- u'is_private': True,
- u'is_verified': False,
- u'national_number': 122,
- u'phone_number': u'+201220',
- u'pk': 22412229,
- u'profile_pic_id': u'1550239680720880455_22',
- u'profile_pic_url': u'https://instagram.fcai2-1.fna.fbcdn.net/t51.2885-19/s150x150/19623237_455817448121591_195310166162_a.jpg',
- u'show_conversion_edit_entry': False,
- u'username': u'nourgalaby'}}
如上所示,結果是以JSON格式給出的,其中包括了所有請求的數據。
你可以使用正常的鍵值方式訪問結果數據。例如:
你也可以使用工具(例如Notepad++)查看JSON數據,并一探究竟。
獲取并查看Instagram時間線
下面讓我們實現一些更有用的功能。我們將請求排在時間線最后的帖子,并在Jupyter Notebook中查看。
下面代碼實現獲取時間線:
- InstagramAPI.timelineFeed()
類似于前面的請求實現,我們同樣使用LastJson()查看結果。查看結果JSON數據,我們可以看到其中包括一系列稱為“條目”的鍵值。列表中的每個元素保存了時間線上特定帖子的信息,其中包括如下元素:
- [text]:保存了標題下的帖子文本內容,包括hashtag。
- [likes]:帖子中的點贊數。
- [created_at]:帖子創建時間。
- [comments]:帖子的評論。
- [image_versions]:保存有指向實際JPG文件的鏈接,可使用該鏈接在Jupyter Notebook中顯示圖片。
函數
函數Get_posts_from_list()和Get_url()在帖子列表上循環,查找每個帖子中的URL,并附加到我們的空列表中。
上述函數完成后,我們將得到一個URL列表,如下所示:

我們可以使用IPython.display模塊查看圖片,代碼如下:

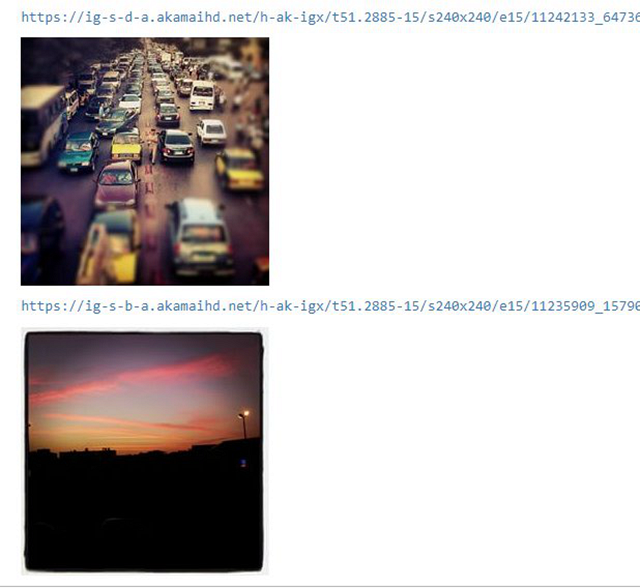
在IPython Notebook中查看圖片是十分有用的功能,我們之后還會使用這些函數去查看結果,敬請繼續。
獲取最受歡迎的帖子
現在我們已經知道了如何發出基本請求,但是如何實現更復雜的請求呢?下面我們要做一些類似的事情,即如何獲取我們的帖子中最受歡迎的。要實現這個目的,首先需要獲取當前登錄用戶的所有帖子,然后將帖子按點贊數排序。
獲取用戶的所有帖子
要獲取所有帖子,我們將使用next_max_id和more_avialable值在結果列表上執行循環。
- import time
- myposts=[]
- has_more_posts = True
- max_id=""
- while has_more_posts:
- InstagramAPI.getSelfUserFeed(maxid=max_id)
- if InstagramAPI.LastJson['more_available'] is not True:
- has_more_posts = False #stop condition
- print "stopped"
- max_id = InstagramAPI.LastJson.get('next_max_id','')
- myposts.extend(InstagramAPI.LastJson['items']) #merge lists
- time.sleep(2) # Slows the script down to avoid flooding the servers
- print len(myposts)
保存和加載數據到磁盤
因為上面的請求可能需要很長的時間才能完成,我們并不想在沒有必要時運行它,因此好的做法是將結果保存起來,并在繼續工作時再次加載。為此,我們將使用Pickle。Pickle可以將任何變量序列化并保存到文件中,進而加載它們。下面給出一個工作例子:
保存:
- import pickle
- filename=username+"_posts"
- pickle.dump(myposts,open(filename,"wb"))
加載:
- import pickle
- filename="nourgalaby_posts"
- myposts=pickle.load(file=open(filename))
按點贊數排序
現在我們得到了一個名稱為“myposts”的有序字典。要實現根據字典中的某個鍵值排序,我們可以使用Lambda表達式,代碼如下:
- myposts_sorted = sorted(myposts, key=lambda k:
- k['like_count'],reverse=True)
- top_posts=myposts_sorted[:10]
- bottom_posts=myposts_sorted[-10:]
如下代碼可以實現和上面一樣的顯示:
- image_urls=get_images_from_list(top_posts)
- display_images_from_url(image_urls)
過濾圖片
我們可能想要對我們的帖子做一些過濾。例如,可能有的帖子中是視頻,但是我們只想要圖片帖子。我們可以這樣做過濾:
- myposts_photos= filter(lambda k: k['media_type']==1, myposts)
- myposts_vids= filter(lambda k: k['media_type']==2, myposts)
- print len(myposts)
- print len(myposts_photos)
- print len(myposts_vids)
當然,你可以對結果中的任何變量做過濾,發揮你的創造力吧!
通知
- InstagramAPI.getRecentActivity()
- get_recent_activity_response= InstagramAPI.LastJson
- for notifcation in get_recent_activity_response['old_stories']:
- print notifcation['args']['text']
結果可能是:
- userohamed3 liked your post.
- userhacker32 liked your post.
- user22 liked your post.
- userz77 liked your post.
- userwww77 started following you.
- user2222 liked your post.
- user23553 liked your post.
僅來自特定用戶的通知
現在,我們可以按我們的要求操作并玩轉通知。例如,我可以獲得來自于特定用戶的通知列表:
- username="diana"
- for notifcation in get_recent_activity_response['old_stories']:
- text = notifcation['args']['text']
- if username in text:
- print text
讓我們嘗試一些更有意思的操作,例如:得到你被點贊最多的時刻,一天中何時人們點贊最多。要實現這些操作,我們將繪制一個關系圖,顯示一天中的時刻和你所收到點贊數的關系。
下面的代碼繪制了通知的時間日期:
- import pandas as pd
- df = pd.DataFrame({"date":dates})
- df.groupby(df["date"].dt.hour).count().plot(kind="bar",title="Hour" )
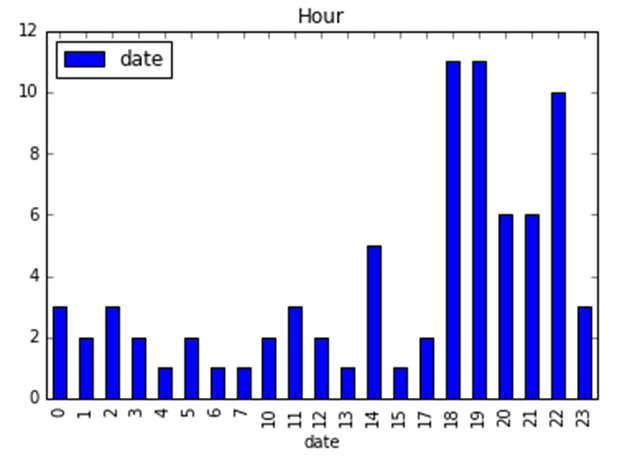
正如在此例中所看到的,我在下午六點到十點間得到的點贊最多。如果你了解社交媒體,你就會知道這是高峰使用時間,大多數企業選取此時間段發帖以獲得最大的認可度。
獲取粉絲和被粉列表
下面我將獲取粉絲和跟帖列表,并在列表上執行一些操作。
要使用getUserFollowings和getUserFollowers這兩個函數,你首先需要取得user_id。下面給出了一種獲取user_id的方式:
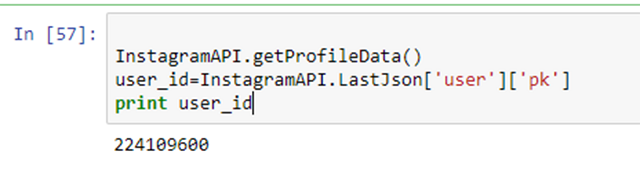
現在你可以如下調用函數。注意,如果粉絲數量非常大,你需要做多次請求(下文將詳細介紹)。現在我們做了一次請求去獲取粉絲和被粉列表。JSON結果中給出了用戶列表,其中包含每個粉絲和被粉者的信息。
- InstagramAPI.getUserFollowings(user_id)
- print len(InstagramAPI.LastJson['users'])
- following_list=InstagramAPI.LastJson['users']
- InstagramAPI.getUserFollowers(user_id)
- print len(InstagramAPI.LastJson['users'])
- followers_list=InstagramAPI.LastJson['users']
如果粉絲數量很大,那么給出的結果可能并非完整列表。
獲得所有的粉絲
獲得所有粉絲列表類似于獲得所有帖子。我們將發出一個請求,然后對結果使用next_max_id鍵值做迭代處理。
在此感謝Francesc Garcia所提供的支持。
- import time
- followers = []
- next_max_id = True
- while next_max_id:
- print next_max_id
- #first iteration hack
- if next_max_id == True: next_max_id=''
- _ = InstagramAPI.getUserFollowers(user_id,maxid=next_max_id)
- followers.extend ( InstagramAPI.LastJson.get('users',[]))
- next_max_id = InstagramAPI.LastJson.get('next_max_id','')
- time.sleep(1)
- followers_list=followers
對于被粉列表也可以同樣做,但是我并不會這樣做,因為就我而言,一次請求就足以獲取我的所有被粉者。
現在我們得到了JSON格式的所有粉絲和被粉者的列表數據。我將轉化該列表為一種對用戶更友好的數據類型,即集合,以方便在數據上做一系列的操作。
我只取其中的“username”鍵值,并在其上使用set()。
- user_list = map(lambda x: x['username'] , following_list)
- following_set= set(user_list)
- print len(following_set)
- user_list = map(lambda x: x['username'] , followers_list)
- followers_set= set(user_list)
- print len(followers_set)
這里我選取了所有用戶名的集合。對“full_name”也可同樣操作,并且結果更為用戶友好。但是結果可能并非唯一,因為一些用戶可能沒有提供全名。
現在我們得到了兩個集合。我們可以做如下操作:
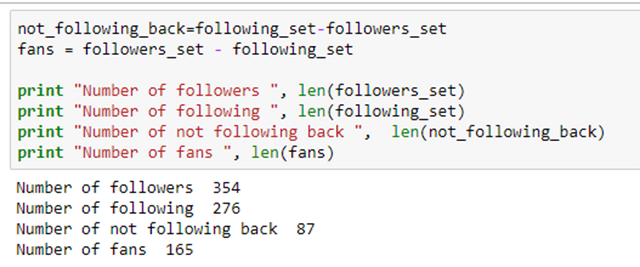
這里我給出了粉絲的一些統計數字。你可以做很多事情,例如保存粉絲列表并稍后做對比,以了解掉粉的情況。
上面我們給出了可對Instagram數據進行的操作。我希望你已經學會了如何使用Instagram API,并具備了一些使用這些API可以做哪些事情的基本想法。敬請關注一下官方API,它們依然在開發中,未來你可以使用它們做更多的事情。如有任何疑問或建議,歡迎聯系我。