從大間隔分類器到核函數:全面理解支持向量機
自從 Statsbot 團隊發表了關于(時間序列的異常檢測(time series anomaly detection)的文章之后,很多讀者要求我們介紹支持向量機方法。因此 Statsbot 團隊將在不使用高深數學的前提下向各位讀者介紹 SVM,并分享有用的程序庫和資源。
如果你曾經使用機器學習執行分類任務,應該會聽說支持向量機(SVM)。這個算法的歷史已經有五十出頭,它們隨著時間不斷在進化,并適應于各種其它問題比如回歸、離群值分析和排序等。
在很多深度學習開發者的模型儲備中,SVM 都是他們的至愛。在 [24]7(https://www.247-inc.com/),我們也將使用它們解決多個問題。
我將更專注于培養直覺理解而不是嚴密的數學推導,這意味著我們會盡可能跳過數學細節而建立其工作方式的理論的直觀理解。
一、分類問題
假設你們的大學開設了一項機器學習課程,課程的講師發現那些擅長數學或者統計學的學生往往表現的***。課程結束之后,老師們記錄了注冊課程的學生的分數,他們對每一個學生根據其在機器學習課程上的表現加上了一個標簽:「好」或者「壞」。
現在,老師們想要確定數學和統計學的得分與機器學習課程表現的關系。或許,根據他們的統計結果,他們會在學生注冊課程時加上一個前提條件限制。
他們會怎么做呢?首先把他們的數據表示出來,我們可以畫一個二維圖,一個坐標軸表示數學成績,另一個表示統計學成績。每個學生的具體成績作為一個點在圖中表示。
點的顏色(綠色或者紅色)表示學生在機器學習課程中的表現:「好」或者「壞」。將圖畫出來的話應該是這樣的:
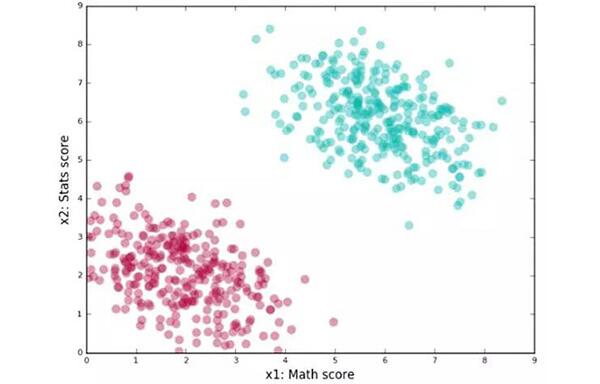
當一個學生要求注冊課程的時候,講師將會要求她提供數學和統計學的成績。根據他們已有的數據,他們將對她在機器學習課程上的表現作出合理的猜測。我們真正想要的是一類以形式(math_score,stats_score)饋送到「分數元組」的算法。這個算法能告訴你一個學生在圖中是以一個紅點還是一個綠點表示(紅/綠可理解為類別或者標簽)。當然,這個算法已經以某種方式包含了訓練數據的特征。
在這個案例中,一個好的算法將能尋找在紅色和綠色群集之間的分界線(即決策邊界),然后確定一個分數多元組將依賴于哪一側。我們選擇綠色方或者紅色方的其中一側作為他在這項課程中最可能的表現水平標簽。

這條線稱為決策邊界(因為它將不同標記的群集分離開來)或者分類器(我們用它來將點集分類)。圖中展示了這個問題中可能的兩個分類器。
二、好分類器和壞分類器
有一個很有趣的問題:以上兩條線都將紅色和綠色的點群集分離開來。有什么合理依據能讓我們選擇其中一個而舍棄另一個嗎?
要注意一個分類器的價值并不在于它能將訓練數據分離的多好。我們最終是希望它能將尚未見過的數據分離(即測試數據)。因此我們需要選擇能捕捉訓練數據的普遍模式的那條線,而這條線更可能在測試數據中表現的更好。
以上所示的***條線看起來有些許偏差,其下半部分看起來過于接近紅點群集,其上半部分過于接近綠點群集。當然它確實很***的將訓練數據分離開來,但是如果在測試數據中遇到了有一個點離群集稍遠的情況,它很有可能會將其加上錯誤的標記。
而第二的點就沒有這樣的問題。例如,下圖為兩個分類器分離方塊點群集的結果展示。

第二條線在正確分離訓練數據的同時也盡可能的遠離兩個群集,即采取***間隔的策略。處于兩個群集的正中間位置能降低犯錯的風險,可以說,這給了每一個類的數據分布更多的浮動空間,因此它能更好的泛化到測試數據中。
SVM 就是試圖尋找第二類決策邊界的算法。上文我們只是通過目測選擇更好的分類器,但實際上為了在一般案例中應用,我們需要將其隱含原理定義地更加精確。以下將簡要說明 SVM 是如何工作的:
- 尋找能準確分離訓練數據的決策邊界;
- 在所有這些決策邊界中選擇能***化與最近鄰點的距離的決策邊界。
那些定義了這條決策邊界的最近鄰點被稱作支持向量。而決策邊界周圍的區域被定義為間隔。下圖展示了支持向量和對應的第二條決策邊界:黑色邊界的點(有兩個)和間隔(陰影區域)。

支持向量機提供了一個方法在多個分類器中尋找能更準確分離測試數據的分類器。雖然上圖中的決策邊界和數據是處于二維空間的,但是必須注意 SVM 實際上能在任何維度的數據中工作,在這些維度中,它們尋找的是和二維空間決策邊界類似的結構。
比如,在三維空間中它們尋找的是一個分離面(后面將簡要提到),在更高維空間中它們尋找的是一個分離超平面,即將二維決策邊界和三維分離面推廣到任意維度的結構。一個可以被決策邊界(或者在普遍意義上,一個分離超平面)被稱作線性可分數據。分離超平面被稱作線性分類器。
三、容錯性和軟間隔分類器
我們在上一節看到的是一個線性可分數據的簡單例子,但現實中的數據通常是很凌亂的。你也很可能經常遇到一些不能正確線性分類的例子。這里展示了一個這樣的例子:

很顯然,使用一個線性分類器通常都無法***的將標簽分離,但我們也不想將其完全拋棄不用,畢竟除了幾個錯點它基本上能很好的解決問題。那么 SVM 會如何處理這個問題呢?SVM 允許你明確規定允許多少個錯點出現。你可以在 SVM 中設定一個參數「C」;從而你可以在兩種結果中權衡:
- 擁有很寬的間隔;
- 精確分離訓練數據;
C 的值越大,意味著在訓練數據中允許的誤差越少。
必需強調一下這是一個權衡的過程。如果想要更好地分類訓練數據,那么代價就是間隔會更寬。以下幾個圖展示了在不同的 C 值中分類器和間隔的變化(未顯示支持向量)。
")
注意決策邊界隨 C 值增大而傾斜的方式。在更大的 C 值中,它嘗試將右下角的紅點盡可能的分離出來。但也許我們并不希望在測試數據中也這么做。***張圖中 C=0.01,看起來更好的抓住了普遍的趨勢,雖然跟更大的 C 值相比,它犧牲了精確性。
考慮到這是一個權衡方法,需要注意間隔如何隨著 C 值的增大而縮小。
在之前的例子中,間隔內是不允許任何錯點的存在的。在這里我們看到,同時擁有好的分離邊界和沒有錯點的間隔是基本不可能的。由于現實世界中的數據幾乎不可能精確的分離,確定一個合適的 C 值很重要且很有實際意義。我們往往使用交叉驗證選擇合適的 C 值。
四、線性不可分數據
我們已經介紹過支持向量機如何處理***或者接近***線性可分數據,那對于那些明確的非線性可分數據,SVM 又是怎么處理的呢?畢竟有很多現實世界的數據都是這一類型的。當然,尋找一個分離超平面已經行不通了,這反而突出了 SVMs 對這種任務有多擅長。
這里有一個關于線性不可分數據的例子(這是著名的異或問題變體),圖中展示了線性分類器 SVM 的結果:

這樣的結果并不怎么樣,在訓練數據中只能得到 75% 的準確率,這是使用決策邊界能得到的***結果。此外,決策邊界和一些數據點過于接近,甚至將一些點分割開來。
現在輪到我最喜歡 SVM 的部分登場了。我們目前擁有:一項擅長尋找分離超平面的技術,以及無法線性分離的數據。那么怎么辦?
當然是,將數據映射到另一個空間中使其線性可分然后尋找分離超平面!我會一步一步的詳細介紹這個想法。
仍然從上圖中的數據集為例,然后將其映射到三維空間中,其中新的坐標為:

下圖中展示了映射數據的表示,你發現了能塞進一個平面的地方了嗎?

讓我們開始在上面運行 SVM:

標簽分離很***,接下來將平面映射回初始的二維空間中看看決策邊界是什么樣子:
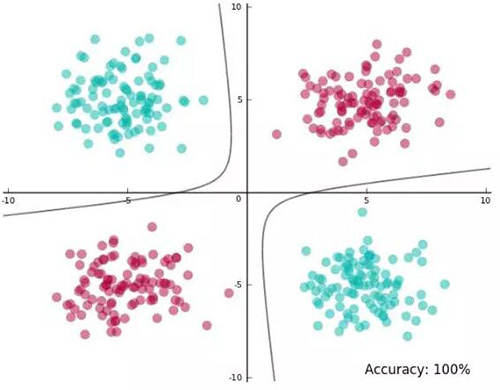
在訓練數據中得到了 100% 的準確率,而且分離邊界并不會過于接近數據點,太棒了!初始空間中決策邊界的形狀依賴于映射函數的形式。在映射空間中,分離邊界通常是一個超平面。
要記住,映射數據的最主要的目的是為了使用 SVM 尋找分離超平面。
當將分離超平面映射回初始空間時,分離邊界不再是一條線了,間隔和支持向量也變得不同。根據視覺直覺,它們在映射空間的形態是很好理解的。
看看它們在映射空間中的樣子,再看看在初始空間。3D 間隔(為了避免視覺混亂,沒有加上陰影)是分離超平面之間的區域。
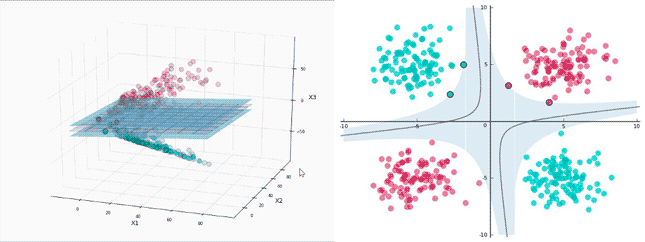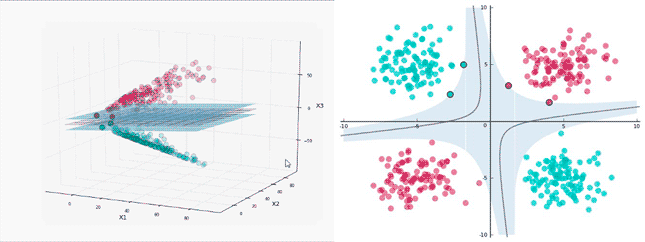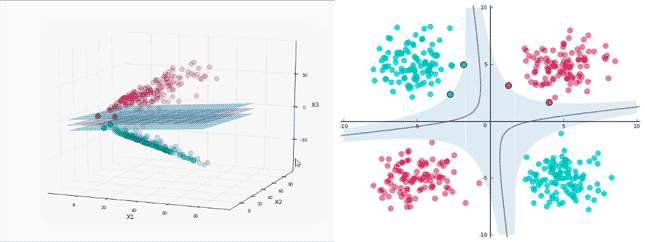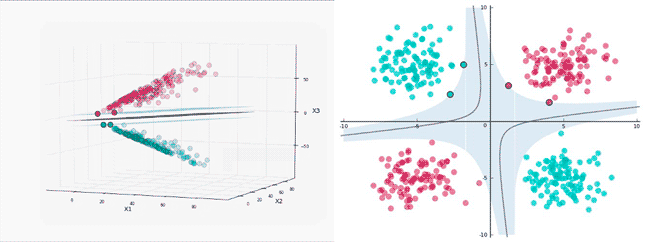
在映射空間中有 4 個支持向量,這很合理,它們分布在兩個平面上以確定間隔。在初始空間中,它們依然在決策邊界上,但是看起來數量并不足以確定***間隔。
讓我們回過頭分析一下:
1. 如何確定要將數據映射到什么樣的空間?
我之前已經很明確的提過,在某個地方出現了根號 2!在這個例子中,我想展示一下向高維空間映射的過程,因此我選了一個很具體的映射。一般而言,這是很難確定的。不過,多虧了 over』s theorem,我們能確定的是通過將數據映射到高維空間確實更可能使數據線性可分。
2. 所以我要做的就是映射數據然后運行 SVM?
不是。為了使上述例子更好理解,我解釋的好像我們需要先將數據映射。如果你自行將數據映射,你要怎么表征無窮維空間呢?看起來 SVMs 很擅長這個,是時候看看算法的核函數了。
五、核函數
最終還是這個獨家秘方才使得 SVM 有了打標簽的能力。在這里我們需要討論一些數學。讓我們盤查一下目前我們所見過的:
- 對于線性可分數據,SVM 工作地非常出色。
- 對于近似線性可分數據,只要只用正確的 C 值,SVM 仍然可以工作地很好。
- 對于線性不可分數據,可以將數據映射到另一個空間使數據變得***或者幾乎***線性可分,將問題回歸到了 1 或者 2。
首先 SVM 一個非常令人驚喜的方面是,其所有使用的數學機制,如精確的映射、甚至是空間的維度都沒有顯式表示出來。你可以根據數據點(以向量表示)的點積將所有的數學寫出來。例如 P 維的向量 i 和 j,***個下標區分數據點,第二個下標表示維度:
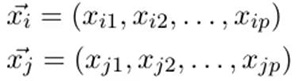
點積的定義如下:
![]()
如果數據集中有 n 個點,SVM 只需要將所有點兩兩配對的點積以尋找分類器。僅此而已。當我們需要將數據映射到高維空間的時候也是這樣,不需要向 SVM 提供準確的映射,而是提供映射空間中所有點兩兩配對的點積。
重提一下我們之前做過的映射,看看能不能找到相關的核函數。同時我們也會跟蹤映射的計算量,然后尋找點積,看看相比之下,核函數是怎么工作的。
對于任意一個點 i:
![]()
其對應的映射點的坐標為:
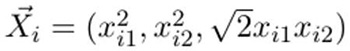
我們需要進行以下操作以完成映射:
- 得到新坐標的***個維度:1 次乘法
- 第二個維度:1 次乘法
- 第三個維度:2 次乘法
加起來總共是 1+1+2=4 次乘法,在新坐標中的點積是:
![]()
為了計算兩個點 i 和 j 的點積,我們需要先計算它們的映射。因此總共是 4+4=8 次乘法,然后點積的計算包含了 3 次乘法和 2 次加法。
- 乘法:8(映射)+3(點積)=11 次乘法
- 加法:2 次(點積之間)
總數為 11+2=13 次計算,而以下這個核函數將給出相同的結果:
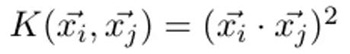
首先在初始空間中計算向量的點積,然后將結果進行平方。把式子展開然后看看是否正確:
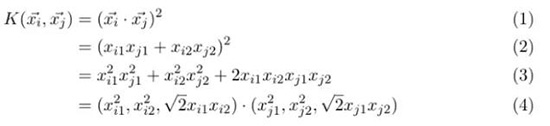
確實是這樣。這個式子需要多少次計算呢?看看以上式子的第二步。在二維空間中計算點積只需要 2 次乘法和 1 次加法,平方運算是另一次乘法。因此,總計為:
- 乘法:2(初始空間的點積)+1(平方運算)=3 次乘法
- 加法:1(初始空間的點積)
總數為 3+1=4 次計算。只有之前計算量的 31%。
看起來使用核函數計算所需要的點積會更快。目前看來這似乎并不是什么重要的選擇:只不過是 4 次和 13 次的比較,但在輸入點處于高維度,而映射空間有更高的維度的情形中,大型數據集的計算所節省的計算量能大大加快訓練的速度。因此使用核函數有相當大的優勢。
大部分 SVM 程序庫已經經過預包裝并包含了一些很受歡迎的核函數比如多項式,徑向基函數(RBF),以及 Sigmoid 函數。當不使用映射的時候(比如文中***個例子),我們就在初始空間中計算點積,我們之前提過,這叫做線性核函數(linear kernel)。很多核函數能提供額外的手段進一步調整數據。比如,多項式核函數:
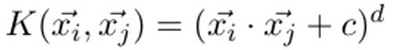
該多項式允許選擇 c 和 d(多項式的自由度)的值。在上述 3D 映射的例子中,我使用的值為 c=0,d=2。但是核函數的優點遠遠不止于此!
還記得我之前提到向無窮維空間映射的情況嗎?只需要知道正確的核函數就可以了。因此,我們并不需要將輸入數據映射,或者困惑無窮維空間的問題。
核函數就是為了計算當數據確實被映射的時候,內積的形式。RBF 核函數通常在一些具體的無窮維映射問題中應用。在這里我們不討論數學細節,但會在文末提到一些參考文獻。
如何在空間維度為無窮的情況計算點積呢?如果你覺得困惑,回想一下無窮序列的加法是如何計算的,相似的道理。雖然在內積中有無窮個項,但是能利用一些公式將它們的和算出來。
這解答了我們前一節中提到的問題。總結一下:
- 我們通常不會為數據定義一個特定的映射,而是從幾個可用的核函數中選擇,在某些例子中需要做一些參數調整,***選出最適合數據的核函數。
- 我們并不需要定義核函數或者自行將數據映射。
- 如果有可用的核函數,使用它將使計算更快。
- RBF 核函數可將數據映射到無窮維空間中。
六、SVM 庫
你可以在很多 SVM 庫中進行選擇,并開始你的實驗:
- libSVM
- SVM—Light
- SVMTorch
很多普適的機器學習庫比如 scikit-learn 也提供 SVM 模塊,通常在專用的 SVM 庫中封裝。我推薦使用經驗證測試可行的 libSVM。
libSVM 通常是一個命令行工具,但下載包通常捆綁封裝了 Python、Java 和 MATLAB。只要將你的數據文件經 libSVM 格式化后(下載文件中 README 將解釋這一部分,以及其它可選項),就可以開始試驗了。
實際上,如果你想快速理解不同核函數和 c 值等如何影響決策邊界,試試登陸「Graphical Interface」的 home page。在上面標記幾類數據點,選擇 SVM 參數,然后運行就可以了。我很快去嘗試了一下:

我給 SVM 出了個難題,然后我嘗試了幾個不同的核函數:
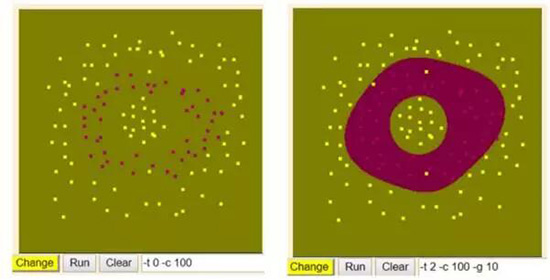
網站界面并沒有展示分離邊界,但會顯示 SVM 判斷分類標簽的結果。正如你所見,線性核函數完全忽略了紅點,認為整個空間中只有黃點。而 RBF 核函數則完整的為紅點劃出了兩個圈!
原文:http://www.kdnuggets.com/2017/08/support-vector-machines-learning-svms-examples.html
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】