一份不可多得的深度學習技巧指南
數據預處理
(本部分原作者沒有寫,以個人的理解及相關補充這部分內容)
What:輸入神經網絡數據的好壞直接關系著網絡訓練結果,一般需要對數據進行預處理,常用的數據預處理方式有:
- 去均值:每個原始數據減去全部數據的均值,即把輸入數據各個維度的數據都中心化到0;
- 歸一化:一種方式是使用去均值后的數據除以標準差,另外一種方式是全部數據都除以數據絕對值的***值;
- PCA/白化:這是另外一種形式的數據預處理方式,一種方式是降維處理,另外一種是進行方差處理;
Why:通過對數據進行預處理能夠使得它們對模型的影響具有同樣的尺度或其他的一些目的。
Ref:CS231n Convolutional Neural Networks for Visual Recognition.
初始化
What:權重若初始化合理能夠提升性能并加快訓練速度,偏置一般設置為0,對于權重而言,建議統一到一定區間內:
- 對于線性層[1]:區間為[-v,v],v = 1/sqrt(輸入尺寸),sqrt表示開根號;
- 對于卷積層[2]:區間為[-v,v],v = 1/sqrt(卷積核的寬度x卷積核的高度x輸入深度);
- 批量標準化[3]在某些方面的應用降低了調整權值初始化的需要,一些研究結果頁提出了相應的替代公式。
Why:使用默認的初始化,每個神經元會隨著輸入數量的增多而存在一個方差,通過求根號縮放每個權重能確保神經元有近似的輸出分布。
Ref:
- 1.Stochastic Gradient Descent Tricks, Leon Bottou;
- 2.在Torch中默認這么操作;
- 3.Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, S. Ioffe and C. Szegedy;
What:對于長短期記憶網絡(LSTM),遺忘偏置一般設置為1,可以加快訓練過程。
Why:直覺是訓練開始時,想要信息在細胞之間傳播,故不希望細胞忘記它的狀態。
Ref:An Empirical Exploration of Recurrent Network Architectures, Rafal Jozefowicz et al.
What:對于t-分布領域嵌入算法(t-SNE),原作者建議對于大小為5000~10000之間的數據集,將困惑度設置為5和50之間[1],對于更大的數據集,相應的困惑度也會增。
Why:困惑度決定了每個點的高斯分布的方差大小,更小的困惑度將獲得更多的集群,大的困惑度與之相反,太大的困惑度沒有任何意義;另外需要考慮的是畫出的聚類不能保留原有的規模,聚類之間的距離不一定代表原始的空間幾何,不同的困惑度能在數據結構上提供互補的信息,每次運行都會產生不同的結果[2]。
Ref:
- 1.Visualizing High-Dimensional Data Using t-SNE, L.J.P. van der Maaten.
- 2.How to Use t-SNE Effectively, Wattenberg, et al., Distill, 2016.
訓練
What:除了使用真值硬化目標外,同樣可以使用軟化目標(softmax輸出)訓練網絡。
Ref:Distilling the Knowledge in a Neural Network / Dark knowledge, G. Hinton et al.
What:學習率可能是需要調參中最重要的一個參數,一種策略是選擇一些參數均有隨機化學習率,并觀察幾次迭代后的測試誤差。
Ref:Some advice for tuning the hyperparameters. Ref: Goodfellow et al 2016 Book
正則化
What:在RNN中使用Dropout,它僅僅應用于非循環連接[1],但是一些最近的文章提出了一些技巧使得Dropout能應用于循環連接[2]。
Ref:
- 1.Recurrent Neural Network Regularization, Wojciech Zaremba et al.
- 2.Recurrent Dropout without Memory Loss, Stanislau Semeniuta et al.
What:批量標準化(Batch Normalization, BN),增添了一個新的層,作者給出一些額外的技巧加速BN層的工作:
- 增大學習率;
- 移除/減少dropout:在不增加過擬合發生的條件下加快訓練;
- 移除/減少L2范數權值歸一化;
- 加快學習率衰減速度:使得網絡訓練更快;
- 移除局部響應歸一化;
- 將訓練樣本打亂地更徹底:防止相同的樣本總出現在小批量中(驗證集上提高了1%);
- 減少光度失真;
Why:一些好的解釋在此。
Ref:Accelerating Deep Network Training by Reducing Internal Covariate Shift, S. Ioffe and C. Szegedy.
網絡結構
What:使用跳躍式連接,直接將中間層連接到輸入/輸出層。
Why:作者的觀點是通過減少神經網絡的底端與頂端之間的處理步驟使得訓練深層網絡更加簡單,并減輕梯度消失問題。
When:在一些CNN結構中或RNN中一些重要的層。
Ref:Generating Sequences With Recurrent Neural Networks, Alex Grave et al.
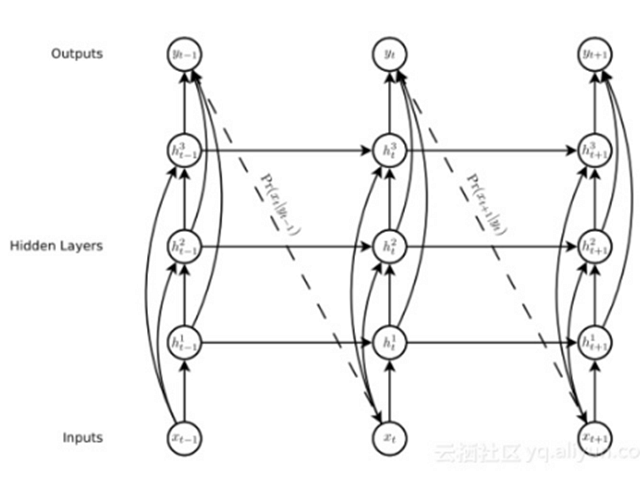
What:為LSTM增加窺視孔連接(連接之前輸出到門的輸入),根據作者的觀點,這個操作對長時間依賴關系有用。
Ref:Learning Precise Timing with LSTM Recurrent Networks, Felix A. Gers et al.
What:大多數的深度學習框架提供了一個結合SoftMax和Log的函數或者是在損失函數中計算SoftMax(在Tensorflow中是softmax_cross_entropy_with_logits,在Torch中是nn.LogSoftMax),這些應該被更好地使用。
Why:Log(SoftMax)在數值上不穩定是小概率,從而導致溢出等不良結果。另外一種流行的方法是在Log中加入一些小數避免不穩定。
自然語言處理(NLP)
What:對于RNN和seq2seq模型的一些技巧:
- 嵌入尺寸:1024或620。更小的維度比如256也能導致很好的表現,但是更高的維度不一定導致更好的表現;
- 對于譯碼器而言:LSTM>GRU>Vanilla-RNN;
- 2-4層似乎普遍足夠,但帶有殘差的更深網絡看起來很難收斂,更多去挖掘更多的技巧;
- Resd(密集的殘差連接)>Res(近連接先前層)>無殘差連接;
- 對于編碼器而言:雙向>單向(反向輸入)>單向;
- 注意力(加法)>注意力(乘法)>無注意力;
- 使用光束會導致更好的結果;
Ref:Massive Exploration of Neural Machine Translation Architectures, Denny Britz, Anna Goldie et al.
What:對于seq2seq而言,翻轉輸入序列的順序,保持目標序列的完整。
Why:根據作者的觀點,這種簡單的數據變換極大提升了LSTM的性能。
Ref:Sequence to Sequence Learning with Neural Networks, Ilya Sutskever et al.
What:對于seq2seq而言,為編碼器和譯碼器網絡使用不同的權值。
Ref:Sequence to Sequence Learning with Neural Networks, Ilya Sutskever et al.
What:當訓練時,強制更正譯碼器的輸入;在測試時,使用先前的步驟,這使得訓練在開始時非常高效,Samy等人提出了一種基于模型轉變的改進方法[1]。
Ref:1.Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks, Samy Bengio et al.
What:以無監督的方式訓練一個網絡去預測文本的下一個字符(char-RNN),該網絡將學習一種能用來監督任務的表示(比如情感分析)。
Ref:Learning to Generate Reviews and Discovering Sentiment, Ilya Sutskever et al.
增強學習
What:異步:以不同的勘探政策同時訓練多個代理,提升了魯棒性。
Ref:Asynchronous Methods for Deep Reinforcement Learning, V. Mnih.
What:跳幀:每隔4幀計算一次動作,而不是每幀都計算,對于其它幀,重復這個動作。
Why:在Atari游戲中工作得很好,并且使用這個技巧以大約4倍的速度加快了訓練過程。
Ref:Playing Atari with Deep Reinforcement Learning, V. Mnih.
What:歷史:不是僅僅將當前幀作為輸入,而是將***的幀與輸入疊加,結合間隔為4的跳幀,這意味著我們有一個含t、t-4、t-8及t-12的幀棧。
Why:這允許網絡有一些動量信息。
Ref:Deep Reinforcement Learning with Double Q-learning, V. Mnih.
What:經驗回放:為了避免幀間的相關性,作為一個代理不是更新每一幀,***是在過渡時期的歷史中采樣一些樣本,該思想類似于有監督學習中訓練前打亂數據集。
Ref:Prioritized Experience Replay, Tom Schaul et al.
What:Parallel Advantage Actor Critic(PAAC):通過代理的經驗以及使用一個單一的同步更新模型使得簡化A3C算法成為可能。
Ref:Efficient Parallel Methods for Deep Reinforcement Learning, Alfredo V. Clemente et al.
網絡壓縮
What:在推理中,為了減少層數,通過批量歸一化(BN)層能夠吸收其它的權值。這是因為在測試時批量歸一化進行地是一個簡單的線性縮放。