用Python打造批量下載視頻并能可視化下載進度的炫酷下載器
大家好,我是Python進階者,今天給大家整點好玩的,一起來看看吧~
【一、項目背景】
平時宅在家的我們最愛做的事莫過于追劇了,但是有時候了,網絡原因,可能會讓你無網可上,這個時候那些好看的電視劇和電影自然是無法觀看了,本期我們要講的就是怎樣下載這些視頻。
【二、項目目標】
通過Python程序對所感興趣的視頻進行批量下載,正好小編近期看到一些不錯的視頻,因為想往安卓方向走,但又苦于重新學習太復雜,有沒有簡單點的,之前好像有什么e4a但是要學易語言就放棄了,于是乎在茫茫網絡發現了一個小眾的編程語言---裕語言。好家伙,不說了,趕緊下載,盤它。
【三、項目實施】
采用sublime text 3 編寫程序,先看看效果:
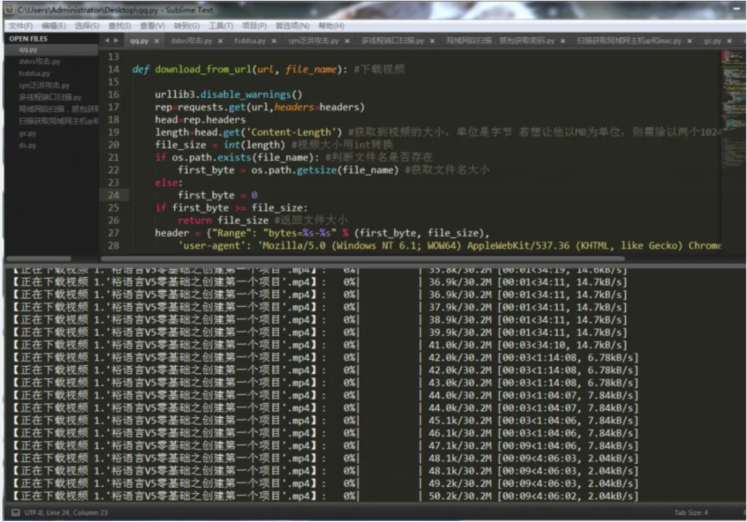
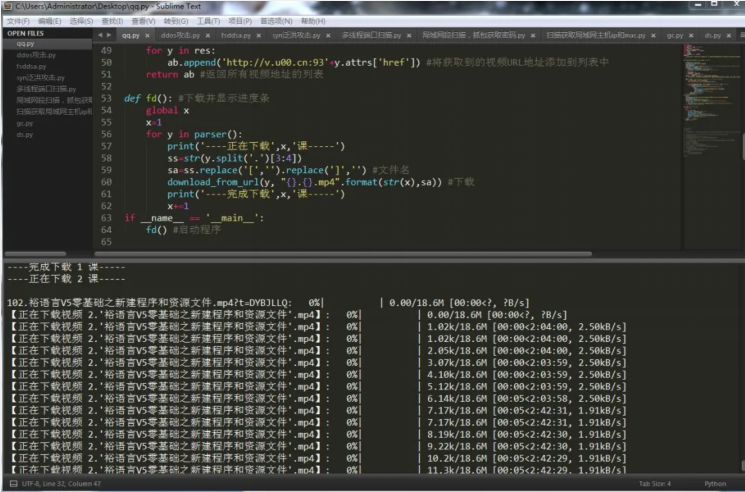
C:\Users\Administrator\Desktop\232.jpg
接下來,由小編我為大家展現程序的具體實現步驟。
【四、實現步驟】
1.分析網頁結構
老樣子,審查元素定位,如下圖:
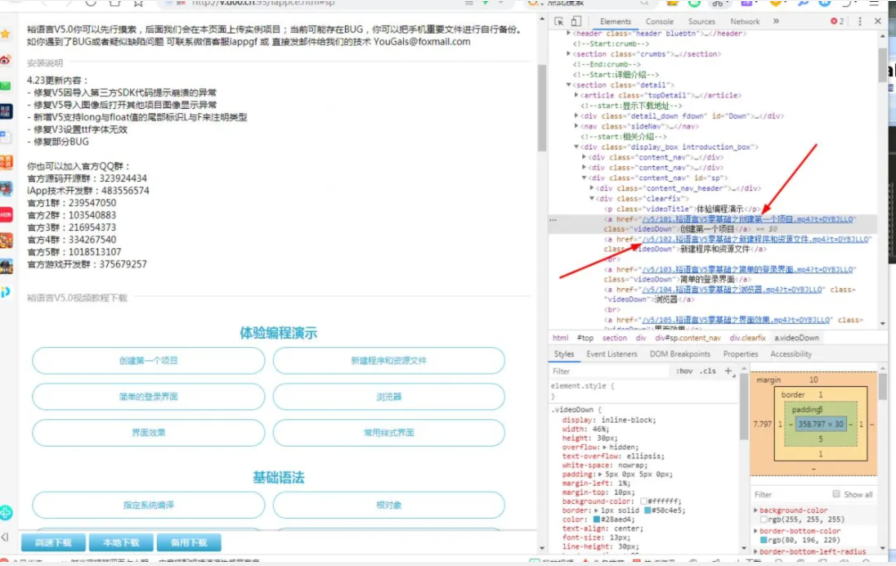
C:\Users\Administrator\Desktop\1212.jpg
發現視頻全都在a標簽里面,因為這個頁面的視頻比較多,所以我們繼續分析頁面,發現一個神奇的事情。哈哈,原來所有的視頻都在class為videoDown的a標簽里,有了這個重要的信息就什么都好辦了。
- #解析頁面
- def parser():
- ab=[]
- rep=requests.get('http://v.u00.cn:93/iappce.htm#sp',timeout=5,headers=headers)
- rep.encoding='utf-8'
- soup=BeautifulSoup(rep.text,'html.parser')
- res=soup.find_all('a',class_='videoDown')#尋找所有class為videoDown的a標簽
- for y in res:
- ab.append('http://v.u00.cn:93'+y.attrs['href'])
- #將獲取到的視頻URL地址添加到列表中
- return ab #返回所有視頻地址的列表
這樣就輕輕松松拿到了頁面所有的視頻地址,怎么樣,是不是超級簡單了。
2.下載文件
因為我們講的是批量下載,所以在此之前需要先了解單個下載,當然,單個下載是很耗費時間,而且系統資源利用率太低。
我們來看看這個下載函數如何實現:
- #下載函數
- def down(y,x):
- print('------下載第',str(x),'課-------')
- ss=str(y.split('.')[3:4]) \#截取文件名
- sa=ss.replace('[','').replace(']','')\#替換文件名中的特殊符號
- ree=requests.get(y)
- with open('%d.%s.mp4'%(x,sa),'wb') as f:
- f.write(ree.content) \#保存文件
無非就是一些常用的字符串分隔以及文件操作罷了,不過此種因為比較單一,下載多個文件就行不通了,所以一般只要不是大批量下載,這種方法就夠了。
然后在給他套一個函數用來簡化他的啟動之路。
- def main():
- for y in range(len(parser())):
- down(parser()[y],y) \#下載
- main()
最后調用主函數main,輕輕松松完成單個文件下載。
3.獲取文件大小并給下載文件添加緩沖
在下載視頻的時候如果我們一下子把所有的資源你都拿出來放進CPU讀取,那么很快就會崩潰,所以我們需要設置一個緩沖,等他緩沖區滿了然后拿出來讀取,聽起來好像挺抽象,讓我們一起來看一下吧。
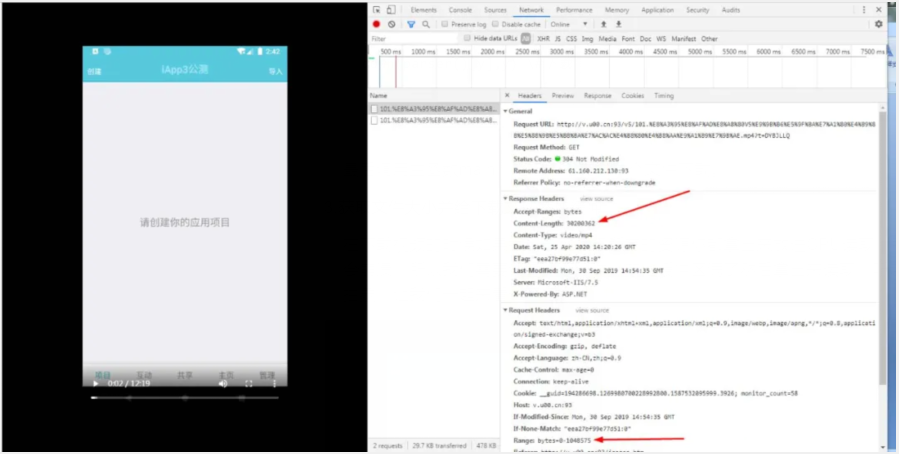
C:\Users\Administrator\Desktop\4343.jpg
圖中所示即為視頻大小值和請求范圍的值。
1.獲取視頻大小
- def download(url, file_name): \#下載視頻
- urllib3.disable_warnings()
- rep=requests.get(url,headers=headers)
- head=rep.headers
- rep=requests.get(url,headers=headers)
- head=rep.headers \#獲取請求頭字典
- length=head.get('Content-Length') \#獲取到視頻的大小,單位是字節
- 若想讓他以MB為單位,則需除以兩個1024
- file_size = int(length) \#視頻大小用int轉換
- if os.path.exists(file_name): \#判斷文件名是否存在
- first_byte = os.path.getsize(file_name) \#獲取文件名大小
- else:
- first_byte = 0
- if first_byte \>= file_size:
- return file_size \#返回文件大小
- header = {"Range": "bytes=%s-%s" % (first_byte, file_size),
- 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36
- (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
- } \#設置請求頭,標明請求范圍
2.配置進度條
- pbar = tqdm( \#配置進度條模塊,設置文件大小,文件字節數,文件的進度
- total=file_size, initial=first_byte,
- unit='B', unit_scale=True, desc=url.split('/')[-1])
- #關于tqdm 具體用法大家可以百度tqdm模塊。
3.添加緩沖
- with closing(requests.get(url, headers=header, stream=True)) as req:
- #關閉連接
- with open(file_name,'wb') as f: \#打開文件
- for chunk in req.iter_content(chunk_size=1024\*2): \#設置緩沖
- if chunk:
- pbar.set_description("【正在下載視頻 %s】"%str(f.name))
- f.write(chunk) \#寫入文件
- pbar.update(1024) \#更新當前進度條
- pbar.close() \#關閉進度條
- return file_size \#返回文件大小
4.構建下載視頻并顯示進度條函數
- def fd(): \#下載并顯示進度條
- global x
- x=1
- for y in parser():
- print('----正在下載',x,'課-----')
- ss=str(y.split('.')[3:4])
- sa=ss.replace('[','').replace(']','') \#文件名
- download(y, "{}.{}.mp4".format(str(x),sa)) \#下載
- print('----完成下載',x,'課-----')
- x+=1
5.啟動程序
- Fd()
【五.總結】
批量下載視頻文件是一個不可多得的技術,程序寫的并不夠好,比如程序沒有添加多線程,多進程,協程,也沒有異步操作,可能是因為自己比較懶吧,哈哈哈。
不過也挺簡單,多線程就是threading.Thread 順便加鎖 Lock,也可以用多進程multiprocessing中的Process或者進程池Pool,或者協程genvent,或者異步asynic