反爬煩的不行?看看這個神級程序員怎么來破解的!
爬蟲和反爬的對抗一直在進行著… 為了幫助更好的進行爬蟲行為以及反爬, 今天就來介紹一下網頁開發者常用的反爬手段。
1. BAN IP :網頁的運維人員通過分析日志發現最近某一個IP訪問量特別特別大,某一段時間內訪問了無數次的網頁,則運維人員判斷此種訪問行為并非正常人的行為,于是直接在服務器上封殺了此人IP。
解決方法:此種方法極其容易誤傷其他正常用戶,因為某一片區域的其他用戶可能有著相同的IP,導致服務器少了許多正常用戶的訪問,所以一般運維人員不會通過此種方法來限制爬蟲。不過面對許多大量的訪問,服務器還是會偶爾把該IP放入黑名單,過一段時間再將其放出來,但我們可以通過分布式爬蟲以及購買代理IP也能很好的解決,只不過爬蟲的成本提高了。
2. BAN USERAGENT :很多的爬蟲請求頭就是默認的一些很明顯的爬蟲頭python-requests/2.18.4,諸如此類,當運維人員發現攜帶有這類headers的數據包,直接拒絕訪問,返回403錯誤
解決方法:直接r=requests.get(url,headers={'User-Agent':'Baiduspider'})把爬蟲請求headers偽裝成百度爬蟲或者其他瀏覽器頭就行了。
案例:雪球網
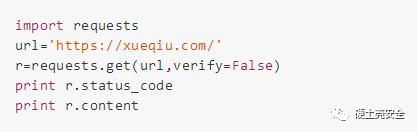
返回的就是
403
403 Forbidden.
Your IP Address: xxx.xxx.xxx.xxx .
但是當我們這樣寫:
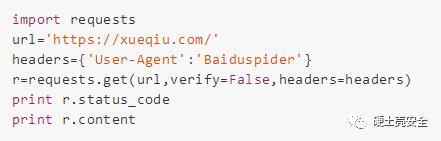
返回的就是
200
< !DOCTYPE html><html …
3. BAN COOKIES :服務器對每一個訪問網頁的人都set-cookie,給其一個cookies,當該cookies訪問超過某一個閥值時就BAN掉該COOKIE,過一段時間再放出來,當然一般爬蟲都是不帶COOKIE進行訪問的,可是網頁上有一部分內容如新浪微博是需要用戶登錄才能查看更多內容。
解決辦法:控制訪問速度,或者某些需要登錄的如新浪微博,在某寶上買多個賬號,生成多個cookies,在每一次訪問時帶上cookies
案例:螞蜂窩
以前因為旅游的需求,所以想到了去抓一點游記來找找哪些地方好玩,于是去了螞蜂窩網站找游記,一篇一篇的看真的很慢,想到不如把所有文章抓過來然后統計每個詞出現的頻率***,統計出最熱的一些旅游景點,就寫了一個scrapy爬蟲抓游記,當修改了headers后開始爬取,發現訪問過快服務器就會斷開掉我的連接,然后過一段時間(幾個小時)才能繼續爬。于是放慢速度抓就發現不會再被BAN了。
4. 驗證碼驗證 :當某一用戶訪問次數過多后,就自動讓請求跳轉到一個驗證碼頁面,只有在輸入正確的驗證碼之后才能繼續訪問網站
解決辦法:python可以通過一些第三方庫如(pytesser,PIL)來對驗證碼進行處理,識別出正確的驗證碼,復雜的驗證碼可以通過機器學習讓爬蟲自動識別復雜驗證碼,讓程序自動識別驗證碼并自動輸入驗證碼繼續抓取
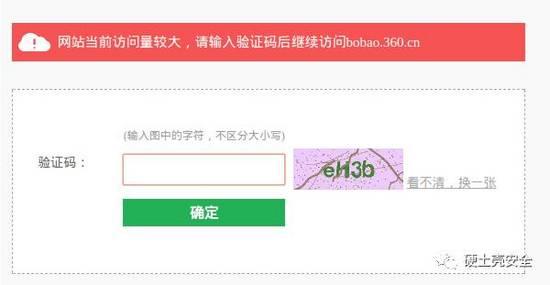
案例:安全客
當訪問者對安全客訪問過快他就會自動蹦出一個驗證碼界面。
如下:
5. javascript渲染 :網頁開發者將重要信息放在網頁中但不寫入html標簽中,而瀏覽器會自動渲染<script>標簽中的js代碼將信息展現在瀏覽器當中,而爬蟲是不具備執行js代碼的能力,所以無法將js事件產生的信息讀取出來
解決辦法:通過分析提取script中的js代碼來通過正則匹配提取信息內容或通過webdriver+phantomjs直接進行無頭瀏覽器渲染網頁。
案例:前程無憂網
隨便打開一個前程無憂工作界面,直接用requests.get對其進行訪問,可以得到一頁的20個左右數據,顯然得到的不全,而用webdriver訪問同樣的頁面可以得到50個完整的工作信息。
6. ajax異步傳輸 :訪問網頁的時候服務器將網頁框架返回給客戶端,在與客戶端交互的過程中通過異步ajax技術傳輸數據包到客戶端,呈現在網頁上,爬蟲直接抓取的話信息為空
解決辦法:通過fiddler或是wireshark抓包分析ajax請求的界面,然后自己通過規律仿造服務器構造一個請求訪問服務器得到返回的真實數據包。
案例:拉勾網
打開拉勾網的某一個工作招聘頁,可以看到許許多多的招聘信息數據,點擊下一頁后發現頁面框架不變化,url地址不變,而其中的每個招聘數據發生了變化,通過chrome開發者工具抓包找到了一個叫請求了一個叫做https://www.lagou.com/zhaopin/Java/2/?filterOption=3的網頁,
打開改網頁發現為第二頁真正的數據源,通過仿造請求可以抓取每一頁的數據。

很多網頁的運維者通過組合以上幾種手段,然后形成一套反爬策略,就像之前碰到過一個復雜網絡傳輸+加速樂+cookies時效的反爬手段。
7. 加速樂 :有些網站使用了加速樂的服務,在訪問之前先判斷客戶端的cookie正不正確。如果不正確,返回521狀態碼,set-cookie并且返回一段js代碼通過瀏覽器執行后又可以生成一個cookie,只有這兩個cookie一起發送給服務器,才會返回正確的網頁內容。
解決辦法 :將瀏覽器返回的js代碼放在一個字符串中,然后利用nodejs對這段代碼進行反壓縮,然后對局部的信息進行解密,得到關鍵信息放入下一次訪問請求的頭部中。
案例:加速樂
這樣的一個交互過程僅僅用python的requests庫是解決不了的,經過查閱資料,有兩種解決辦法:
***種將返回的set-cookie獲取到之后再通過腳本執行返回的eval加密的js代碼,將代碼中生成的cookie與之前set-cookie聯合發送給服務器就可以返回正確的內容,即狀態碼從521變成了200。

直接通過這一段就可以獲取返回的一段經過壓縮和加密處理的js代碼
類似于這種:
所以我們需要對代碼進行處理,讓其格式化輸出,操作之后如下:
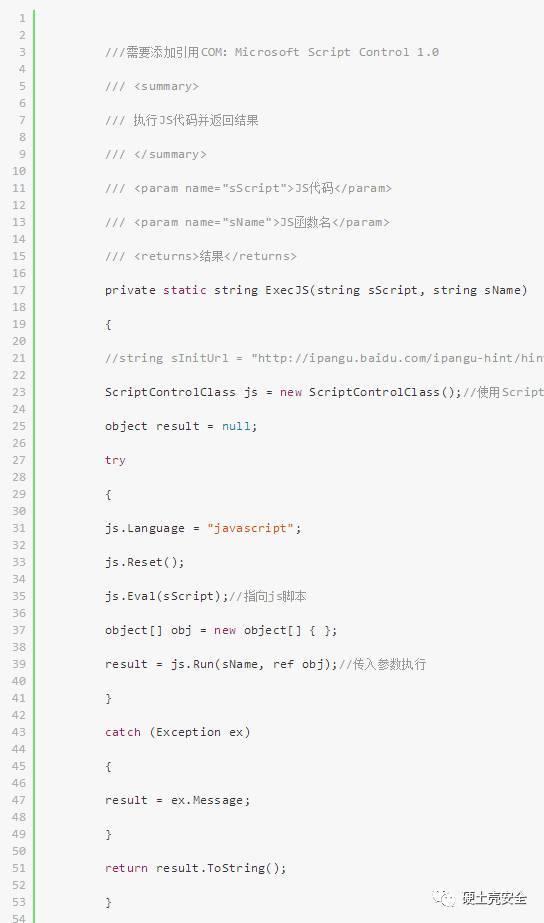
這里我們就需要對這段JS做下修改,假設我們先把這段JS代碼存在了string sHtmlJs這個字符串變量里,我們需要把eval這里執行的結果提取出來,把eval替換成 return,然后把整個代碼放到一個JS函數里,方式如下:

解密后的代碼如下:

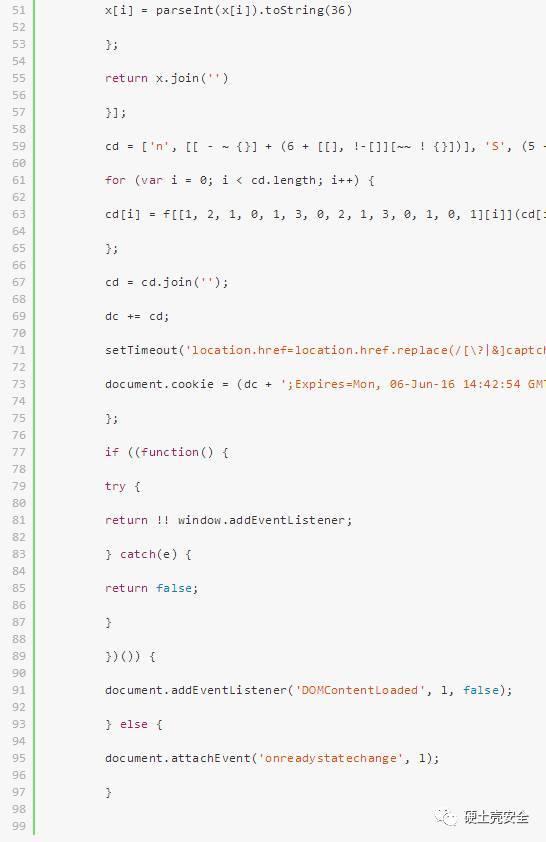
通過觀察代碼發現了一段:
顯而易見,這個dc就是我們想要的cookie,執行JS,讓函數返回DC就OK了。
我還發現了其中有一段

當服務器發現瀏覽器的頭部是_phantom或者__phantommas就讓瀏覽器進行死循環,即阻止用selenium操控phantomjs來訪問網頁。
至此兩端加速樂cookie如下:

這個破解方法很麻煩不建議用,所以我想出了第二種方法
第二種辦法就是通過selenium的webdriver模塊控制瀏覽器自動訪問網頁然后輸出瀏覽器頭部信息中的cookie,封裝在一個字典中,將其通過requests中的jar模塊轉換成cookiejar放入下一次訪問的request中就可以持續訪問,因為cookie的時效大約一個小時左右。
以下是處理自動生成一個新的有效cookie的代碼:

切記,放在requests中訪問的headers信息一定要和你操控的瀏覽器headers信息一致,因為服務器端也會檢查cookies與headers信息是否一致
最厲害的武功是融會貫通,那么最厲害的反爬策略也就是組合目前有的各種反爬手段,當然也不是無法破解,這就需要我們對各個反爬技術及原理都很清楚,梳理清楚服務器的反爬邏輯,然后再見招拆招,就可以讓我們的爬蟲無孔不入。
謝謝閱讀!