













掌握地球?智能機器帶來的真正風險
作者:Abhimanyu Dubey
翻譯:吳蕾、霍靜、任杰
當人們問我是做什么工作的時候,我總是非常困惑如何回答才好。“人工智能”這個答復吧,我覺得太寬泛了,而“圖像識別”似乎又太專業了。不過呢,還是下面這個問題令我真正抓狂:
人工智能會掌控整個地球嗎?
對于一名從事于機器智能研究的專業人士來說,這個問題太讓我惱火了。我也不想去抱怨懷疑論者,事實上大部分人都覺得人工智能是一種神秘,而且有著無窮無盡陰謀詭計的玩意兒,最終它們會把人類滅絕,因為,它能夠在我們狂看一晚Evan Goldberg編導的電影之后,就預測到下一部我們將觀看的影片將會是《Sausage Party》(《香腸派對》)。
“然而,大多數人并沒有意識到,無論我們認為自己多么有個性,多么特殊,從普遍意義上來看,人們還是遵循一些普遍行為模式的。只要經過足夠多訓練,計算機就可以輕松識別出人們的行為模式。”
因此,機器能推測你喜歡的音樂,或者給你一些手機APP應用的建議,這對機器來說很容易實現。不過,這并不代表所有的預測工作的難度和性質類似,我只是希望大家能理解,這相對于人類的能力來說是一種延伸和拓展。
要想了解時下人工智能領域中哪些技術很厲害,重點在于懂得機器學習做得不錯的兩個主要場景:
- 受控環境
- 監督
我們看到了Google的人工圍棋選手AlphaGo打敗了人類最厲害的圍棋選手,計算機象棋的問題很早以前就已經解決了,而最近又有很多論文在探討Doom游戲比賽中擊敗人類的話題。事實上,在游戲里面,你能夠完全掌控操作環境、能夠實施的行為以及可能產生的結果,這使得建模變得相當容易。而一旦我們能夠將游戲環境進行建模,下一步任務就是模擬和學習。實際上,這些理論早就已經成熟了,正是近年來計算機硬件的發展使大規模機器學習得以實現,才能夠令AlphaGo這類技術在實現層面上獲得重大突破。
監督式受控環境表示對于每一個行為,你能夠估計出可能受到的懲罰,從而能夠有效地從錯誤中積累經驗,而游戲正是這種監督式受控環境的完美表達。還有一個例子就是我們剛才提到的電影預測,可以理解為有一個很大的樣本,里面存在“用戶”和“影片”兩類數據,還有一個給定的用戶選擇模型。通過這些,我們就能進行下一次看什么電影的預測。
在監督式受控環境中,我們知道會得到何種信息,并能夠對類似的信息加以處理。我們可以對這類目標創建“表達法”(representation),在我們需要進行預測的時候,這些“表達法”能夠幫助我們最終確定準確的計算模型。這是通用學習類型中的一個非常狹窄的子類,也是和我們人類差不多的一類智能方式。

圖注:分類器概觀
然而,大部分的人類行為并非監督式的,而是在與環境交互的基礎上建立的邏輯和直覺。人類的基本活動,比如說識別物體,理解物理過程都是時常發生的事情。通常,我們通過與事物的互動能習得很多的新知。
在當前階段,這對于計算機來說還是很難達到的水平。現在如果你要一臺機器能認識所有你給的圖片里面的汽車,你必須告訴機器先去看那些圖片,還得告訴它你的汽車是什么樣子的。當你給機器看了大量汽車圖片時,它就能認出汽車了。這就是監督式學習,在它尚未理解看什么東西的時候,你得教它汽車是什么樣子的。
現在,計算機科學家在努力使這種學習變成幾乎無需監督的,即非監督式學習。最終,我們希望機器能夠理解物體和景象的概念本身,而不需要特地去調教它。
當前大多數研究的重心在于非監督式學習,解決這個問題更加困難。誠然,我們的機器看上去更聰明了,不過大多數都是在監督式受控環境中的情況。首先我們必須能令機器人在非監督的環境下正常工作,然后再考慮系統在非受控的情形下運行,這樣才更為接近人類的智能。
“盡管,現在探討機器滅絕人類,或者是機器人的‘不良企圖’仍為時尚早。然而,人工智能更嚴峻的威脅正悄然逼近,這可能造成極其嚴重的后果”。

早先通過觀察特定的特性的算法稱為決策樹分割數據
在這個會議的最初討論時,我導師曾提到了一個問題,令我第一次真正質疑人工智能的可用性。早期傳統的人工智能技術的算法很容易理解,比如說,我們要造一個機器來測量人的身高和體重,并告訴他們是不是超重了。這個很簡單,我們只需要計算出這個人的體重指數(Body Mass Index, BMI),如果超過了特定閾限,那就是超重。這是人工智能的原型算法。如果我說某人肥胖,這是必須要有合理的判斷的(而不是熊孩子罵人),這個人的BMI確實是落在超重人群的平均BMI范圍里。
現在大多數的機器已經不是這么簡單了,它們采用大量復雜的數據作為輸入(比如高清晰度的圖片),經過非常精細粒度的算法來完成輸出。這樣的話,簡單的閾限或決策樹的方法就不夠用了。漸漸地,系統采用了一套廣為人知的深度學習算法,去識別和學習大量數據,用類似于人類的方式去細化模板。

圖注:典型的深度學習模型。它包含了若干個互相連通傳播信息的神經元(圓圈),這與已發現的人腦運作模式十分相似
這些系統性能非常好,但是學習過程很慢,因為需要很多數據來學習。
“但是,有個問題:一旦它們給了我們結果,不管正確與否,我們并不知道機器是怎么得到這個結果的。”
這個聽起來并不是那么要緊—在開始的時候,在機器學習系統里面,我們有兩種類型的數據—特征和標簽。特征是觀察到的變量,標簽是我們需要預測的。舉個例子,在之前的肥胖癥檢測器中,我們的特征是人的身高和體重,標簽是每個人的超重或者健康指標。為了從圖片中檢測癌癥細胞,特征是若干張器官的圖像,標簽是圖片有沒有癌癥細胞。

癌癥檢測算法會先掃描這組圖片
機器學習算法一般會這樣解決問題,先給每個特征配置權重,相加,最后基于所得的和來做決定。比如,如果你要預測一個蘋果是不是壞了,你會先看蘋果的氣味、顏色,如果觸摸一下那么就還有它的質感,最后大腦會配置給這些特征不同的權重。
假如蘋果爛了,光憑顏色一個特征就可以解決問題了
計算機遵循類似的想法,只不過權重是通過不同的優化算法算出來的。但是,在深度學習中,我們并不確定我們想用哪些具體的特征,更不用說配置權重。所以我們怎么辦?我們讓計算機自己學習選出最好的特征群,把它們用最佳方式組合來做決定,從某種意義上模擬人類大腦的做法。
這個主意給我們帶來驚人的結果—在計算機視覺領域(這個領域研究如何讓計算機理解圖像數據),尤其是隨著高效GPU和新框架的出現,使學習基本的圖像級別的概念變得小菜一碟。但是,要注意的是—我們討論的這些機器通過學習選出的特征,物理意義并不像傳統方法那么直觀。
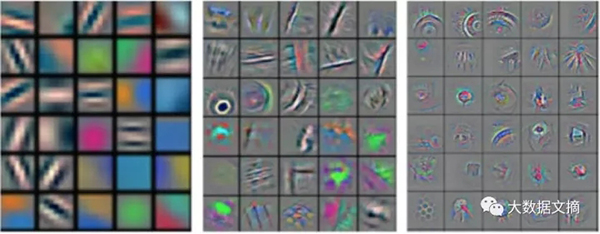
這些例子展示了計算機從圖片中尋找的東西—看上去它們在檢測形狀,但是對于非圖像數據,并不是這么直觀。
大部分人不覺得這是個問題—從技術角度在現階段這并不是一個大問題,因為現在人工智能解決的任務都是具體的,比如從圖片中辨認人物和物體、臉部追蹤以及合成聲音信號。我們大致知道算法在學習什么樣的物體(事實上,這個展示是這個方面的一個最近的發展)。但是,當我們使用深度學習來處理那些有更多風險的預測的時候,每個預測都需要合情合理,可以解釋。
設想你是一家銀行,你有所有客戶詳細的交易信息和信用歷史。你使用一個復雜的深度學習算法來找出拖欠貸款者。既然你已經有了一個大型數據庫囊括用戶的各類行為模式信息,算法解決這個問題可能會給出很高的準確率,但是,一旦你懷疑未來的拖欠者,你并不確切的知道到底是什么引起了懷疑,對于預測的解釋變得非常困難。
大部分的深度學習系統沒有好的技術去理解它們的決策能力,這個也是研究的熱點。對于某些與特定任務相關的深度網絡,尤其在計算機視覺,我們在理解這些系統上已經有了很大的進步—對其較好的定位,理解是什么激發產生了一種算法以及算法是否確實(按照我們的理解)這么做了。但是總的來說,還是有很大的空間需要提高。
機器學習有個很嚴重的缺陷—為了把信號和噪聲分開,需要很多人工處理。或者用專業的話說,過擬合。我說這個專業詞的意思是,當一個模型要擬合一個特定的數據集,用以預測新的未知的數據,它可能對于已知數據擬合的過于完美。所以導致的結果是,當應用于現實世界的時候,它就不會那么準確。
具體來講,模型不是學習在這個世界中確實存在的模式,而是學習已經采集數據集的模式。有幾種方式可以理解過擬合,對于感興趣的人現實中有很多的關于過擬合的例子。一個簡單的例子就是在你居住的地方是夏天,所以你把自己的行李箱裝滿了夏天的衣服,結果在阿姆斯特丹只有11度,你在那里只能冷的瑟瑟發抖。

該圖反映了過擬合的情況,即,最后一幅圖顯然對噪音也進行了擬合
關注過擬合問題的原因是想強調一下機器學習的可解釋性的重要性。如果我們不能理解這些機器學習算法到底學習的是什么,我們并不能判斷它們是不是過擬合了。舉個例子說,某機器算法是根據上網瀏覽歷史來預測可疑的上網行為。因為使用的大部分的訓練數據是來自美國的19歲少年,那么用于預測美國的19歲少年以外的任何個體就會是有偏的,盡管他們的搜索歷史都有PewDiePie (專注恐怖與動作游戲)的視頻。
這個問題的反響會隨著深度學習在推斷任務中的應用增加而迅速加大。比如,我們看到很多研究關于醫療圖像預測 – 這個應用需要更多的可解釋性和可理解性。除此之外,假如預測任務的批量太大不可能去人工檢查預測結果,我們就需要系統來幫我們理解和調整機器學習到底做了什么。
這個威脅剛剛出現,但是這個方面的研究需要更多的時間,來找到更好的解決辦法。但是,我們必須意識到模型可解釋性的重要性,尤其當我們建立模型是為了讓生活變得更好。
我想用一個例子來結尾:如果一個人撞車了,我們可以找出原因,來理解事故是怎么發生的 – 也許司機喝醉了,也許路人正邊端著熱飲邊發短信呢。
但是如果無人駕駛車撞到另外一輛車,致一名乘客死亡,我們去找誰呢?原因又是什么呢?你怎么保證它不會再發生呢?
這些事故最近發生過幾次,隨著更多的人工智能系統的出現,會有更多的失誤發生。為了更好的改正,我們需要理解到底哪里出了問題:這是今天人工智能要面臨的主要挑戰之一。
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】





















