帶你深入理解有效的MongoDB索引
索引是一個擁有自己唯一存儲的對象,它為集合提供了一條快速訪問路徑。索引的存在主要是為了提高性能,因此,在優化MongoDB性能時,有效理解和使用索引是非常重要的。
1、B-樹索引
B-樹索引是MongoDB的默認索引結構。以下是B-樹索引結構高等級的概述。
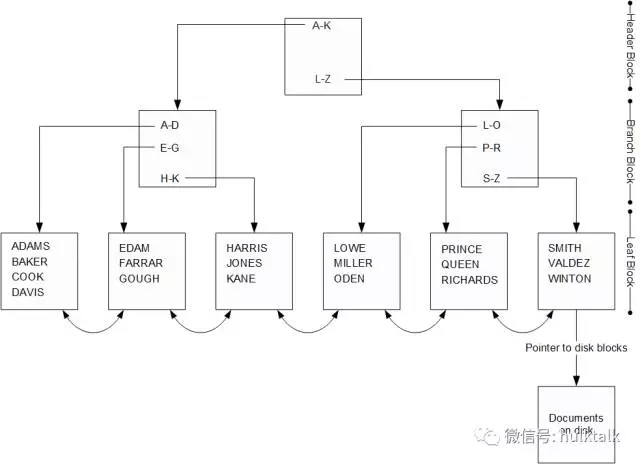
B-樹索引具有分層樹結構。樹頂部是頭部塊。此塊包含指向任何給定范圍的鍵值的適當分支塊的指針。分支塊通常會指向適當的葉子塊以獲得更具體的范圍,或者對于更大的索引,則指向另一個分支塊。 葉子塊包含一個鍵值列表和指向磁盤上文檔位置的指針。
查看上面的圖,讓我們想象一下MongoDB如何遍歷這個索引。 如果我們需要訪問“BAKER”的記錄,我們首先會查閱頭部塊。 頭部塊會告訴我們,從A到K開始的鍵值存儲在最左邊的分支塊中。 訪問這個分支塊,我們發現從A到D開始的鍵值存儲在最左邊的葉子塊中。 咨詢這個葉子塊,我們發現值“BAKER”以及它關聯的磁盤位置,我們將用它來獲得有關的文件。
葉子塊包含前一個和后一個葉子塊的鏈接。 這允許我們以升序或降序掃描索引,并且允許使用$gt或$lt操作符的范圍查詢使用索引進行處理。
與其他索引策略相比,B-樹索引具有以下優點:
- 由于每個葉子節點處于相同的深度,所以性能是非常可預測的。 從理論上講,集合中的任何文檔都不會超過三或四次I/O。
- B樹為大型集合提供了良好的性能,因為深度最多為四個(一個頭部塊,兩個分支塊級別和一個葉子塊級別)。 一般來說,沒有任何文件需要四個以上的I/O來定位。 實際上,因為頭部塊幾乎總是已經加載到內存中,而分支塊通常加載到內存中,所以實際的物理磁盤讀取次數通常只有一次或兩次。
- 因為與前一個和后一個葉子塊的鏈接,所以B-樹索引支持范圍查詢以及精確的查找是可行的。
B-樹索引提供了靈活高效的查詢性能。但是,在更改數據時維護B-樹可能很昂貴。例如,考慮在上面的圖表中插入一個鍵值為“NIVEN”的文檔。要插入集合,我們必須在“L-O”塊中添加一個新條目。如果在這個區域內有空閑空間,那么成本是很大的,但也許不會過多。但是如果塊中沒有可用空間會發生什么?
如果葉子塊中沒有空閑空間用于新條目,則需要索引拆分。必須分配新塊,并將現有塊中的一半條目移入新塊。除此之外,還需要在分支塊中添加一個新條目(以便指向新創建的葉子塊)。如果分支塊中沒有空閑空間,則分支塊也必須分割。
這些索引拆分是一項昂貴的操作:必須分配新塊,并將索引條目從一個塊移到另一個塊。
2、索引選擇性
屬性或屬性組的選擇性是對這些屬性的索引的有用性的常用度量。如果文檔或索引具有大量的唯一值或重復值很少,則它們是有選擇的。例如,DATE_AND_TIME_OF_BIRTH屬性將非常有選擇性,而GENDER屬性將不會被選擇。
選擇性索引比非選擇性索引更有效,因為它們更直接地指向特定的值。MongoDB優化器通常會使用最有選擇性的索引。
3、唯一索引
唯一的索引是阻止組成索引的屬性的任何重復值的索引。如果你嘗試在包含此類重復值的集合上創建唯一索引,則會收到錯誤消息。同樣,如果嘗試插入包含重復唯一索引鍵值的文檔,也會收到錯誤。
通常會創建一個唯一索引,以防止重復值而不是提高性能。 但是,唯一的索引文件通常非常有效 - 它們只能指向一個文件,因此非常有選擇性。
4、連接索引
連接索引只是一個包含多個屬性的索引。連接鍵的優點在于它比單個鍵索引更具有選擇性。屬性的組合將指向比由單個屬性組成的索引更少數量的文檔。包含find()或$match子句中引用的所有屬性的連接索引將特別有效。
如果你經常查詢集合中的多個文檔,那么為這些文檔創建一個連接索引是一個很好的主意。例如,我們可以通過Surname(姓氏)和Firstname(名字)查詢people集合。在這種情況下,我們可能希望在Surname和Firstname上創建一個索引。例如:
- db.people.createIndex({ "Surname":1 ,"Firstname":1} );
使用這樣的索引,我們可以快速找到people中所有匹配給定的Surname \ Firstname 組合。 這樣的索引比單獨的Surname索引或單獨的Surname和Firstname索引要有效得多。
如果連接索引只能在所有鍵出現find()或$match時使用,則連接索引的使用可能會非常有限。幸運的是,連接索引可以非常有效地使用,提供任何初始或主要屬性。主要屬性是在索引定義中最早指定的屬性。
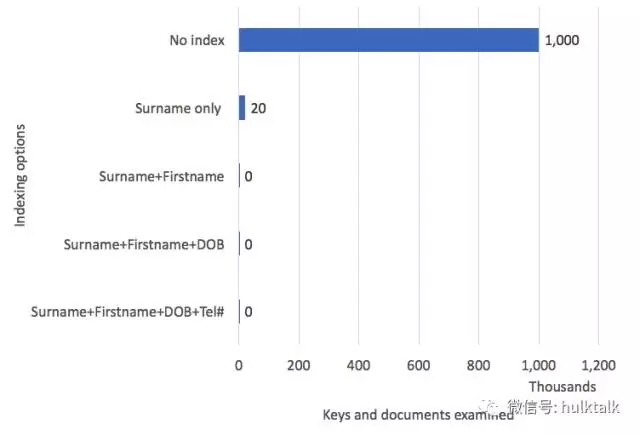
上圖顯示了將屬性添加到連接索引時獲得的改進。涉及的查詢是在一個1,000,000個文檔的people集合上:
- db.people.find(
- { Firstname: "KAREN",
- Surname: "SMITH",
- dob: ISODate("2006-01-21T05:55:32.520Z")
- },
- { _id: 0, tel: 1 }
- );
例如,我們通過提供Surname,Firstname和dob來檢索電話號碼。
全面集合掃描要求我們訪問所有1,000,000個文檔。僅索引surname就減少到20,028個文件 - 實際上是收集中的所有“SMITHS”。添加firstname將文檔數減少到188個。通過添加dob,我們只需可以訪問兩個:訪問一個索引條目并從那里訪問集合以獲取電話號碼。 ***的優化是添加電話號碼tel屬性。 現在我們根本不需要訪問集合 - 我們需要的就是索引。 這有時被稱為“覆蓋”指數。
請注意,覆蓋索引通常要求查詢包含一個投影,以消除索引中包含的屬性以外的所有屬性。
5、連接索引指南
以下指南將有助于確定何時使用連接索引,以及如何確定應包含哪些屬性以及按何種順序。
- 在集合中為find()或$match條件一起出現的屬性創建連接索引。
- 如果屬性有時會以find()或$match的形式出現,請將它們放在索引的開頭。
- 如果連接的索引還支持不是所有屬性都被指定的查詢,則連接索引更有用。 例如,createIndex({"Surname" : 1, "Firstname" : 1})比createIndex({"Firstname" : 1, "Surname" : 1})更有用,因為只針對surname的查詢比僅針對firstname的查詢更有可能發生。
- 屬性越有選擇性,在索引的前端越有用。但是,請注意,WiredTiger索引壓縮可以從根本上縮小索引。當領先的列較少選擇時,索引壓縮更有效。所以如果屬性的順序不是由前面三個考慮因素決定的,你可能不得不嘗試索引順序。
總結
在MongoDB的優化過程中,只有深入理解內部的索引機制,我們才能更好的提升MongoDB的性能。