帶你深入理解Python字符編碼
不論你是有著多年經驗的 Python 老司機還是剛入門 Python 不久,你一定遇到過UnicodeEncodeError、UnicodeDecodeError 錯誤,每當遇到錯誤我們就拿著 encode、decode 函數翻來覆去的轉換,有時試著試著問題就解決了,有時候怎么試都沒轍,只有借用 Google 大神幫忙,但似乎很少去關心問題的本質是什么,下次遇到類似的問題重蹈覆轍,那么你有沒有想過一次性徹底把 Python 字符編碼給搞懂呢?
完全理解字符編碼 與 Python 的淵源前,我們有必要把一些基礎概念弄清楚,雖然有些概念我們每天都在接觸甚至在使用它,但并不一定真正理解它。比如:字節、字符、字符集、字符碼、字符編碼。
字節
字節(Byte)是計算機中數據存儲的基本單元,一字節等于一個8位的比特,計算機中的所有數據,不論是保存在磁盤文件上的還是網絡上傳輸的數據(文字、圖片、視頻、音頻文件)都是由字節組成的。
字符
你正在閱讀的這篇文章就是由很多個字符(Character)構成的,字符一個信息單位,它是各種文字和符號的統稱,比如一個英文字母是一個字符,一個漢字是一個字符,一個標點符號也是一個字符。
字符集
字符集(Character Set)就是某個范圍內字符的集合,不同的字符集規定了字符的個數,比如 ASCII 字符集總共有128個字符,包含了英文字母、阿拉伯數字、標點符號和控制符。而 GB2312 字符集定義了7445個字符,包含了絕大部分漢字字符。
字符碼
字符碼(Code Point)指的是字符集中每個字符的數字編號,例如 ASCII 字符集用 0-127 連續的128個數字分別表示128個字符,例如 "A" 的字符碼編號就是65。
字符編碼
字符編碼(Character Encoding)是將字符集中的字符碼映射為字節流的一種具體實現方案,常見的字符編碼有 ASCII 編碼、UTF-8 編碼、GBK 編碼等。某種意義上來說,字符集與字符編碼有種對應關系,例如 ASCII 字符集對應 有 ASCII 編碼。ASCII 字符編碼規定使用單字節中低位的7個比特去編碼所有的字符。例如"A" 的編號是65,用單字節表示就是0×41,因此寫入存儲設備的時候就是b'01000001'。
編碼、解碼
編碼的過程是將字符轉換成字節流,解碼的過程是將字節流解析為字符。
理解了這些基本的術語概念后,我們就可以開始討論計算機的字符編碼的演進過程了。
從 ASCII 碼說起
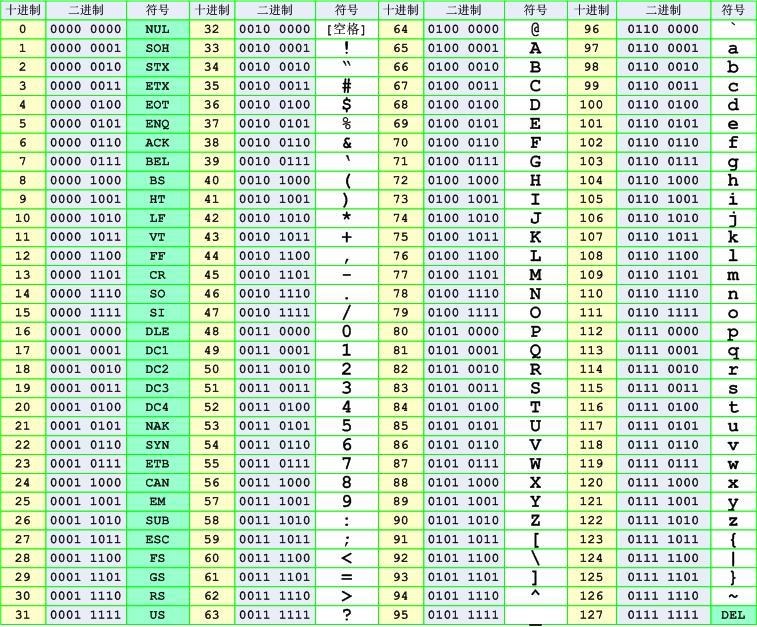
說到字符編碼,要從計算機的誕生開始講起,計算機發明于美國,在英語世界里,常用字符非常有限,26個字母(大小寫)、10個數字、標點符號、控制符,這些字符在計算機中用一個字節的存儲空間來表示綽綽有余,因為一個字節相當于8個比特位,8個比特位可以表示256個符號。于是美國國家標準協會ANSI制定了一套字符編碼的標準叫 ASCII(American Standard Code for Information Interchange),每個字符都對應唯一的一個數字,比如字符 "A" 對應數字是65,"B" 對應 66,以此類推。最早 ASCII 只定義了128個字符編碼,包括96個文字和32個控制符號,一共128個字符只需要一個字節的7位就能表示所有的字符,因此 ASCII 只使用了一個字節的后7位,剩下最高位1比特被用作一些通訊系統的奇偶校驗。下圖就是 ASCII 碼字符編碼的十進制、二進制和字符的對應關系表
擴展的 ASCII:EASCII(ISO/8859-1)
然而計算機慢慢地普及到其他西歐地區時,發現還有很多西歐字符是 ASCII 字符集中沒有的,顯然 ASCII 已經沒法滿足人們的需求了,好在 ASCII 字符只用了字節的7位 0×00~0x7F 共128個字符,于是他們在 ASCII 的基礎上把原來的7位擴充到8位,把0×80-0xFF這后面的128個數字利用起來,叫 EASCII ,它完全兼容ASCII,擴展出來的符號包括表格符號、計算符號、希臘字母和特殊的拉丁符號。然而 EASCII 時代是一個混亂的時代,各個廠家都有自己的想法,大家沒有統一標準,他們各自把最高位按照自己的標準實現了自己的一套字符編碼標準,比較著名的就有 CP437, CP437 是 始祖IBM PC、MS-DOS使用的字符編碼,如下圖:

眾多的 ASCII 擴充字符集之間互不兼容,這樣導致人們無法正常交流,例如200在CP437字符集表示的字符是 È ,在 ISO/8859-1 字符集里面顯示的就是 ╚,于是國際標準化組織(ISO)及國際電工委員會(IEC)聯合制定的一系列8位字符集的標準ISO/8859-1(Latin-1),它繼承了 CP437 字符編碼的128-159之間的字符,所以它是從160開始定義的,ISO-8859-1在 CP437 的基礎上重新定義了 160~255之間的字符。

多字節字符編碼 GBK
ASCII 字符編碼是單字節編碼,計算機進入中國后面臨的一個問題是如何處理漢字,對于拉丁語系國家來說通過擴展最高位,單字節表示所有的字符已經綽綽有余,但是對于亞洲國家來說一個字節就顯得捉襟見肘了。于是中國人自己弄了一套叫 GB2312的雙字節字符編碼,又稱GB0,1981 由中國國家標準總局發布。GB2312 編碼共收錄了6763個漢字,同時他還兼容 ASCII,GB 2312的出現,基本滿足了漢字的計算機處理需要,它所收錄的漢字已經覆蓋中國大陸99.75%的使用頻率,不過 GB2312 還是不能100%滿足中國漢字的需求,對一些罕見的字和繁體字 GB2312 沒法處理,后來就在GB2312的基礎上創建了一種叫 GBK 的編碼,GBK 不僅收錄了27484個漢字,同時還收錄了藏文、蒙文、維吾爾文等主要的少數民族文字。同樣 GBK 也是兼容 ASCII 編碼的,對于英文字符用1個字節來表示,漢字用兩個字節來標識。
Unicode 的問世
GBK僅僅只是解決了我們自己的問題,但是計算機不止是美國人和中國人用啊,還有歐洲、亞洲其他國家的文字諸如日文、韓文全世界各地的文字加起來估計也有好幾十萬,這已經大大超出了ASCII 碼甚至GBK 所能表示的范圍了,雖然各個國家可以制定自己的編碼方案,但是數據在不同國家傳輸就會出現各種各樣的亂碼問題。如果只用一種字符編碼就能表示地球甚至火星上任何一個字符時,問題就迎刃而解了。是它,是它,就是它,我們的小英雄,統一聯盟國際組織提出了Unicode 編碼,Unicode 的學名是"Universal Multiple-Octet Coded Character Set",簡稱為UCS。它為世界上每一種語言的每一個字符定義了一個唯一的字符碼,Unicode 標準使用十六進制數字表示,數字前面加上前綴 U+,比如字母『A』的Unicode編碼是 U+0041,漢字『中』的Unicode 編碼是U+4E2D
Unicode有兩種格式:UCS-2和UCS-4。UCS-2就是用兩個字節編碼,一共16個比特位,這樣理論上最多可以表示65536個字符,不過要表示全世界所有的字符顯示65536個數字還遠遠不過,因為光漢字就有近10萬個,因此Unicode4.0規范定義了一組附加的字符編碼,UCS-4就是用4個字節(實際上只用了31位,最高位必須為0)。理論上完全可以涵蓋一切語言所用的符號。
Unicode 的局限
但是 Unicode 有一定的局限性,一個 Unicode 字符在網絡上傳輸或者最終存儲起來的時候,并不見得每個字符都需要兩個字節,比如字符“A“,用一個字節就可以表示的字符,偏偏還要用兩個字節,顯然太浪費空間了。
第二問題是,一個 Unicode 字符保存到計算機里面時就是一串01數字,那么計算機怎么知道一個2字節的Unicode字符是表示一個2字節的字符呢,例如“漢”字的 Unicode 編碼是 U+6C49,我可以用4個ascii數字來傳輸、保存這個字符;也可以用utf-8編碼的3個連續的字節E6 B1 89來表示它。關鍵在于通信雙方都要認可。因此Unicode編碼有不同的實現方式,比如:UTF-8、UTF-16等等。Unicode就像英語一樣,做為國與國之間交流世界通用的標準,每個國家有自己的語言,他們把標準的英文文檔翻譯成自己國家的文字,這是實現方式,就像utf-8。
具體實現:UTF-8
UTF-8(Unicode Transformation Format)作為 Unicode 的一種實現方式,廣泛應用于互聯網,它是一種變長的字符編碼,可以根據具體情況用1-4個字節來表示一個字符。比如英文字符這些原本就可以用 ASCII 碼表示的字符用UTF-8表示時就只需要一個字節的空間,和 ASCII 是一樣的。對于多字節(n個字節)的字符,第一個字節的前n為都設為1,第n+1位設為0,后面字節的前兩位都設為10。剩下的二進制位全部用該字符的unicode碼填充。
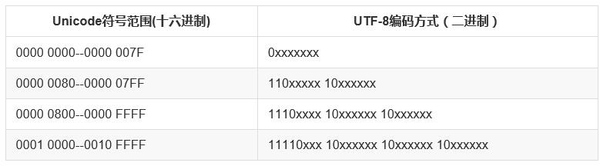
以『好』為例,『好』對應的 Unicode 是597D,對應的區間是 0000 0800--0000 FFFF,因此它用 UTF-8 表示時需要用3個字節來存儲,597D用二進制表示是: 0101100101111101,填充到 1110xxxx 10xxxxxx 10xxxxxx 得到 11100101 10100101 10111101,轉換成16進制是 e5a5bd,因此『好』的 Unicode 碼 U+597D 對應的 UTF-8 編碼是 "E5A5BD"。你可以用 Python 代碼來驗證:
- >>> a = u"好"
- >>> a
- u'\u597d'
- >>> b = a.encode('utf-8')
- >>> len(b)
- 3
- >>> b
- '\xe5\xa5\xbd'
現在總算把理論說完了。再來說說 Python 中的編碼問題。Python 的誕生時間比 Unicode 要早很多,Python2 的默認編碼是ASCII,正因為如此,才導致很多的編碼問題。
- >>> import sys
- >>> sys.getdefaultencoding()
- 'ascii'
所以在 Python2 中,源代碼文件必須顯示地指定編碼類型,否則但凡代碼中出現有中文就會報語法錯誤
- # coding=utf-8
- 或者是:
- # -*- coding: utf-8 -*-
Python2 字符類型
在 python2 中和字符串相關的數據類型有 str 和 unicode 兩種類型,它們繼承自 basestring,而 str 類型的字符串的編碼格式可以是 ascii、utf-8、gbk等任何一種類型。
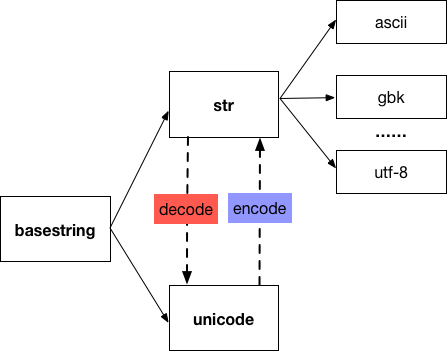
對于漢字『好』,用 str 表示時,它對應的 utf-8 編碼 是'\xe5\xa5\xbd',對應的 gbk 編碼是 '\xba\xc3',而用 unicode 表示時,他對應的符號就是u'\u597d',與u"好" 是等同的。
str 與 unicode 的轉換
在 Python 中 str 和 unicode 之間是如何轉換的呢?這兩種類型的字符串之間的轉換就是靠decode 和 encode 這兩個函數。encode 負責將unicode 編碼成指定的字符編碼,用于存儲到磁盤或傳輸到網絡中。而 decode 方法是根據指定的編碼方式解碼后在應用程序中使用。
- #從unicode轉換到str用 encode
- >>> b = u'好'
- >>> c = b.encode('utf-8')
- >>> type(c)
- <type 'str'>
- >>> c
- '\xe5\xa5\xbd'
- #從str類型轉換到unicode用decode
- >>> d = c.decode('utf-8')
- >>> type(d)
- <type 'unicode'>
- >>> d
- u'\u597d'
UnicodeXXXError 錯誤的原因
在字符編碼轉換操作時,遇到最多的問題就是 UnicodeEncodeError 和 UnicodeDecodeError 錯誤了,這些錯誤的根本原因在于 Python2 默認是使用 ascii 編碼進行 decode 和 encode 操作,例如:
case 1
- >>> s = '你好'
- >>> s.decode()
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
當把 s 轉換成 unicode 類型的字符串時,decode 方法默認使用 ascii 編碼進行解碼,而 ascii 字符集中根本就沒有中文字符『你好』,所以就出現了 UnicodeDecodeError,正確的方式是顯示地指定 UTF-8 字符編碼。
- >>> s.decode('utf-8')
- u'\u4f60\u597d'
同樣地道理,對于 encode 操作,把 unicode字符串轉換成 str類型的字符串時,默認也是使用 ascii 編碼進行編碼轉換的,而 ascii 字符集找不到中文字符『你好』,于是就出現了UnicodeEncodeError 錯誤。
- >>> a = u'你好'
- >>> a.encode()
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
case 2
str 類型與 unicode 類型的字符串混合使用時,str 類型的字符串會隱式地將 str 轉換成 unicode字符串,如果 str字符串是中文字符,那么就會出現UnicodeDecodeError 錯誤,因為 python2 默認會使用 ascii 編碼來進行 decode 操作。
- >>> s = '你好' # str類型
- >>> y = u'python' # unicode類型
- >>> s + y # 隱式轉換,即 s.decode('ascii') + u
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
正確地方式是顯示地指定 UTF-8 字符編碼進行解碼
- >>> s.decode('utf-8') +y
- u'\u4f60\u597dpython'
亂碼
所有出現亂碼的原因都可以歸結為字符經過不同編碼解碼在編碼的過程中使用的編碼格式不一致,比如:
- # encoding: utf-8
- >>> a='好'
- >>> a
- '\xe5\xa5\xbd'
- >>> b=a.decode("utf-8")
- >>> b
- u'\u597d'
- >>> c=b.encode("gbk")
- >>> c
- '\xba\xc3'
- >>> print c
- ��
utf-8編碼的字符‘好’占用3個字節,解碼成Unicode后,如果再用gbk來解碼后,只有2個字節的長度了,最后出現了亂碼的問題,因此防止亂碼的最好方式就是始終堅持使用同一種編碼格式對字符進行編碼和解碼操作。