最近租房有點煩!技術人如何用Python找到稱心如意的“小窩”?
原創【51CTO.com原創稿件】11 月 18 日,北京西紅門鎮新建二村“聚福緣公寓”突發火災。火災后,隨之而來的是一場全北京市的“安全隱患大排查大清理大整治”風暴。
聚集著幾萬外來務工人員的新建村在幾天之內被清理一空。很多人正面臨著要重新找房子或是離開北京的問題。
違建的公寓正在消失,危房出租正在被拆,這些被“風暴”涉及到的外來上班族怎么辦?只有接受現實,勇敢面對。
為了生存,為了能留在帝都,為了改變人生、出人頭地,再貴的房子他們都要租,或者他們可以再尋找一處稍遠點的房子。
租房的煩惱,相信大家或多或少都有過。獨自一人在大都市打拼,找個溫暖的小窩實屬不易,租個稱心又價格公道的房子是件重要的事兒。
站在技術人的角度,今天我就如何從各大租房網的房源里面,找到最稱心如意的小窩做些分享,供大家參考。
在找房子的過程中我們最關心是價格和通勤距離這兩個因素。關于價格方面,現在很多租房網站都有,但是這些租房網站上沒有關于通勤距離的衡量。
對于我這種對帝都不是很熟的人,對各個區域的位置更是一臉懵逼。所以我就想著能不能自己計算距離呢,后來查了查還真可以。
實現思路就是:先抓取房源信息,然后獲取房源的經緯度,***根據經緯度計算公司與具體房源之間的距離。
我們在獲取經緯度之前,首先需要獲取各個出租房所在地的名稱,這里獲取的方法是用爬蟲爬取鏈家網上的信息。
Xpath 介紹
在爬取鏈家網的信息的時候用的是 Xpath 庫,這里對 Xpath 庫做一個簡單的介紹。
Xpath 是什么
Xpath 是一門在 XML 文檔中查找信息的語言。Xpath 可用來在 XML 文檔中對元素和屬性進行遍歷。
Xpath 在查找信息的時候,需要先對 requests.get() 得到的內容進行解析,這里是用 lxml 庫中的 etree.HTML(html) 進行解析得到一個對象 dom_tree,然后利用 dom_tree.Xpath() 方法獲取對應的信息。
Xpath 怎么用
Xpath 最常用的幾個符號就是“/”、“//”這兩個符號,“/”表示該標簽的直接子節點,就比如說一個人的眾多子女,而“//”表示該標簽的后代,就比如說是一個人的眾多后代(包括兒女、外甥、孫子之類的輩分)。

更多詳細內容這里就不 Ctrl C/V了。
數據抓取
我們本次抓取數據的流程是先獲得目標網頁 url,然后利用 requests.get() 獲得 html,然后再利用 lxml 庫中的 etree.HTML(html) 進行解析得到一個對象 dom_tree,然后利用 dom_tree.Xpath() 方法獲取對應的信息。
先分析目標網頁 url 的構造,鏈家網的 url 構造還是很簡單的,頁碼就是 pg 后面的數字,在租房這個欄目下一共有 100 頁,所以我們循環 100 次就好啦。
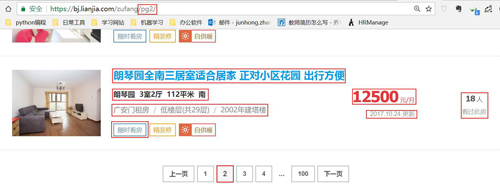
還有就是明確我們要獲取的信息,在前面我們說了目標是要研究公司附近的出租房信息,但是我們在租房的時候也不是僅僅考慮距離這一個因素。
這里我準備獲取標題、價格、區域(大概在哪一塊)、看房人數(說明該房的受歡迎程度),樓層情況(高樓層還是低樓層),房租建筑時間等等。(就是你能看到的信息差不多都要弄下來哈哈)。
開始代碼部分:
- #導入相關庫
- from lxml import etree
- import requests
- from requests.exceptions import ConnectionError
- import pandas as pd
- #獲取目標網頁的url
- def get_page_index():
- base="https://bj.lianjia.com/zufang/pg"
- for i in range(1,101,1):
- url=base+str(i)+"/"
- yield url#yield為列表生成器
得到目標網頁的 url 后,對其進行解析,采用的方法是先用 lxml 庫的 etree 對 response 部分進行解析,然后利用 Xpath 進行信息獲取。
- #請求目標網頁,得到response
- def get_page_detail(url):
- try:
- response=requests.get(url)
- if response.status_code==200:
- return etree.HTML(response.content.decode("utf-8"))
- #lxml.etree.HTML處理網頁源代碼會默認修改編碼
- return None
- except ConnectionError:
- print ("Error occured")
- return None
- #解析目標網頁
- #title為房屋標題;name為小區名稱;catogery為房屋類別(幾室幾廳)
- #size為房屋大小;region為區域;PV為看房人數;
- #second_feature為高低樓層;third_feature為房屋建筑時間
- def parse_page_detail(dom_tree):
- try:
- title=dom_tree.xpath('//li/div[2]/h2/a/text()')
- name=dom_tree.xpath('//li/div[2]//div/a/span/text()')
- catogery=dom_tree.xpath('//li/div[2]//div//span[1]//span/text()')
- size=dom_tree.xpath('//li/div[2]//div//span[2]/text()')
- region=dom_tree.xpath('//li/div[2]//div[1]//div[2]//div/a/text()')
- PV=dom_tree.xpath("//li/div[2]//div[3]//span[@class='num']/text()")
- price=dom_tree.xpath("//li/div[2]//div[2]//span[@class='num']/text()")
- date=dom_tree.xpath("//li/div[2]//div[2]//div[@class='price-pre']/text()")
- first_feature=dom_tree.xpath('//li/div[2]//div[1]//div[3]//span[@class="fang-subway-ex"]/span/text()')
- other=dom_tree.xpath('//li/div[2]//div[1]//div[2]//div/text()')
- name1=[]
- catogery1=[]
- size1=[]
- second_feature=[]
- third_feature=[]
- for n in name:
- name2=n[0:-2]
- name1.append(name2)
- for c in catogery:
- catogery2=c[0:-2]
- catogery1.append(catogery2)
- for s in range(0,59,2):
- size2=size[s][0:-2]
- size1.append(size2)
- second_feature1=other[s]
- second_feature.append(second_feature1)
- for m in range(1,60,2):
- third_feature1=other[m]
- third_feature.append(third_feature1)
- return {
- "title":title,
- "name":name1,
- "catogery":catogery1,
- "size":size1,
- "region":region,
- "price":price,
- "PV":PV,
- "second_feature":second_feature,
- "third_feature":third_feature,
- "other":other
- }
- except:
- pass
- #對獲得目標內容進行整理導出
- #建立一個空的DataFrame
- df1=pd.DataFrame(columns=["title","name","catogery", "size","region","price","PV",
- "second_feature","third_feature","other" ])
- i=0
- if __name__=="__main__":
- urls=get_page_index()
- for url in urls:
- dom_tree=get_page_detail(url)
- result=parse_page_detail(dom_tree)
- df2=pd.DataFrame(result)
- df1=df1.append(df2,ignore_index=False,verify_integrity=False)
- i=i+1
- print(i) #打印出目前爬取的頁數
- #保存數據到本地
- df1.to_csv("D:\\Data-Science\\Exercisedata\\lianjia\\result.csv")
- df1.info#打印出爬蟲結果的基本信息

通過上圖可以看出,我們一共抓取到 2970 條房屋信息,9columns。
- df1.head(3)#預覽前3行

經緯度的獲取
我們剛剛只是獲取了一些出租房的基本信息,但是我們要想計算距離還需要獲得這些出租房所在的地理位置,即經緯度信息。
這里的經緯度是獲取的區域層級的,即大概屬于哪一個片區,本次爬取的 2970 條房屋信息分布在北京的 208 個區域/區域。
關于如何獲取對應地點的經緯度信息,這里利用的 XGeocoding_v2 工具:
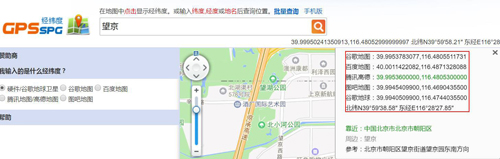
獲取經緯度信息的地址如下:http://www.gpsspg.com/maps.htm
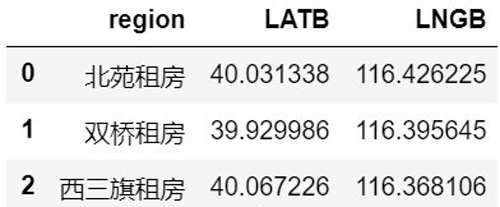
得到如下的結果(LATB 表示維度,LNGB 表示經度):
距離的計算
- #經緯度的計算函數
- # input Lat_A 緯度A
- # input Lng_A 經度A
- # input Lat_B 緯度B
- # input Lng_B 經度B
- # output distance 距離(km)
- def calcDistance(Lat_A, Lng_A, Lat_B, Lng_B):
- ra = 6378.140 # 赤道半徑 (km)
- rb = 6356.755 # 極半徑 (km)
- flatten = (ra - rb) / ra # 地球扁率
- rad_lat_A = radians(Lat_A)
- rad_lng_A = radians(Lng_A)
- rad_lat_B = radians(Lat_B)
- rad_lng_B = radians(Lng_B)
- pA = atan(rb / ra * tan(rad_lat_A))
- pB = atan(rb / ra * tan(rad_lat_B))
- xx = acos(sin(pA) * sin(pB) + cos(pA) * cos(pB) * cos(rad_lng_A - rad_lng_B))
- c1 = (sin(xx) - xx) * (sin(pA) + sin(pB)) ** 2 / cos(xx / 2) ** 2
- c2 = (sin(xx) + xx) * (sin(pA) - sin(pB)) ** 2 / sin(xx / 2) ** 2
- dr = flatten / 8 * (c1 - c2)
- distance = ra * (xx + dr)
- return distance
- #具體的計算
- #Lat_A,Lng_A為你公司地址,這里以望京為例,
- #你可以輸入你公司所在地
- Lat_A=40.0011422082; Lng_A=116.4871328088
- Distance0=[]#用于存放各個區域到公司的距離
- region=[]
- for r in range(0,208,1):
- Lat_B=df3.loc[r][1];Lng_B=df3.loc[r][2]
- distance=calcDistance(Lat_A, Lng_A, Lat_B, Lng_B)
- Distance1='{0:10.3f} km'.format(distance)
- region0=df3.loc[r][0]
- Distance0.append(Distance1);region.append(region0)
- date={"region":region,"Distance":Distance0}
- Distance_result=pd.DataFrame(date,columns=["region","Distance"])
***將距離以及區域與對應的小區拼接在一起,得到下面的結果。

進一步分析
- #導入相關庫
- % matplotlib inline
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- plt.style.use("ggplot")
- #導入合并后的文件
- df=pd.read_csv("D:\\Data-Science\\Exercisedata\\lianjia\\lianjia-rental.csv",encoding="gbk",index_col="name")
- df.head()
- df.info()
通過 df.info() 可以看出,總共有 2454 條數據,這是在爬蟲獲取的 2970 條數據去重以后得到的。

在這些項中,size(房屋面積)、second_feature 以及 third_feature 均帶有單位,為了后續分析方便,這里統一進行去單位(后綴)操作。
- df["size"]=[i[0:-2] for i in df["size"]]
- df["Distance"]=[i[0:-2] for i in df["Distance"]]
- df["second_feature"]=[i[0:3] for i in df["second_feature"]]
- df["third_feature"]=[i[0:4] for i in df["third_feature"]]
- df.head()
- df.info()
我們把后綴去掉了,Size、third_feature 和 Distance 看上去是數字,但是通過 df.info() 看出,這兩個指標類型依然是 Object。為了進一步分析,我們要對它們繼續進行處理。
- df["size"]=df["size"].astype(np.int32)
- df["Distance"]=df["Distance"].astype(np.float64)
- df["price"]=df["price"].astype(np.int32)
- df["third_feature"]=df["third_feature"].astype(np.int32)
- df.info()
再次通過 df.info() 看出,該是數字類型的指標全部變成了 int/float 了,可以進行下一步了。
在文章剛開頭就說過,一般租房最看重的兩個因素就是距離&價格,價格可以直接在那些租房網上看到,肯定是越低越好,沒啥好說的。
主要是距離,關于距離,有兩種選擇方式,一種是先選出離你上班地最近的幾個區域,然后再在該區域內具體選擇;另一個是可以設定你可以接受的通勤距離,然后以這個距離作為條件,在小于等于這個距離內進行篩選。
我們這里著重以***種為主,先選擇距離最近的幾個區域,然后在這幾個區域內進行選擇。
因為距離是按 Region 來進行計算的,而表是按 Name 來統計的,所以要想計算出距離最近的 Region,需要先把 Region 和 Distance 部分提取出來,并合并成一個 DataFrame。
- region=list(df.region)
- Distance=list(df.Distance)
- Distance_result_data={"region":region,"Distance":Distance}
- Distance_result=pd.DataFrame(Distance_result_data)
- Distance_result1=Distance_result.drop_duplicates()
- Distance_result1.head()

- #距離最近的Top10區域
- Distance_result1.sort_values(by="Distance").head(10)
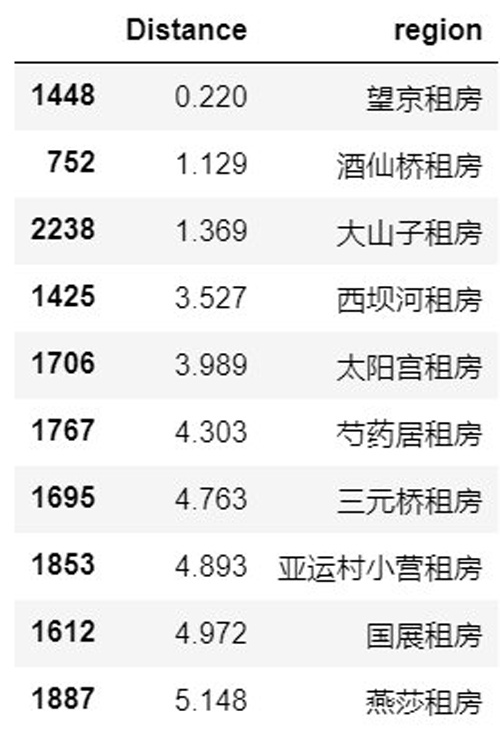
- #對位置進行可視化
- top_region=Distance_result1.sort_values(by="Distance").head(10).region
- top_Distance=Distance_result1.sort_values(by="Distance").head(10).Distance
- #繪制雷達圖
- labels = np.array(top_region)#標簽
- dataLenth = 10#數據個數
- data = np.array(top_Distance)#數據
- angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False)
- data = np.concatenate((data, [data[0]])) # 閉合
- angles = np.concatenate((angles, [angles[0]])) # 閉合
- fig = plt.figure()
- ax = fig.add_subplot(111, polar=True)# polar參數!!
- ax.plot(angles, data, 'ro-', linewidth=2)# 畫線
- #ax.fill(angles, data, facecolor='r', alpha=0.25)# 填充
- ax.set_thetagrids(angles * 180/np.pi, labels, fontproperties="SimHei")
- ax.set_title("距離望京最近的十個區域", va='bottom', fontproperties="SimHei")
- ax.set_rlim(0,6)
- ax.grid(True)
- plt.show()
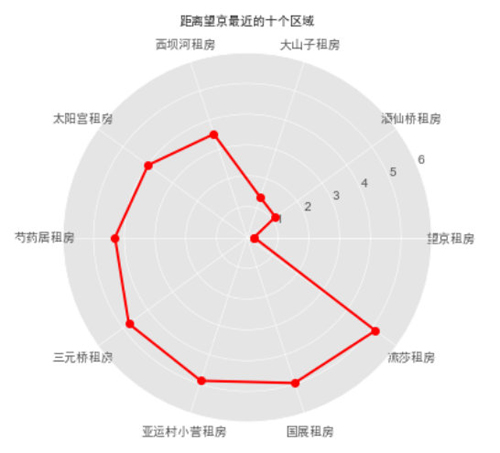
可以看到,Region=“望京”距離最近,所以我們重點在該區域內選擇,接下來具體看看該區域內租房情況。
- Top1=df[df.region=="望京租房"]#將望京的租房信息篩選出來
- Top1.info()

通過上表可以看到在望京區域總共有 101 套房源,接下來對這 101 套房源進行深入分析。
- plt.subplot(131)
- ax1=Top1.boxplot("price")
- ax1.set_ylim(0,90000)
- plt.subplot(132)
- ax2=Top1.boxplot("size")
- ax2.set_ylim(0,270)
- plt.subplot(133)
- ax3=Top1.boxplot("PV")
- ax3.set_ylim(-5,100)
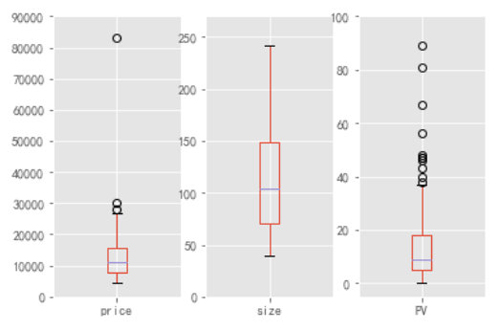
數據概覽,先對該區域的租房整體情況有個認識,看到 Price 指標的下界為 5000 左右,上界接近于 30000,中位數為 10000 出頭(有沒有感覺到好貴哈哈哈哈),但是我們也看到有一個大于 80000 的超級異常值,我們利用截尾均值對他進行替代。
關于房屋大小,中位數為 100 平,這與 Price 中位數正好可以對應,折算下來相當于 1 平 100 大洋,在與那些 10 平左右的合租房需要 2000+ 大洋比一比,是不是覺得還是 100 平 10000 大洋便宜哈。
所以論一平米的價格的話還是整租更便宜。
先找出那個大于 80000 的異常值具體值是多少,然后進行值替換。
- Top1[Top1.price>80000]#通過圖表可以看出,異常值是大于80000,但是看不到具體是多少
![]()
- #值替換
- from scipy import stats
- Top1.price.replace(83000,stats.trim_mean(Top1.price,0.1),inplace=True)
- Top1.boxplot("price")
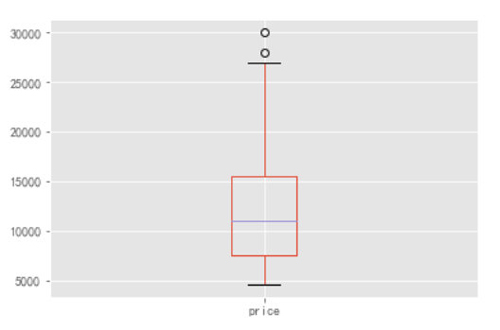
這是將 Price 異常值處理以后得到的箱型圖,看起來就比較規范了哈。
- plt.rcParams["font.sans-serif"]='SimHei'
- plt.subplot(311)
- grouped=Top1.groupby("second_feature")["price"]
- ax4=grouped.count().plot.bar()
- plt.subplot(312)
- grouped2=Top1.groupby("third_feature")["price"]
- ax5=grouped2.count().plot.bar()
- plt.subplot(313)
- grouped3=Top1.groupby("catogery")["price"]
- ax6=grouped3.count().plot.bar()
- plt.tight_layout()
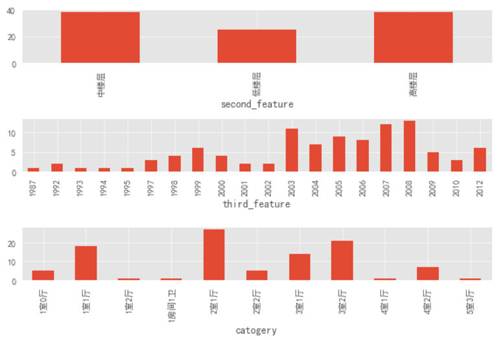
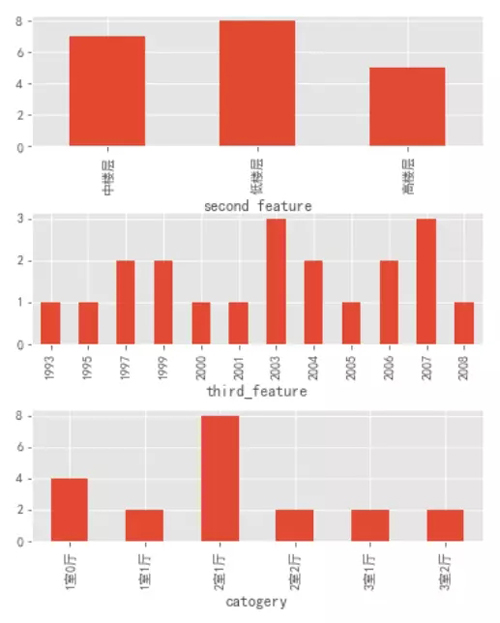
通過上圖可以看出:中樓層和高樓層的房源絕對數量基本持平,高出低樓層數量一半。
房屋修建時間也是 2003 年以后的居多,這就和前面的樓層類型可以對應上了,在剛開始的時候(2003 年以前)大部分房子都是低樓層,隨著時代的進步,科技的發展,人員的增多,樓層的數量和房屋的數量也隨之增加。
房屋類型上的 Top3 類型分別為:2 室 1 廳、3 室 2 廳和 1 室 1 廳。
- #房屋修建時間與價格的散點圖
- Top1.plot.scatter(x="third_feature",y="price")
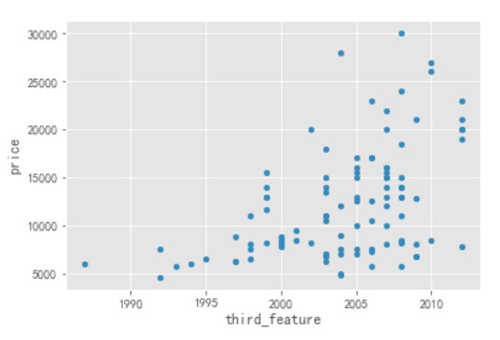
通過上圖可以看出,隨著時間的推移,2003 年以后的房子的 Price 要明顯高于 2003 年以前的,如果要是對價格比較敏感,可以考慮 2003 年以前的房子。
- Top1.boxplot(column=["price"],by="catogery")
- plt.tight_layout()
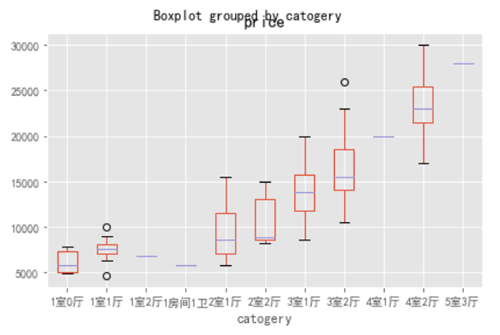
隨著房屋類型的升級,價格也是隨之升高,但是我們也發現,有一些三室房子的價格(下邊界)要低于兩室的價格的,如果對房間數量和價格都有要求的可以考慮這部分房源。
- Top1.boxplot(column=["price"],by="second_feature")
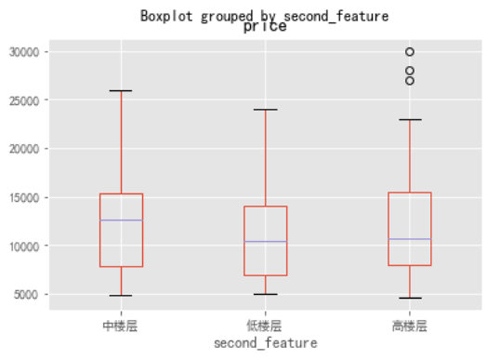
通過上圖可以看到三個樓層的價格下界基本持平,但是中樓層的中位數和上界價格是要明顯高于其他兩個房型的,這也很正常,中樓層相比于其他兩個樓層的房屋是最宜居的啦,價格貴也正常。
當然了,對于現在租房都很困難的環境下,哪還考慮什么宜居,當然是挑價格低的房型。
- Top1_PV=Top1.sort_values(by="PV",ascending=False).head(20)
- Top1_PV.head()
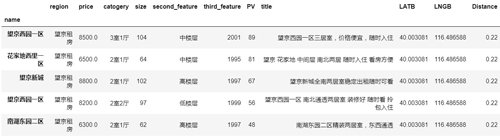
按 PV 進行降序,我們可以看出哪些房源是比較受歡迎,這些房源都有啥特征。
- plt.rcParams["font.sans-serif"]='SimHei'
- plt.subplot(311)
- grouped4=Top1_PV.groupby("second_feature")["price"]
- ax7=grouped4.count().plot.bar()
- plt.subplot(312)
- grouped5=Top1_PV.groupby("third_feature")["price"]
- ax8=grouped5.count().plot.bar()
- plt.subplot(313)
- grouped6=Top1_PV.groupby("catogery")["price"]
- ax9=grouped6.count().plot.bar()
- plt.subplots_adjust(left=0.2,right=1.0,top=1.6,bottom=0.2,hspace=0.5)
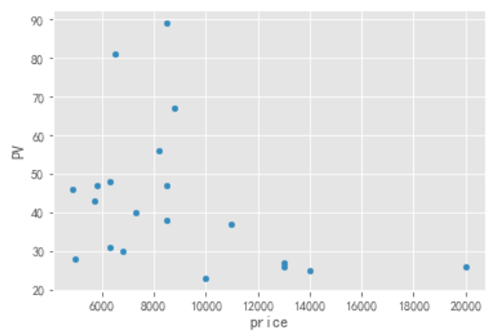
- Top1_PV.plot.scatter(y="PV",x="price")
從圖中可以看到,低樓層的房源數量不是最多的,但是看房次數卻是最多的(***的),可能是低樓層價格低的原因吧。
2003 年和 2007 的房源 PV ***,這和該年代的房源絕對數量基本維持一致;兩室一廳的戶型最為火爆;在價格方面 10000 以下的房源比較受歡迎。
- Top1_PV.plot.scatter(y="PV",x="price")
結論
通過上面的分析我們可以得出一些參考:
- 2003 年以前的房源的價格是要低于 2003 年之后的,對價格敏感的可以考慮 2003 年以前的房源。
- 有一些三室的房子價格是低于兩室的,如果對房間數量和價格都有要求的可以考慮這部分。
- 中樓層的價格整體上是要高于低樓層的,但是還有一部分是要比低樓層低,而且通過從 PV ***的樓層來看,低樓層的火爆程度要比中樓層高,所以可以尋找那些不那么火爆但是價格還低的中樓層。
- 如果希望單位面積價格***,還是整租比較合適。
注:本次的數據為鏈家網的整租房源信息,非合租信息,所以你會看到價格都很高。
張俊紅,中國統計網專欄作者,個人公眾號ID:zhangjunhong0428,數據分析路上的學習者與實踐者,與你分享我的所見、所學、所想。

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】