Python微博移動端爬蟲實例(附代碼)
作者:挖掘機小王子
本文簡要講述用Python爬取微博移動端數據的方法。可以看一下Robots協議。另外盡量不要爬取太快。如果你毫無節制的去爬取別人數據,別人網站當然會反爬越來越嚴厲。至于為什么不爬PC端,原因是移動端較簡單,很適合爬蟲新手入門。有時間再寫PC端吧!
本文簡要講述用Python爬取微博移動端數據的方法。可以看一下Robots協議。另外盡量不要爬取太快。如果你毫無節制的去爬取別人數據,別人網站當然會反爬越來越嚴厲。至于為什么不爬PC端,原因是移動端較簡單,很適合爬蟲新手入門。有時間再寫PC端吧!
環境介紹
Python3/Windows-10-64位/微博移動端
網頁分析
以獲取評論信息為例(你可以以自己的喜好獲得其他數據)。如下圖:
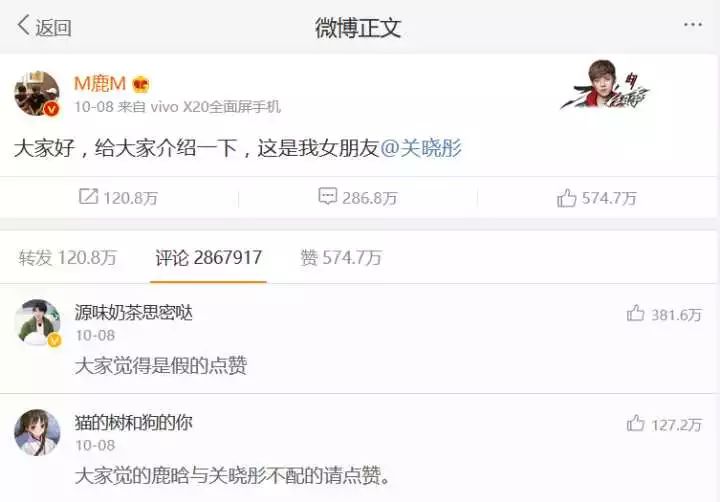
在這里就會涉及到一個動態加載的概念,也就是我們只有向下滑動鼠標滾輪才會加載出更多的評論數據。這也是網頁經常使用的方式。接下來就應該找到評論信息的真實網址,找到真實網址的方法就是打開瀏覽器的開發者工具,火狐/谷歌是F12鍵。打開如下:
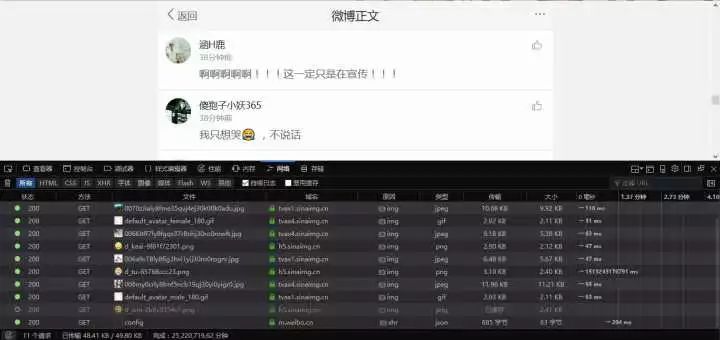
打開以后點擊網絡,網絡用來記錄瀏覽器和服務器交換的信息。接下來將鼠標滾輪緩慢向下滾動,在這個過程中就會彈出類似于上圖的信息,也就是評論信息加載出來了。找到評論信息,應該會在***條。如下圖:
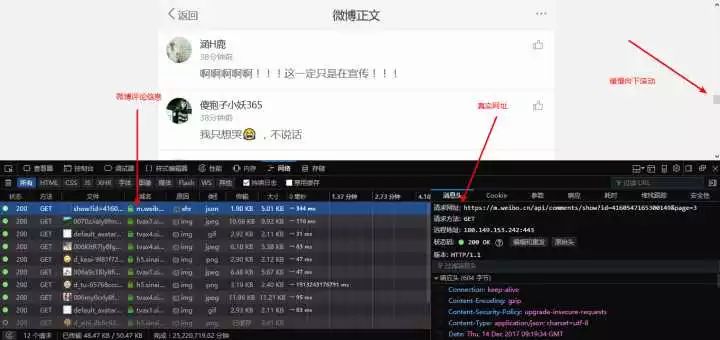
真實網址:https://m.weibo.cn/api/comments/show?id=4160547165300149&page=3
將網址在火狐里面打開如下圖:
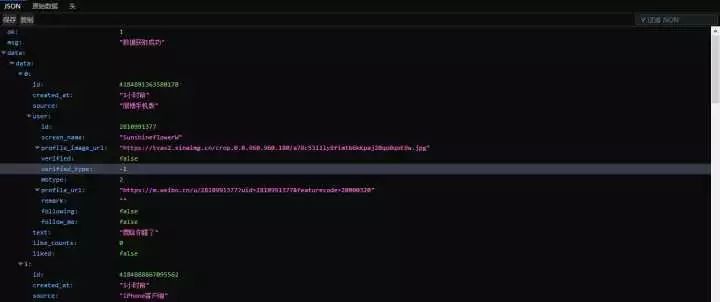
上面的網址其實pages=3就代表第三頁,所以只需模擬網址即可,pages=4,5,6。。。。
另外由于是Json文件,所以提取數據非常方便,只需用切片操作即可。
責任編輯:龐桂玉
來源:
Python中文社區