沒有被了解的API?一個老碼農(nóng)眼中的API世界
即便做了20多年的軟件開發(fā),仍然發(fā)現(xiàn)自己經(jīng)常會低估完成一個特定的編程任務(wù)所需要的時間。有時,錯誤的時間表是由于自己的能力不足造成的:當(dāng)深入研究一個問題時,會發(fā)現(xiàn)它比最初想象的要難得多,因此解決這個問題需要更長的時間ーー這就是程序員的生活。
即使自己清楚地知道想要實現(xiàn)什么以及如何實現(xiàn)它,還會經(jīng)常比預(yù)期的要花費更多的時間,這種情況往往因為與API的糾纏。
目錄
- 1 無所不在,API 的空間視角
- 2 良好與糟糕,API 的真面目
- 3 API 設(shè)計的經(jīng)驗性原則
- 3.1 功能的完整性
- 3.2 調(diào)用的簡單性
- 3.3 設(shè)計的場景化
- 3.4 有無策略性的設(shè)置
- 3.5 面向用戶的設(shè)計
- 3.6 推卸責(zé)任源于無知
- 3.7 清晰的文檔化
- 3.8 API的人體工程學(xué)
- 4 性能約定,API的時間視角
- 4.1 API的性能分類
- 4.2 按性能規(guī)劃API
- 4.3 API的性能變化
- 4.4 API調(diào)用失敗時的性能
- 5 確保API 性能的經(jīng)驗性方法
- 5.1 謹(jǐn)慎地選擇API 和程序結(jié)構(gòu)
- 5.2 在新版本發(fā)布時提供一致的性能約定
- 5.3 防御性編程可以提供幫助
- 5.4 API 公開的參數(shù)調(diào)優(yōu)
- 5.5 測量性能以驗證假設(shè)
- 5.6 使用日志檢測和記錄異常
- 6 面對API,開發(fā)者的苦惱
- 6.1 沒有 API
- 6.2 繁瑣的注冊
- 6.3 多收費的API
- 6.4 隱藏 API 文檔
- 6.5 糟糕的私有協(xié)議
- 6.6 單一的 API 密鑰
- 6.7 手動維護文檔
- 6.8 忽略運維環(huán)境
- 6.9 非冪等性
- 7 API 設(shè)計中的文化認知
- 7.1 API意識的訓(xùn)練
- 7.2 API設(shè)計人才的流失
- 7.3 開放與控制
個人認為,現(xiàn)在所普遍使用的API 與二十年前C語言編寫的API 并沒有本質(zhì)的不同。關(guān)于API的設(shè)計,似乎有些難以捉摸的東西。
API(Application Programming Interface,應(yīng)用編程接口)是一些預(yù)先定義的函數(shù),或軟件系統(tǒng)不同組成部分之間的銜接約定。API 提供了基于軟件或硬件得以訪問一組例程的能力,而無需使用源代碼,也無需理解其內(nèi)部的工作機制。
1 無所不在,API 的空間視角
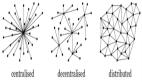
一看到API,很多人首先想到的是Restful API,基于HTTP協(xié)議的網(wǎng)絡(luò)編程接口。實際上, API的概念外延很大,從微觀到宏觀,會發(fā)現(xiàn)API在計算機的世界里無處不在。
拿起顯微鏡,如果Rest API 面向的是網(wǎng)絡(luò)通信,可以想把空間限制在單機上。一臺主機上的IPC同樣由各種各樣的API組成,而一切代碼的執(zhí)行都會歸結(jié)到系統(tǒng)調(diào)用上來,操作系統(tǒng)提供的系統(tǒng)調(diào)用同樣是API。走進操作系統(tǒng),走進函數(shù)指針的API,調(diào)整顯微鏡的鏡頭,API 可能體現(xiàn)在Jump 指令上,在深入就會進入電路與系統(tǒng)的領(lǐng)域了。
抬起望遠鏡,感謝通信與網(wǎng)絡(luò)技術(shù)的發(fā)展,一切軟件都幾乎演變成了分布式系統(tǒng)。API 成為了分布式系統(tǒng)中的血管和關(guān)節(jié),Restful API 只是 RPC的一種。節(jié)點內(nèi)子系統(tǒng)之間的API通信往往形成了東西流量,節(jié)點間子系統(tǒng)之間的API通信形成了南北流量。調(diào)整顯微鏡的鏡頭,這個系統(tǒng)通過開放平臺提供了API,逐漸形成了生態(tài)系統(tǒng)。生態(tài)系統(tǒng)間的異構(gòu)API正在隨著網(wǎng)絡(luò)世界的延伸而形成新的世界。
從空間的視角來看,計算機的世界幾乎就是通過API連接的世界。
2 良好與糟糕,API 的面目
好的 API給我們帶來樂趣,幾乎可以忽略他們的存在,它們能給對一個特定任務(wù)在合理的時間內(nèi)完成,可以很容易地被發(fā)現(xiàn)和記憶,有良好的文檔記錄,有一個直觀的界面使用,并能夠正確處理邊界條件。
然而,對于每一種正確設(shè)計 API 的方法,通常都有幾十種不正確的設(shè)計方法。簡單地說,創(chuàng)建一個糟糕的 API 非常容易,而創(chuàng)建一個好的 API 則比較困難。即使是很小很簡單的設(shè)計缺陷也有被夸大的傾向,因為 API會被多次調(diào)用。設(shè)計缺陷會導(dǎo)致代碼笨拙或效率低下,那么在調(diào)用 API 的每個點都會出現(xiàn)由此產(chǎn)生的問題。此外,一個設(shè)計缺陷在孤立的情況下是微小的,但通過相互作用的方式具有驚人的破壞性,并迅速導(dǎo)致大量的間接傷害。
對于糟糕的 API 設(shè)計,后果眾多且嚴(yán)重,難于編程,通常需要編寫額外的代碼。如果沒有別的原因,這些額外的代碼會使程序變大,效率更低,因為每一行不必要的代碼都會增加工作集合的大小,并可能減少 CPU 緩存的命中率。此外,糟糕的API還可能會強制進行不必要的數(shù)據(jù)復(fù)制,或者對預(yù)期的結(jié)果拋出異常,從本質(zhì)上產(chǎn)生效率低下的代碼。糟糕的API更難理解,也更難使用。面對糟糕的API,程序員編寫代碼的時間會更長,直接導(dǎo)致了開發(fā)成本的增加。
舉個例子,如果一個設(shè)計不當(dāng)?shù)?API 會導(dǎo)致Microsoft PowerPoint常常崩潰的話,那可能會有海量用戶受到影響。類似地,筆者見過的大量安全漏洞都是由標(biāo)準(zhǔn) c 庫(如 strcpy)中不安全的IO操作或者字符串操作造成的。這些設(shè)計缺陷的API,造成的累積成本很容易達到數(shù)十億資金。
從開發(fā)的視角看API的話,大多數(shù)軟件開發(fā)都是關(guān)于不同層次的抽象,而API是這些抽象的可見接口。抽象減少了復(fù)雜性, 應(yīng)用程序調(diào)用較高級別的庫,通常再調(diào)用較低級別的庫提供的服務(wù)來實現(xiàn),而較低級別的庫又調(diào)用操作系統(tǒng)的系統(tǒng)調(diào)用接口提供的服務(wù)。這種抽象層次結(jié)構(gòu)非常強大,沒有它,咱們所知道的軟件就可能不存在,程序員會被復(fù)雜性完全壓垮。
有悖常理的是,抽象層常常被用來淡化糟糕 API 的影響: “這不重要,我們可以編寫一個API來隱藏問題。” 這種說法大錯特錯,首先,就內(nèi)存和執(zhí)行速度而言,即使是效率最高的API封裝也會增加一些成本,其次,本來就是設(shè)計良好的API的份內(nèi)工作, 通常情況下,API 封裝會產(chǎn)生一系列的問題。因此,盡管API的封裝可以是糟糕的API可用,這并不意味著這個糟糕的API無關(guān)緊要,這里沒有“負負得正”,不必要的API封裝只會導(dǎo)致軟件更加臃腫。

3 API 設(shè)計的經(jīng)驗性原則
有些時候,自己新的認知可能只是別人的常識。在設(shè)計 API 的時候,有一些經(jīng)驗性原則可以使用。很遺憾。仍然無法提煉到方法論的高度。
3.1 功能的完整性
API要提供完整的功能,這似乎是顯而易見的,提供不足功能的 API 是不完整的。在設(shè)計過程中仔細檢查一個功能清單,不斷地問自己: “是否有遺漏呢?”
3.2 調(diào)用的簡單性
API 使用的類型、函數(shù)和參數(shù)越少,學(xué)習(xí)、記憶和正確使用就越容易。許多 API最終成為了助手函數(shù)的組合器,C+ + 標(biāo)準(zhǔn)字符串類及其超過100個的成員函數(shù)就是一個例子。在使用 C + + 編程多年之后,自己仍然無法在不查閱使用手冊的情況下使用標(biāo)準(zhǔn)字符串來處理任何重要的事情。
為了很好地設(shè)計 API,設(shè)計人員必須了解使用 API 的環(huán)境,并對該環(huán)境進行設(shè)計。是否提供一個非基本的便利函數(shù)取決于設(shè)計者預(yù)期這個API被使用的頻率。如果頻繁使用,就值得添加。對 API 向下兼容的擔(dān)憂隨著時間的推移而侵蝕 API , API 累積起來最終造成的損害比它保持向后兼容所帶來的好處還要大。
3.3 設(shè)計的場景化
考慮一個類,它提供了對一組字符串鍵值對的訪問,比如環(huán)境變量:
- class KVPairs { public string lookup(string name); // ... }
lookup方法提供了對命名變量值的訪問。顯然,如果設(shè)置了具有給定名稱的變量,函數(shù)將返回其值。但是,如果沒有設(shè)置變量,函數(shù)應(yīng)該如何運行?可能有幾種選擇:
- 拋出 VariableNotSet 異常
- 返回 null
- 返回空字符串
如果預(yù)期查找一個不存在的變量不是一個常見的情況,并且可能視為一個錯誤,那么拋出異常是適當(dāng)?shù)摹.惓仁拐{(diào)用方處理錯誤。另一種情況,調(diào)用者可能查找一個變量,如果沒有則替換一個默認值。如果是這樣的話,拋出異常完全是錯誤的,因為處理異常會破壞正常的控制流,而且比測試 null 或空返回值更困難。
假設(shè)如果沒有設(shè)置變量時不拋出異常,有兩個方式表明查找失敗: 返回 null 或空字符串。哪一個是更合適呢?同樣,答案取決于預(yù)期的場景用例。返回 null 允許調(diào)用者區(qū)分沒有設(shè)置的變量和設(shè)置為空字符串的變量,而返回未設(shè)置的變量的空字符串使得不可能區(qū)分從未設(shè)置的變量和顯式設(shè)置為空字符串的變量。如果認為能夠進行這種區(qū)分很重要,那么返回 null 是必要的; 但是,如果這種區(qū)分不重要,那么最好返回空字符串并且永遠不返回 null。
3.4 有無策略性的設(shè)置
API 設(shè)置策略的程度對其可用性有著深遠的影響 ,只有當(dāng)調(diào)用者對 API 的使用與設(shè)計者預(yù)期的場景相一致時,API 才能最優(yōu)地執(zhí)行。如果對將要使用的 API 場景知之甚少,那么只能保持所有選項的開放性,并允許 API 盡可能廣泛地應(yīng)用。
實際上,什么應(yīng)該是錯誤和什么不應(yīng)該是錯誤之間的界限非常細微,而且錯誤地快速放置這個界限會導(dǎo)致更大的痛苦。對 API 的背景了解得越多,它可以制定的策略就越多。這樣做對調(diào)用方有利,因為它捕獲了錯誤,否則就無法檢測到這些錯誤。通過仔細設(shè)計類型和參數(shù),通常可以在編譯時捕獲錯誤,而不是延遲到運行時。在編譯時捕獲的每個錯誤都減少了一個錯誤,這個錯誤可能會在測試期間或生產(chǎn)環(huán)境中產(chǎn)生額外的成本。
通常情況下,人們對上下文知之甚少,因為 API 是低級的,或者就其本質(zhì)而言,必須在許多不同的上下文中工作。在這種情況下,策略模式往往可以用來取得良好的效果。它允許調(diào)用者提供策略,從而保持設(shè)計的開放性。根據(jù)編程語言的不同,調(diào)用方提供的策略可以使用回調(diào)、虛函數(shù)、代理或模板等來實現(xiàn)。如果 API 提供了合理的缺省值,那么這種外部化的策略可以在不損害可用性和清晰性的情況下帶來更大的靈活性。
3.5 面向用戶的設(shè)計
程序員很容易進入解決問題的模式: 需要什么數(shù)據(jù)結(jié)構(gòu)和算法來完成這項工作,需要什么輸入和輸出來完成這項工作?實現(xiàn)者專注于解決問題,而調(diào)用者的關(guān)注點很快被忘記。
獲得可用 API 的一個好方法是讓調(diào)用者編寫函數(shù)名,并將該API簽名交給程序員來實現(xiàn)。僅這一步就至少消除了一半糟糕的API,如果API的實現(xiàn)者從不使用他們自己的API,這對可用性會造成災(zāi)難性的后果。此外,API 與編程、數(shù)據(jù)結(jié)構(gòu)或算法無關(guān),API 與 GUI 一樣,也是一個用戶界面。使用 API 的用戶是一個程序員,也就是一個人。盡管傾向于認為API是機器接口,但它們不是: 它們是人機接口。
驅(qū)動 api 設(shè)計的不是實現(xiàn)者的需求,這意味著好的 api 是根據(jù)調(diào)用者的需求設(shè)計的,即使這會使實現(xiàn)者的工作變得更加復(fù)雜。
3.6 不推卸責(zé)任
“推卸責(zé)任”的一種方式是害怕設(shè)置策略: “好吧,調(diào)用者可能想要這樣或那樣做,但我不能確定是哪個,所以我會設(shè)置它。” 這種方法的典型結(jié)果是采用五個或十個參數(shù)的函數(shù)。因為設(shè)計者沒有設(shè)置策略,也不清楚 API 應(yīng)該做什么和不應(yīng)該做什么,所以 API 最終的復(fù)雜性遠遠超過了必要的程度。一個好的 API 很清楚它想要實現(xiàn)什么和不想要實現(xiàn)什么,并且不害怕預(yù)先了解它。由此產(chǎn)生的簡單性通常可以彌補功能的輕微損失,特別是如果 API 具有良好的基本操作,可以很容易地組合成更復(fù)雜的操作。
另一種推卸責(zé)任的方式是犧牲可用性來提高效率。性能增益是一種錯覺,因為它使調(diào)用者“干臟活” ,而不是由 API 執(zhí)行。換句話說,可以以零運行時開銷提供更安全的 API。通過僅對 API 內(nèi)部完成的工作進行基準(zhǔn)測試,而不是由調(diào)用方和 API 共同完成的任務(wù) ,設(shè)計人員可以聲稱已經(jīng)創(chuàng)建了性能更好的 API,是缺乏價值的。
即便是內(nèi)核也不是沒有瑕疵,并且偶爾會推卸責(zé)任。某些系統(tǒng)調(diào)用會被中斷,迫使程序員明確處理并手動重啟被中斷的系統(tǒng)調(diào)用,而不是讓內(nèi)核透明地處理。
推卸責(zé)任可以采取許多不同的形式,各種 API 的細節(jié)差別很大。對于設(shè)計者來說,關(guān)鍵的問題是: 有沒有什么可以合理地為調(diào)用者做的事情是我沒有做的?如果有,是否有正當(dāng)理由不這樣做?明確地提出這些問題使得設(shè)計成為一個有意識的過程,而不是“偶然的設(shè)計”。
3.7 清晰的文檔化
API 文檔的一個大問題是,它通常是在 API 實現(xiàn)之后編寫的,而且通常是由實現(xiàn)者編寫的。然而,實現(xiàn)者被實現(xiàn)所污染,并且傾向于簡單地寫下所做的事情。這通常會導(dǎo)致文檔不完整,因為實現(xiàn)人員對 API 太熟悉了,并且假設(shè)有些事情是顯而易見的,而實際上并非如此。更糟糕的是,它經(jīng)常導(dǎo)致API完全忽略重要的用例。另一方面,如果調(diào)用者編寫文檔,調(diào)用者可以從用戶的角度處理問題,不受當(dāng)前實現(xiàn)的影響。這使得 API 更有可能滿足調(diào)用者的需求,并防止許多設(shè)計缺陷的出現(xiàn)。
最不適合編寫文檔的人是API的實現(xiàn)者,最不適合編寫文檔的時間是在實現(xiàn)之后。這樣做會增加接口、實現(xiàn)和文檔都出現(xiàn)問題的可能性。
確保文檔是完整的,特別是關(guān)于錯誤處理的文檔。當(dāng)事情出錯時,API 的行為是其中的一部分,也是事情進展順利時的一部分。文檔是否說明 API 是否維護異常?是否詳細說明了在出錯情況下輸出和輸入輸出參數(shù)的狀態(tài)?是否詳細說明了在錯誤發(fā)生后可能存在的任何副作用?是否為調(diào)用者提供了足夠的信息來理解錯誤?程序員確實需要知道當(dāng)出現(xiàn)錯誤時 API 的行為,并且確實需要獲得詳細的錯誤信息,以便通過編程方式進行處理。
單元測試和系統(tǒng)測試對 API也有影響,因為它們可以發(fā)現(xiàn)以前沒有人想到的東西。測試結(jié)果可以幫助改進文檔,從而改進 API,文檔是 API 的一部分。
3.8 API的人體工程學(xué)
人體工程學(xué)本身就是一個研究領(lǐng)域,也可能是 API 設(shè)計中最難確定的部分之一。關(guān)于這個主題,已經(jīng)有了很多內(nèi)容,例如定義命名約定、代碼布局、文檔樣式等。除了單純的時尚問題,符合人體工程學(xué)的實現(xiàn)良好是困難的,因為它提出了復(fù)雜的認知和心理問題。程序員是人,所以一個程序員認為很好的 API 可能被另一個程序員認為是一般的。
特別是對于大型和復(fù)雜的 api,人機工程學(xué)涉及到一致性的問題。例如,如果一個 API 總是以相同的順序放置特定類型的參數(shù),那么它就更容易使用。類似地,如果API建立命名規(guī)則,將相關(guān)函數(shù)與特定的命名風(fēng)格組合在一起,那么就更容易使用。同時, API 為相關(guān)任務(wù)建立簡單統(tǒng)一的約定并使用統(tǒng)一的錯誤處理。
一致性不僅使事物更容易使用和記憶,而且還可以轉(zhuǎn)移學(xué)習(xí)。轉(zhuǎn)移學(xué)習(xí)不僅在API內(nèi)部很重要,而且在API 之間也很重要。API之間可以采用的概念越多,就越容易掌握所有的概念。實際上,即便是Unix 中的標(biāo)準(zhǔn)IO庫也在許多地方違背了這一思想。例如,read ()和 write ()的系統(tǒng)調(diào)用將文件描述符放在第一個參數(shù)位置,但是標(biāo)準(zhǔn)庫中如 fgets ()和 fputs () ,將流指針放在最后,而 fscanf ()和 fprintf () 又將流指針放在第一個位置。這時候,往往要感謝IDE的代碼補全功能了。
4 性能約定,API的時間視角
在 API 中調(diào)用函數(shù)時,當(dāng)然期望它們能夠正確工作,這種期望可以被稱為調(diào)用方和實現(xiàn)之間的約定。同時,調(diào)用者對這些功能也有性能期望,軟件系統(tǒng)的成功通常也取決于滿足這些期望的 API。因此,除了正確性約定之外,還有性能約定。履行合同通常是隱含的,常常是模糊的,有時是被違反的(由調(diào)用者或執(zhí)行者)。如何改進這方面的 API 設(shè)計和文檔?
當(dāng)今任何重要的軟件系統(tǒng)都依賴于其他人的工作,通過API調(diào)用操作系統(tǒng)和各種軟件包中的函數(shù),從而減少了必須編寫的代碼量。在某些情況下,要把工作外包給遠程服務(wù)器,這些服務(wù)器通過網(wǎng)絡(luò)與你連接。我們既依賴于這些函數(shù)和服務(wù)來實現(xiàn)正確的操作,也依賴于它們的執(zhí)行性能以保證整個系統(tǒng)的性能。在涉及分頁、網(wǎng)絡(luò)延遲、共享資源(如磁盤)等的復(fù)雜系統(tǒng)中,性能必然會有變化。然而,即使是在簡單的設(shè)置中,比如在內(nèi)存中包含所有程序和數(shù)據(jù)的獨立計算機中,當(dāng)一個 API 或操作系統(tǒng)達不到性能預(yù)期時,也是令人沮喪的。
人們習(xí)慣于談?wù)搼?yīng)用程序和 API 實現(xiàn)之間的功能約定。雖然如今的 API 規(guī)范并沒有以一種導(dǎo)致正確性證明的方式明確規(guī)定正確性的標(biāo)準(zhǔn),但是 API 函數(shù)的類型聲明和文本文檔力求對其邏輯行為毫不含糊。然而,API 函數(shù)的意義遠不止正確性。它消耗什么資源,速度有多快?人們常常根據(jù)自己對某個函數(shù)的實現(xiàn)應(yīng)該是什么的判斷做出假設(shè)。遺憾的是,API 文檔沒有提示哪些函數(shù)有性能保證,哪些函數(shù)實際上代價高昂。
更復(fù)雜的是,當(dāng)應(yīng)用程序調(diào)整到 API 的性能特征之后,一個新版本的 API 實現(xiàn)或者一個新的遠程存儲服務(wù)卻削減了軟件系統(tǒng)的整體性能。簡而言之,從時間的視角來看,API的性能契約值得更多關(guān)注。
4.1 API的性能分類
為了實用有效,從計算復(fù)雜度來看,可以對API的性能做一個簡單的分類。
恒定的性能
例如 toupper, isdigit, java.util.HashMap.get等。前兩個函數(shù)總是計算廉價的,通常是內(nèi)聯(lián)表查找。正確大小的哈希表查找應(yīng)該也很快,但是哈希沖突可能會偶爾減慢訪問的速度。
通常的性能
例如fgetc, java.util.HashMap.put等。許多函數(shù)被設(shè)計成大多數(shù)時候都很快,但是偶爾需要調(diào)用更復(fù)雜的代碼; fgetc 必須偶爾讀取一個新的字符緩沖區(qū)。在哈希表中存儲一條新數(shù)據(jù)可能會使該表變滿,以至于會重對表中所有條目進行哈希計算。
java.util.HashMap 在性能約定方面有一個很好的描述: “這個實現(xiàn)為基本操作(get 和 put)提供了常量時間性能,假設(shè)散列函數(shù)將元素正確地分散在存儲桶中。對集合視圖的迭代,需要與 HashMap ‘容量‘成比例的時間...... “。fgetc 的性能取決于底層流的屬性。如果是磁盤文件,那么該函數(shù)通常將從用戶內(nèi)存緩沖區(qū)讀取,而不需要系統(tǒng)調(diào)用,但它必須偶爾調(diào)用操作系統(tǒng)來讀取新的緩沖區(qū)。如果是從鍵盤讀取輸入,那么實現(xiàn)可能會調(diào)用操作系統(tǒng)來讀取每個字符。
程序員建立性能模型是基于經(jīng)驗,而不是規(guī)范,并非所有函數(shù)都有明顯的性能屬性。
可預(yù)期的性能
例如 qsort, regexec等。這些函數(shù)的性能隨其參數(shù)的屬性(例如,要排序數(shù)組的大小或要搜索的字符串的長度)而變化。這些函數(shù)通常是數(shù)據(jù)結(jié)構(gòu)或公共算法實用程序,使用眾所周知的算法,不需要系統(tǒng)調(diào)用。
我們通常可以根據(jù)對底層算法的期望來判斷性能(例如,排序?qū)⒒ㄙM nlogn 的時間)。當(dāng)使用復(fù)雜的數(shù)據(jù)結(jié)構(gòu)(例如 B 樹)或通用集合(在這些地方可能很難確定底層的具體實現(xiàn))時,可能更難估計性能。重要的是,可預(yù)測性只是可能的; regexec 基于它的輸入通常是可預(yù)測的,但是有一些病態(tài)的表達會導(dǎo)致復(fù)雜計算的爆發(fā)。
未知的性能
例如fopen, fseek, pthread_create,很多初始化的函數(shù)以及所有網(wǎng)絡(luò)調(diào)用。這些函數(shù)的性能常常有很大的差異。它們從池(線程、內(nèi)存、磁盤、操作系統(tǒng)對象)分配資源,通常需要對共享操作系統(tǒng)或 IO資源的獨占訪問。通常需要大量的初始化工作, 通過網(wǎng)絡(luò)進行調(diào)用相對于本地訪問總是慢的,這使得合理性能模型的形成變得更加困難。
線程庫是性能問題的簡單標(biāo)志。Posix 標(biāo)準(zhǔn)花了很多年才穩(wěn)定下來,然而如今仍然被性能問題所困擾。線程應(yīng)用程序的可移植性仍然存在風(fēng)險,原因是線程需要與操作系統(tǒng)緊密集成,幾乎所有操作系統(tǒng)(包括 Unix 和 Linux)最初設(shè)計時都沒有考慮到線程; 線程與其他庫的交互,為了使線程安全而導(dǎo)致的性能問題等等。
4.2 按性能劃分API
有些庫提供了執(zhí)行一個函數(shù)的多種方法,通常是因為這些方法的性能差別很大。
大多數(shù)程序員被告知使用庫函數(shù)來獲取每個字符并不是最快的方法,更注重性能的人會讀取一個大型的字符數(shù)組,并使用編程語言中的數(shù)組或指針來操作提取每個字符。在極端情況下,應(yīng)用程序可以將文件頁映射到內(nèi)存頁,以避免將數(shù)據(jù)復(fù)制到數(shù)組中。作為提高性能的副作用是,這些函數(shù)給調(diào)用方帶來了更大的負擔(dān)。例如,獲得緩沖區(qū)算法的正確性,調(diào)用 fseek需要調(diào)整緩沖區(qū)指針和可能的內(nèi)容。
程序員總是被建議避免在程序中過早地進行優(yōu)化,從而推遲修訂,直到更簡單的做法被證明是不滿足要求的。確定性能的唯一方法是測量。程序員通常在編寫完整個程序之后,才會面對性能期望與所交付的實現(xiàn)之間的不匹配。
4.3 API的性能變化
可預(yù)測函數(shù)的性能可以根據(jù)其參數(shù)的屬性進行估計,未知函數(shù)的性能功能也可能因要求它們做什么而有很大的不同。在存儲設(shè)備上打開流所需的時間當(dāng)然取決于底層設(shè)備的訪問時間,或許還取決于數(shù)據(jù)傳輸?shù)乃俾省Mㄟ^網(wǎng)絡(luò)協(xié)議訪問的存儲可能特別昂貴,而且它是變化的。
由于各種原因,一般的函數(shù)隨著時間的推移變得越來越強大。I/O流就是一個很好的例子,根據(jù)打開的流類型(本地磁盤文件、網(wǎng)絡(luò)服務(wù)文件、管道、網(wǎng)絡(luò)流、內(nèi)存中的字符串等) ,調(diào)用打開流在庫和操作系統(tǒng)中調(diào)用不一樣的代碼。隨著IO設(shè)備和文件類型范圍的擴展,性能的差異只會增加。大多數(shù)API的共同生命周期是隨著時間的推移逐步增加功能,從而不可避免地增加了性能變化。
一個很大的變化來源是不同平臺的庫接口之間的差異。當(dāng)然,平臺的底層速度(硬件和操作系統(tǒng))會有所不同,但是庫接口可能會導(dǎo)致 API 內(nèi)函數(shù)的性能或 API 間的性能變化。有些庫(例如那些用于處理線程的庫)的移植性能差異非常大。線程異常可能以極端行為的形式出現(xiàn)ーー極其緩慢的應(yīng)用程序甚至是死鎖。
這些差異是難以建立精確的API性能約定的原因之一。我們往往不需要非常精確地了解性能,但是預(yù)期行為的極端變化可能會導(dǎo)致問題。例如,使用 malloc ()函數(shù)的動態(tài)內(nèi)存分配可以被描述為“通常的性能” ,這將是錯誤的,因為內(nèi)存分配(尤其是 malloc)是程序員開始尋找性能問題時的首要嫌疑之一。作為性能直覺的一部分,如果調(diào)用 malloc 數(shù)以萬計次,特別是為了分配小的固定大小的塊,最好使用 malloc 分配一個更大的內(nèi)存塊,將其分割成固定大小的塊,并管理自己的空閑塊列表。Malloc 的實現(xiàn)多年來一直在努力讓它變得高效,提供虛擬內(nèi)存、線程和非常大的內(nèi)存的系統(tǒng)都對malloc 和free構(gòu)成了挑戰(zhàn),必須權(quán)衡某些使用模式(如內(nèi)存碎片)的效率和弊端。
一些軟件系統(tǒng),如Java,使用自動內(nèi)存分配和垃圾收集來管理空閑存儲。雖然這是一個很大的便利,但是一個關(guān)心性能的程序員必須意識到成本。例如,一個 Java 程序員應(yīng)該盡早被告知 String 對象和 StringBuffer 對象之間的區(qū)別,String 對象只能通過在新內(nèi)存中創(chuàng)建一個新的副本來修改,而 StringBuffer 對象包含容納字符串可以延長的空間。隨著垃圾收集系統(tǒng)的改進,它們使得不可預(yù)知的垃圾收集暫停變得不那么常見; 這可能會讓程序員自滿,相信自動回收內(nèi)存永遠不會成為性能問題,而實際上這就是一個性能問題。
4.4 API調(diào)用失敗時的性能
API的規(guī)范包括了調(diào)用失敗時的行為。返回錯誤代碼和拋出異常是告訴調(diào)用方函數(shù)未成功的常用方法。但是,與正常行為的規(guī)范一樣,沒有指定故障的性能。主要有以下是三種形式:
快速失敗。一個API調(diào)用很快就失敗了,和它的正常行為一樣快或者更快。例如,調(diào)用 sqrt (- 1)會很快失敗。即使當(dāng)一個 malloc 調(diào)用因為沒有更多的內(nèi)存可用而失敗時,這個調(diào)用也應(yīng)該像任何 malloc 調(diào)用一樣快速地返回,因為后者必須從操作系統(tǒng)請求更多的內(nèi)存。為了讀取一個不存在的磁盤文件而打開一個流的調(diào)用很可能與成功調(diào)用返回的速度一樣快。
慢慢失敗。有時,一個API調(diào)用失敗的速度非常慢,以至于應(yīng)用程序可能希望以其他方式進行。例如,打開到另一臺計算機的網(wǎng)絡(luò)連接請求只有在幾次長時間超時后才會失敗。
- 永遠失敗。有時候一個API調(diào)用只是暫停,根本不允許應(yīng)用程序繼續(xù)運行。例如,其實現(xiàn)等待從未釋放的同步鎖的調(diào)用可能永遠不會返回。
- 對于失敗性能的直覺很少像對于正常性能的直覺那樣好。原因很簡單,編寫、調(diào)試和調(diào)優(yōu)程序時處理故障事件的經(jīng)驗遠遠少于處理普通事件。另一個原因是,API調(diào)用可能在許多方面出現(xiàn)故障,其中一些是致命的,而且并非所有的故障都在 API 規(guī)范中有所描述。即使是旨在更精確地描述錯誤處理的異常機制,也不能使所有可能的異常都可見。此外,隨著庫函數(shù)的增加,失敗的機會也在增加。例如,包裝網(wǎng)絡(luò)服務(wù)的API(ODBC、 JDBC、 UPnP等等)從本質(zhì)上訂閱了大量的網(wǎng)絡(luò)故障機制。
- 一個勤奮的程序員會盡可能處理不可能的失敗。一種常見的技術(shù)是用 try... catch 塊包圍程序的大部分,這些塊可以重試失敗的整個部分。交互式程序可以嘗試保存用戶的工作,捕獲周圍的整個程序,其效果是減輕失敗的主程序造成的損失,例如保存在一個磁盤文件,關(guān)鍵日志或數(shù)據(jù)結(jié)構(gòu)等等。
處理暫停或死鎖的唯一方法可能是設(shè)置一個watchdog線程,該線程期望定期檢查一個正常運行的應(yīng)用程序,如果健康檢查異常,watchdog就會采取行動,例如,保存狀態(tài)、中止主線程和重新啟動整個應(yīng)用程序等。如果一個交互式程序通過調(diào)用可能緩慢失敗的函數(shù)來響應(yīng)用戶的命令,它可能會使用watchdog終止整個命令,并返回到允許用戶繼續(xù)執(zhí)行其他命令的已知狀態(tài),這就產(chǎn)生了一種防御性的編程風(fēng)格。
5 確保API 性能的經(jīng)驗性方法
程序員根據(jù)對 API 性能的期望選擇 API、數(shù)據(jù)結(jié)構(gòu)和整個程序結(jié)構(gòu)。如果預(yù)期或性能嚴(yán)重錯誤,程序員不能僅僅通過調(diào)優(yōu) API 調(diào)用來恢復(fù),而必須重寫程序(可能是主要部分)。前面提到的交互式程序的防御結(jié)構(gòu)是另一個例子。
當(dāng)然,有許多程序的結(jié)構(gòu)和性能很少受到庫性能的影響(科學(xué)計算和大型模擬通常屬于這一類)。然而,今天的許多“常規(guī) IT” ,特別是遍及基于 web 的服務(wù)的軟件,廣泛使用了對整體性能至關(guān)重要的庫。
即使性能上的微小變化也會導(dǎo)致用戶對程序的感知發(fā)生重大變化,在處理各種媒體的節(jié)目中尤其如此。偶爾放棄視頻流的幀可能是可接受的 ,但是用戶可以感知到音頻中哪怕是輕微的中斷,因此音頻媒體性能的微小變化可能會對整個節(jié)目的可接受性產(chǎn)生重大影響。這種擔(dān)憂引起了人們對服務(wù)質(zhì)量的極大興趣,在許多方面,服務(wù)質(zhì)量是為了確保高水平的業(yè)績。
盡管違反性能契約的情況很少,而且很少是災(zāi)難性的,但在使用軟件庫時注意性能可以幫助構(gòu)建更健壯的軟件。以下是一些經(jīng)驗性原則:
5.1 謹(jǐn)慎地選擇API 和程序結(jié)構(gòu)
如果有幸從頭開始編寫一個程序,那么在開始編寫程序時,要考慮一下性能約定的含義。如果這個程序一開始只是一個原型,然后在服務(wù)中保持一段時間,那么毫無疑問它至少會被重寫一次; 重寫是一個重新思考 API 和結(jié)構(gòu)選擇的機會。
5.2 在新版本發(fā)布時提供一致的性能約定
一個新的實驗性 API 會吸引那些開始衍生 API 性能模型的用戶。此后,更改性能約定肯定會激怒開發(fā)人員,并可能導(dǎo)致他們重寫自己的程序。一旦 API 成熟,性能約定不變就很重要了。事實上,大多數(shù)通用 API (例如 libc)之所以變得如此,部分原因在于它們的性能約定在 API 發(fā)展過程中是穩(wěn)定的。同樣的道理也適用于 api 端口
人們可能希望 API 提供者能夠定期測試新版本,以驗證它們沒有引入性能怪癖。不幸的是,這樣的測試很少進行。但是,這并不意味著不能對依賴的 API 部分進行自己的測試。使用分析器,通常可以發(fā)現(xiàn)程序依賴于少量的API。編寫一個性能測試工具,將一個API的新版本與早期版本的記錄性能進行比較,這樣可以給程序員提供一個早期預(yù)警警,即隨著API新版本的發(fā)布,他們自己代碼的性能將發(fā)生變化。
許多程序員希望計算機及其軟件能夠一致地隨著時間的推移而變得更快。這實際上對于供應(yīng)商來說是很難保證的,但是它們會讓客戶相信是這樣的。許多程序員希望圖形庫、驅(qū)動程序和硬件的新版本能夠提高所有圖形應(yīng)用程序的性能,并熱衷于多種功能的改進,這通常會降低舊功能的性能,哪怕只是輕微的降低。
我們還可以希望 API 規(guī)范將性能約定明確化,這樣使用、修改或移植代碼的人就可以遵守約定。注意,函數(shù)對動態(tài)內(nèi)存分配的使用,無論是隱式的還是自動的,都應(yīng)該是API文檔的一部分。
5.3 防御性編程可以提供幫助
在調(diào)用性能未知或高度可變的 API 時,程序員可以使用特殊的方式,對于考慮故障性能的情況尤其如此。我們可以將初始化移到性能關(guān)鍵區(qū)域之外,并嘗試預(yù)加載API 可能使用的任何緩存數(shù)據(jù)(例如字體)。表現(xiàn)出大量性能差異或擁有大量內(nèi)部緩存數(shù)據(jù)的 API ,可以通過提供幫助函數(shù)將關(guān)于如何分配或初始化這些結(jié)構(gòu)的提示從應(yīng)用程序傳遞給 API。某個程序偶爾會向服務(wù)器發(fā)出 ping 信號,這可以建立一個可能不可用的服務(wù)器列表,從而避免一些長時間的故障暫停。
5.4 API 公開的參數(shù)調(diào)優(yōu)
有些庫提供了影響性能的明確方法(例如,控制分配給文件的緩沖區(qū)的大小、表的初始大小或緩存的大小),操作系統(tǒng)還提供了調(diào)優(yōu)選項。調(diào)整這些參數(shù)可以在性能約定的范圍內(nèi)提高性能,調(diào)優(yōu)不能解決總體問題,但可以減少嵌入在庫中的固定選項,這些選項會嚴(yán)重影響性能。
有些庫提供了具有相同語義函數(shù)的替代實現(xiàn),通常是通用API的具體實現(xiàn)形式。通過選擇最好的具體實現(xiàn)進行調(diào)優(yōu)通常非常容易,Java 集合就是這種結(jié)構(gòu)的一個很好的例子。
越來越多的API被設(shè)計成動態(tài)地適應(yīng)應(yīng)用,使程序員無需選擇最佳的參數(shù)設(shè)置。如果一個散列表太滿,它會自動擴展和重新哈希(這是一種優(yōu)點,但偶爾會降低性能)。如果文件是按順序讀取的,那么可以分配更多的緩沖區(qū),以便在更大的塊中讀取。
5.5 測量性能以驗證假設(shè)
常見方式是檢測關(guān)鍵數(shù)據(jù)結(jié)構(gòu),以確定每個結(jié)構(gòu)是否正確使用。例如,可以測量哈希表的完整程度或發(fā)生哈希沖突的頻率。或者,可以驗證一個以寫性能為代價的快速讀取結(jié)構(gòu)實際上被讀取的次數(shù)多于被寫入的次數(shù)。
添加足夠的工具來準(zhǔn)確地度量許多 API 調(diào)用的性能是困難的,這需要大量的工作,而且可能投入產(chǎn)出比較低。然而,在那些對應(yīng)用程序的性能至關(guān)重要的 API 調(diào)用上添加工具(假設(shè)能夠識別它們,并且正確的識別) ,就可以在出現(xiàn)問題時節(jié)省大量時間。注意,這些代碼中的大部分可以在新版本的性能監(jiān)視器中重用。
所有這些都不是為了阻止完美主義者開發(fā)自動化儀表盤和測量的工具,或者開發(fā)詳細說明性能約定的方法,以便性能測量能夠建立對性能約定的遵守。這些目標(biāo)并不容易實現(xiàn),回報可能也不會很大。
通常可以在不事先檢測軟件的情況下進行性能度量,優(yōu)點是在出現(xiàn)需要跟蹤的問題之前不需要任何工作還可以幫助診斷當(dāng)修改代碼或庫影響性能時出現(xiàn)的問題。定期進行概要分析,從可信賴的基礎(chǔ)上衡量性能偏差。
5.6 使用日志檢測和記錄異常
當(dāng)分布式服務(wù)組成一個復(fù)雜的系統(tǒng)時,會出現(xiàn)越來越多的違反性能約定的行為。注意,通過網(wǎng)絡(luò)接口提供的服務(wù)有時具有指定可接受性能的SLA。在許多配置中,度量過程偶爾會發(fā)出服務(wù)請求,以檢查 SLA 是否滿足 。由于這些服務(wù)使用類似于 API 調(diào)用的方法(例如,遠程過程調(diào)用或其變體,如 XML-RPC、 SOAP 或 REST),因此可能是有性能約定的期望。應(yīng)用程序會檢測這些服務(wù)的失敗,并且通常會應(yīng)對得當(dāng)。
然而,響應(yīng)緩慢,特別是當(dāng)有許多這樣的服務(wù)互相依賴時,可能會非常快地破壞系統(tǒng)性能。如果這些服務(wù)的客戶能夠記錄他們所期望的性能,并生成有助于診斷問題的日志(這就是 syslog 的用途之一) ,那將會很有幫助。當(dāng)文件備份看起來不合理的慢,那是不是比昨天慢呢?比最新的操作系統(tǒng)軟件更新之前還要慢?考慮到多臺計算機可能共享的備份設(shè)備,它是否比預(yù)期的要慢?或者是否有一些合理的解釋(例如,備份系統(tǒng)發(fā)現(xiàn)一個損壞的數(shù)據(jù)結(jié)構(gòu)并開始一個長的過程來重新構(gòu)建它) ?
在沒有源代碼,也沒有構(gòu)成組合的模塊和API的細節(jié)的情況下,診斷不透明軟件組合中的性能問題可以在報告性能和發(fā)現(xiàn)問題方面發(fā)揮作用。雖然不能在軟件內(nèi)部解決性能問題 ,但是可以對操作系統(tǒng)和網(wǎng)絡(luò)進行調(diào)整或修復(fù)。如果備份設(shè)備由于磁盤幾乎已滿而速度較慢,那么肯定可以添加更多的磁盤空間。好的日志和相關(guān)的工具會有所幫助; 遺憾的是,日志在計算機系統(tǒng)演進中可能是一個被低估和忽視的領(lǐng)域。
誠然,性能約定沒有功能正確性約定那么重要,但是軟件系統(tǒng)的重要用戶體驗幾乎都取決于它。
6 面對API,開發(fā)者的苦惱
對于向外部提供的API,有一些因素成為了開發(fā)者的苦惱。
6.1 沒有 API
API 允許客戶實現(xiàn)你沒有想到的功能,允許客戶更多的使用產(chǎn)品。如果存在一個API,開發(fā)者可以自動使用API的產(chǎn)品,這將產(chǎn)生更多的應(yīng)用。他們可以自動化整個公司的配置,可以基于你的 API 構(gòu)建全新的應(yīng)用程序。只要想想他們能夠通過 API 使用多少產(chǎn)品就可以了。
6.2 繁瑣的注冊
只有復(fù)雜的注冊過程才能保證API的安全么?實際上只是自尋煩惱。要么使整個過程完全自助服務(wù),要么根本不需要任何類型的注冊過程,這樣才是良好的API使用開端
6.3 多收費的API
對服務(wù)收費是正常的,或者只在“企業(yè)版”中包含 API 訪問 。讓 API 訪問變得如此昂貴,以至于銷售部門認為 API 代表額外的利潤激勵。事實上,API 不應(yīng)該成為一種收入來源,而是一種鼓勵人們使用產(chǎn)品的方式。
6.4 隱藏 API 文檔
沒有什么比在搜索引擎中看不到API 文檔更糟糕的事了。那些將API文檔放在登錄之后的體驗屏幕后面,可以認為是設(shè)計人員的大腦短路。通過某種注冊或登錄來阻止競爭對手查看API 并從中學(xué)習(xí),這是一種幼稚的想法。
6.5 糟糕的私有協(xié)議
一個私有協(xié)議可能很難理解,也不可能調(diào)試。SOAP可能會變得臃腫和過于冗長,從而導(dǎo)致帶寬消耗和速度減慢。它也是基于 XML 的,尤其是在移動或嵌入式客戶端上,解析和操作起來非常昂貴。許多 API 使用 JSON API 或 JSON-rpc ,它們是輕量級的,易于使用,易于調(diào)試。
6.6 單一的 API 密鑰
如果只允許使用一個 API 密鑰,相當(dāng)于創(chuàng)建了一個“第22條軍規(guī)”的情況。開發(fā)者無法更改服務(wù)器上的 API 密鑰,因為客戶端也會在更新之前失去了訪問權(quán)限。他們也不能首先更改客戶端,因為服務(wù)器還不知道新的 API 密鑰。如果有多個客戶端,那基本上就是一場災(zāi)難。
API密鑰基本上就是用于識別和驗證客戶的密碼。也許是密鑰泄露,也許某個員工離開了公司帶走了鑰匙,或許每年輪換密鑰是安全策略的一部分,最終,開發(fā)者都將需要更改他們的 API 密鑰。
6.7 手動維護文檔
隨著 API 的發(fā)展,API 和文檔有可能脫離同步。一個錯誤的API說明會導(dǎo)致一個無法工作的系統(tǒng),會令人極其的沮喪。一個與文檔不同步的 API,會讓人束手無策。
6.8 忽略運維環(huán)境
將基礎(chǔ)設(shè)施視為代碼的能力正在成為運維團隊的要事。它不僅使操作更容易、更可測試和更可靠,而且還為諸如支付行業(yè)所要求的安全性最佳實踐鋪平了道路。如果忽略了Ansible, Chef, Puppet等類似的系統(tǒng),可能會導(dǎo)致一系列令人困惑的不兼容選項,使得生產(chǎn)環(huán)境的API調(diào)用難以為繼。
6.9 非冪等性
假設(shè)有一個創(chuàng)建虛擬機的 API 調(diào)用。如果這個 API 調(diào)用是冪等的,那么我們第一次調(diào)用它的時候就創(chuàng)建了 VM。第二次調(diào)用它時,系統(tǒng)檢測到 VM 已經(jīng)存在,并簡單地返回,沒有錯誤。如果這個 API 調(diào)用是非冪等的,那么調(diào)用10次就會創(chuàng)建10個 vm。
為什么有人要多次調(diào)用同一個 API?在處理 rpc時,響應(yīng)可能是成功、失敗或根本沒有應(yīng)答。如果沒有收到服務(wù)器的回復(fù),則必須重試請求。使用冪等協(xié)議,可以簡單地重發(fā)請求。對于非冪等協(xié)議,每個操作后都必須跟隨發(fā)現(xiàn)當(dāng)前狀態(tài)并進行正確恢復(fù)的代碼,將所有恢復(fù)邏輯放在客戶機中是一種丑陋的設(shè)計。將此邏輯放在客戶機庫中可以確保客戶端需要更頻繁的更新,要求用戶實現(xiàn)恢復(fù)邏輯是令人難受的。
當(dāng) API 是冪等的時候,這些問題就會減少或消除。
如果網(wǎng)絡(luò)是不可靠的,那么網(wǎng)絡(luò) API 本質(zhì)上也是不可靠的。請求可能在發(fā)送到服務(wù)器的途中丟失,而且永遠不會執(zhí)行。執(zhí)行可能已經(jīng)完成,但是回復(fù)的信息已經(jīng)丟失了。服務(wù)器可能在操作期間重新啟動。客戶端可能在發(fā)送請求時重新啟動,在等待請求時重新啟動,或者在接收請求時重新啟動,在本地狀態(tài)存儲到數(shù)據(jù)庫之前重新啟動。在分布式計算中,一切都有可能失敗。
程序員們以做好工作和完善的系統(tǒng)給用戶留下深刻印象而自豪,令開發(fā)者苦惱的API往往出于無知、缺乏資源或者不可能的最后期限。
7 API 設(shè)計中的文化認知
如果讓API 的設(shè)計可以做得更好的話,除了一些細節(jié)性的技術(shù)問題外,還可能需要解決一些文化問題。我們不僅需要技術(shù)智慧,還需要改變我們認識和實踐軟件工程的方式。
7.1 API的有意識訓(xùn)練
自己念書的時候,程序員的培訓(xùn)主要側(cè)重于數(shù)據(jù)結(jié)構(gòu)和算法。這意味著一個稱職的程序員必須知道如何編寫各種數(shù)據(jù)結(jié)構(gòu)并有效地操作它們。隨著開源運動的發(fā)展,這一切都發(fā)生了巨大的變化。如今,幾乎所有可以想象到的可重用功能都可以使用開放源碼。因此,創(chuàng)建軟件的過程發(fā)生了很大的變化,今天的軟件工程不是創(chuàng)建功能,而是集成現(xiàn)有的功能或者以某種方式重新封它。換句話說,現(xiàn)在的 API 設(shè)計比20年前更加重要,不僅擁有了更多的 API,而且這些 API 提供了比以前更加豐富且復(fù)雜的功能。
從來沒有人費心去解釋如何決定某個值應(yīng)該是返回值還是輸出參數(shù),如何在引發(fā)異常和返回錯誤代碼之間做出選擇,或者如何決定一個函數(shù)修改它的參數(shù)是否合適。所以,期望程序員擅長一些他們從未學(xué)過的東西是不合理的。
然而,好的 API 設(shè)計,即使很復(fù)雜,也是可以訓(xùn)練的,關(guān)鍵是認識到重要性并有意識的訓(xùn)練。
7.2 API設(shè)計人才的流失
一個老碼農(nóng)環(huán)顧四周,才發(fā)現(xiàn)周圍是多么的不尋常: 所有的編程同事都比我年輕,當(dāng)自己以前的同事或者同學(xué),大多數(shù)人不再寫代碼; 他們轉(zhuǎn)到了不同的崗位比如各種經(jīng)理、總監(jiān)、CXO ,或者完全離開了這個行業(yè)。這種趨勢在軟件行業(yè)隨處可見: 年長的程序員很少,通常是因為看不到職業(yè)生涯。如果不進入管理層,未來的加薪幾乎是不可能的。
一種觀點認為,年長程序員的職業(yè)優(yōu)勢在不斷喪失。這種想法可能是錯誤的: 年長的程序員可能不會像年輕人那樣熬夜,但這并不是因為他們年紀(jì)大,而是因為很多時候他們不用熬夜就能完成工作。
老程序員的流失是不幸的,特別是在 API 設(shè)計方面。雖然好的 API 設(shè)計是可以學(xué)習(xí)的,但是經(jīng)驗是無法替代的。需要時間和不斷的挖坑填坑才會做得更好。不幸的是,這個行業(yè)的趨勢恰恰是把最有經(jīng)驗的人從編程中提拔出來。
另一個趨勢是公司將最好的程序員提升為設(shè)計師或系統(tǒng)架構(gòu)師。通常情況下,這些程序員作為顧問外包給各種各樣的項目,目的是確保項目在正確的軌道上起步,避免在沒有顧問智慧的情況下犯錯誤。這種做法的意圖值得稱贊,但其結(jié)果通常是發(fā)人深省的: 顧問從來沒有經(jīng)歷過自己的設(shè)計決策的后果,這是對設(shè)計的一種嘲諷。讓設(shè)計師保持敏銳和務(wù)實的方法是讓他們吃自己的狗糧, 剝奪設(shè)計師反饋的過程最終可能注定失敗。
7.3 開放與控制
隨著計算的重要性不斷增長,有一些API的正確功能幾乎是無法描述的。例如, Unix 系統(tǒng)調(diào)用接口、 C標(biāo)準(zhǔn)庫、 Win32或 OpenSSL。這些 API的接口或語義的任何改變都會帶來巨大的經(jīng)濟成本,并可能引發(fā)漏洞。允許單個公司在沒有外部控制的情況下對如此關(guān)鍵的API進行更改是不負責(zé)任的。嚴(yán)格的立法控制和更開放的同行審查相結(jié)合,在兩者之間找到恰當(dāng)?shù)钠胶鈱τ谟嬎銠C的未來和網(wǎng)絡(luò)經(jīng)濟至關(guān)重要。
API設(shè)計確實很重要,因為整個計算機世界都是由API連接的。然而,證明實現(xiàn)良好API所需的投入產(chǎn)出比可能是困難的,特別是當(dāng)一個 API 沒有被客戶使用的時候。“當(dāng)幾乎沒有人使用我們的 API 時,收益是多少? ” 產(chǎn)品經(jīng)理或者老板們經(jīng)常可能會問這樣的問題。呵呵,也許你沒有做過這些事情,所以使用率很低。
【本文來自51CTO專欄作者“老曹”的原創(chuàng)文章,作者微信公眾號:喔家ArchiSelf,id:wrieless-com】