一文揭秘阿里實時計算Blink核心技術:如何做到唯快不破?
導讀:本文主要講解阿里巴巴實時大數據和相關的機器學習技術,以及這些技術如何實現大數據升級,最終取得卓越的雙11戰果。
大沙,阿里巴巴高級技術專家,負責實時計算Flink SQL,之前在美國臉書任職,Apache Flink committer。
實時計算in阿里巴巴
1999年起,阿里從電商平臺開始不斷拓展業務,在金融、支付、物流、文娛各個領域衍生出眾多產品,例如依托于淘寶、天貓為主的電商平臺、阿里媽媽廣告平臺、螞蟻金服支付寶、阿里云、大文娛等。今天的阿里它已經不僅僅是一個電商平臺,而是一個龐大的應用生態。阿里巴巴目前是全球***的電商平臺,2016財年收入達到5500億美金。在阿里平臺上有5億的用戶,相當于中國人口的1/3,每天有近1000萬用戶通過阿里平臺交易。
阿里儼然成為巨大的商業航母,在這艘航母之上,海量的用戶和應用必然會產生大量的數據。目前,阿里巴巴的數據量級已經達到EB級別,每天的增長量達到PB級別,實時計算日常峰值處理的數據量可達到1億每秒,今年雙11更是達到了驚人的4.7億每秒。
實時計算在阿里巴巴內部應用廣泛。隨著新經濟體的出現與發展,技術的革新和用戶需求的提升,人們越來越需要實時計算的能力,它的***好處就是能夠基于實時變化數據更新大數據處理的狀態和結果。接下來,舉兩個例子來闡釋實時計算在阿里內部應用的場景:
1.雙11大屏
每年雙11阿里都會聚合有價值的數據展現給媒體,GMV大屏是其中之一。整個GMV大屏是非常典型的實時計算,每條交易數據經過聚合展現在大屏之上。從DataBase寫入一條數據開始,到數據實時處理寫入HBase,***展現在大屏之上,整個過程的鏈路十分長。整個應用存在著許多挑戰:
1)大屏展現需要秒級延遲,這需要實時計算延遲在亞秒級別
2)雙11大量數據需要在一個Job中聚合完成
3)Exactly-Once 保持數據計算的精確性
4)系統高可用,不存在卡頓和不可用的情況
這個應用場景的SLA非常高,要求秒級延遲和數據的精確性,但它的計算并不復雜,接下來介紹更為復雜的應用。
2.實時機器學習
機器學習一般有兩個重要的組件:Feature 和Model。傳統的機器學習使用批計算對Feature的采集和Model的訓練,這樣更新頻率太低,無法適應數據在不斷變化的應用的需求。例如在雙11時,商品的價格、活動的規則與平時完全不同,依據之前的數據進行訓練得不到***的效果。因此,只有實時收集Feature并訓練Model,才能擬合出較為滿意的結果。為此,我們開發了實時機器學習平臺。
此實時機器學習平臺主要包括兩個部分:實時Feature計算和實時Model計算。這套系統同樣擁有很多挑戰,具體如下:
1)機器學習需要采集各種各樣Metrics,存在許多DataSource
2)維度多,如用戶維度、商品維度。維度的疊加甚至是笛卡兒積導致***的Metrics是海量的,State非常巨大
3)機器學習計算復雜,耗用大量CPU
4)某些數據不能存在State中,需要外部存儲,存在大量外部IO
3.實時A/B Testing
用戶的Query也有可能不停變化,典型的例子有實時的A/B Testing。
算法工程師在調優Model時會涉及多種Model,不同的Model有不同的計算模式和方法,產生不同的計算結果。因此,往往會有不同的Query訂閱實時數據,產生結果后根據用戶回饋迭代Model,最終得到***模型。A/B Tesing的挑戰在于算法工程師往往計算很多Metrics,所有的Metrics都通過實時計算進行統計會浪費大量資源。
針對這個挑戰,我們設計了A/B Testing的框架開發平臺。它用來同步算法工程師感興趣的Metrics進行聚合,收集起來并發送到Druid引擎。這樣,算法工程師根據不同Job的要求清洗數據到Druid,***在Druid之上對不同的Metrics進行統計分析,從而找到***的算法Model。
綜上,實時計算在阿里巴巴內部存在如下挑戰:
1)業務龐大,場景多,大量的機器學習需求,這些因素一起導致了計算邏輯十分復雜
2)數據量大,作業多,因此整個實時計算的機器規模十分巨大
3)要保障低延遲和數據精確性,同時要滿足高吞吐量的需求
Flink的選定及優化
為了應對上述挑戰,我們調研了許多計算框架,最終選定Flink,原因如下:
1.Flink很好地引入和設計了State,基于State復雜的邏輯計算如join能得到很好的描述
2.Flink引入了Chandy-Lamport 算法,在此算法的支撐下可以***實現Exactly-Once,并能在低延遲下實現高吞吐量。
然而,Flink在State、Chandy-Lamport 算法等方面還有很多缺陷,為此阿里開辟了名為Blink的項目。
Blink是開源Flink與阿里巴巴Improvement的結合,主要分兩大塊:
1.BlinkRuntime
包括存儲、調度和計算,不同公司在使用Flink時,存儲、調度以及底層優化等方面會有諸多不同,阿里巴巴的blink內部也對Runtime做了諸多個性化的優化,這一層不好與Apache Flink社區統一,我們稱之為Blink Runtime。
2.Flink SQL
原生的Flink只有比較底層的DataStream API,用戶在使用時需要設計實現大量的代碼,此外DataStream本身也有設計上的缺陷。為了方便用戶使用,阿里巴巴團隊設計了流計算的Flink SQL并推回了社區。取名Flink SQL而不是Blink SQL,主要原因Blink和Flink在SQL這個用戶API上面是完全和社區統一的,另外Apache Flink的大部分功能都是阿里巴巴貢獻的,所以說Flink SQL就是Blink SQL,沒有特別大的區別。
BlinkRuntime核心優化解密
1.部署和模型的優化
優化包含以下幾點:
1)解決大規模部署問題。Flink中一個Cluster只有一個JobMaster來管理所有的Job。隨著Job的不斷增加,單一的Master無法承接更多的Job,產生了瓶頸。因此,我們重構了架構,使每一個Job擁有自己的Master。
2)早期的Flink中TaskManager管理很多Task,某一個Task的問題會導致TaskManager崩潰,進而影響其他Job。我們使每一個Job擁有自己的TaskManager,增強了Job的隔離。
3)引入ResourceManager。ResourceManager可以和JobMaster通訊,實時動態地調整資源,達到***的集群部署。
4)我們不僅將這些優化應用在YarnCluster上,還應用到Mesos和Standalone的部署上。
有了這些工作,Flink就可以應用到大規模的集群部署。
2.Incremental Checkpoint
實時計算需要不停的在checkpoint的時候來保留計算狀態。早期的Flink的checkpoint的設計存在缺陷,在每個checkpoint發生的時候,它會讀取所有舊的狀態數據,和新的數據合并后按照全量的方式寫入磁盤。隨著State的不斷增大,在每次做checkpoint的時候所需要的數據讀取和寫入的量級是十分巨大。 這就導致Job的checkpoint的間隔需要設置的很大,不能小于1分鐘。越大的checkpoint的間隔, failover的時候回退的計算就越大,造成的數據延遲也就越嚴重。
為了減少checkpoint間隔,我們提出了Incremental Checkpoint的設計。概括的說就是在checkpoint的時候只存儲增量的state變化的數據。由于歷史上每個checkpoint的數據都已經保存,后面的checkpoint只需要將不同的數據放入存儲,這樣每次做checkpoint需要更新的數據量就非常小,使得checkpoint可以在若干秒級內完成,這就大大減小了failover時可能引起的延遲。
3.異步IO
很多時候我們不得不將數據放在外部存儲中,這樣在計算過程中就需要通過網絡IO讀取數據。傳統的方式使用 Sync-IO的讀取方式,在發出數據請求之后,只有等待到結果返回之后才能開始下一個數據請求,這種做法造成了CPU資源的浪費,因為CPU在大多數情況下都在等待網絡IO的請求返回。Sync-IO使得CPU的資源利用率無法提高到***,也就大大影響了單位CPU下的計算吞吐。為此提升計算吞吐,我們設計了Async-IO的數據讀取框架,它允許異步地多線程地讀取數據。
每次數據請求發出后不需要等待數據返回就繼續發送下一個數據請求。當數據請求從外部存儲返回后,計算系統會調用callback方法處理數據。如果數據計算不需要保序,數據返回之后就會快速經過計算發出。如果用戶需要數據的計算保序時,我們使用buffer暫時保存先到的數據,等前部數據全部到達后再批量地發送。在使用了Async-IO之后,根據設置的buffer大小不同計算吞吐可以提升幾十倍甚至幾百倍,這就極大地提升了單位CPU利用率和整體的計算性能。
值得一提的是,以上所述的所有Blink Runtime優化已經全部貢獻給了Apache Flink社區。
Flink SQL核心功能解密
1.阿里完成Apache Flink SQL 80%研發工作
目前,Apache Flink SQL 80%的功能是阿里巴巴實時計算團隊貢獻的,包括兩百個提交和近十萬行代碼。使用Flink SQL的原因是因為我們發現了底層API給用戶的遷移、上線帶來的極大不便。那么,我們又為什么選擇SQL?主要原因如下:
1)SQL是十分通用的描述性語言,SQL適合用來讓用戶十分方便的描述Job的需求。
2)SQL擁有比較好的優化框架,使得用戶只需要專注于業務邏輯得設計而不用關心狀態管理,性能優化等等復雜得設計,這樣就大大降低了使用門檻。
3)SQL易懂,適合不同領域的人使用。使用SQL的用戶往往都不需要特別多的計算機編程基礎,從產品設計到產品開發各種人員都可以快速掌握SQL的使用方法。
4)SQL的API十分穩定,在做機構升級,甚至更換計算引擎時都不用修改用戶的Job而繼續使用。
5)有些應用場景需要流式更新,批式驗證。使用SQL可以統一批計算和流計算的查詢query。真正實現一個Query,同樣的結果。
2.流處理 VS 批處理
要想設計和批處理統一的流計算SQL,就要了解流處理和批處理的區別。兩者的核心區別在于流處理的數據是無窮的而批處理的數據是有限的。這個本質區別又引入另外三個更具體的區別:
1)流處理會不斷產生結果而不會結束,批處理往往只返回一個最終結果并且結束。比方說,如果要統計雙11的交易金額,使用批處理計算就要在雙11當天的所有交易結束后,再開始計算所有買家花費的總金額并得到一個最終數值。而流處理需要追蹤實時的交易金額,實時的計算并更新結果。
2)流計算需要做checkpoint并保留狀態,這樣在failover的時候能夠快速續跑。而批計算由于它的輸入數據往往是被持久化存儲過的,因此往往不需要保留狀態。
3)流數據會不斷更新,例如某一買家的花費總金額在不斷變化,而批處理的數據是一天花費的總金額,是固定的,不會變化的。流數據處理是對最終結果的一個提前觀測,往往需要把提前計算的結果撤回(Retraction)做更改而批計算則不會。
3.Query Configuration
上面提到的這些區別都不涉及用戶的業務邏輯,也就是說這些區別不會反應在SQL的不同。我們認為這些區別只是一個job的屬性不同。為了描述流計算所特有的一些屬性,例如什么時候產生流計算結果和怎么保留狀態,我們設計容許用戶配置的Query Configuration,它主要包括兩個部分:
1) Latency SLA
定義了從數據產生到展現的延遲,如雙11大屏是秒級別。用戶根據自己的需要配置不同SLA,我們的SQL系統會根據SLA的要求做***的優化,使得在滿足用戶需求的同時達到系統性能的***。
2) State Retention/TTL
流計算是永不停止的,但是流數據中的State往往不需要保留很久,保留過久勢必對存儲是個浪費,也極大的影響了性能。所以我們容許用戶設置合理的TTL(過期時間)來獲得更好的計算性能。
我們通過Query Configuration描述了流和批所不同的一些屬性。接下來我們需要繼續考慮如何設計流式的SQL?
4.動態表(Dynamic-Table)
問題關鍵在于SQL在批處理中對表操作而流數據中并沒有表。因此,我們創建了數據會隨著時間變化的動態表。動態表是流的另一種表現形式,它們之間具有對偶性,即它們可以互相轉換而不破壞數據的一致性。以下是一個例子:
如圖,左邊是輸入流,我們為每一條數據產生Dynamic-Table,再將Table的變化用Changelog發送出去。這樣兩次變化后,輸入流和輸出流中的數據始終保持一致,這就證明了引入Dynamic-Table并沒有丟失語義和數據。
有了動態表的概念,我們就可以應用傳統SQL作用于流上。值得一提的是,Dynamic-Table是虛擬的存在著,它并不需要實際的存儲來落地。我們再來看一個例子:
如圖,當有輸入流的時候我們進行連續查詢。我們將Stream理解為一個Dynamic-Table,動態查詢是基于Dynamic-Table產生一個新的Dynamic-Table,如果需要新產生的Dynamic-Table還可以繼續產生流。這里,因為加入了連續查詢的聚合計算,左右兩邊的流已經發生了變換。總之動態表的引入提供了我們在流上做連續SQL查詢的能力。
5.Stream SQL是沒有必要存在的
通過上面的討論,我們發現有了Dynamic-Table之后我們不需要再創造任何新的流式SQL的語義。因此我們得出這樣的結論:流式SQL是沒必要存在的。ANSI SQL完全可以描述Stream SQL的語義,保持ANSI SQL的標準語義是我們構建Flink SQL的一個基本原則。
6.ANSI SQL功能實現
基于上面的理論基礎,我們繼而實現了流計算所需要的若干ANSI SQL功能,包括:DML、DDL、UDF/UDTF/UDAF、連接Join、撤回(Retraction)、Window聚合等等, 除了這些功能之外,我們還做了大量的查詢優化,從而保障了Flink SQL即能滿足用戶的各種查詢的需求,同時兼具優異的查詢性能。接下來,簡要介紹其中幾項:
1) JOIN
流和動態表具有對偶性,一條SQL看似是Table的join,事實上是流的join。
例如Inner Join的實現原理如下:數據會從輸入的兩邊任意一條流而來,一邊數據先來會被存在State中并按照Joining key查詢另外一邊的State,如果存在就會輸出結果,不存在則不輸出,直到對面數據來了之后才產生結果。
總之,兩個流具有兩個state,一邊的數據到達后存下來等待另外一邊數據,全部到達后inner join產生結果。 除了兩條流的join之外,我們還引入了流和外部表的join。我們的機器學習平臺會把大量的數據存儲在HBase中,查詢HBase中的數據的操作實際上是在連接一個外部表。連接外部表往往存在兩個模式:
a)Look up方式。流數據到達時即時地查詢外部表,從而得到結果。
b)Snapshot方式。流數據到達時即時地發送snapshot的版本信息給外部存儲service從而查詢數據,外部表存儲根據版本信息返回結果。
值得一提的是,我們設計的這個流和外部表關聯的這個功能沒有引入任何新的語法,是完全按照SQL-2011的標準實現的。同樣的查詢在批計算上也適用。
2) Retraction
撤回是流計算的重要概念,舉一個例子作解釋:計算詞頻
詞頻的計算是指對所有英文單詞統計頻率,并最終按照頻率統計不同頻率下不同單詞的個數。例如,如果一個統計的初始狀態只有Hello World Bark三個單詞,且每個單詞只出現一次,那么詞頻的最終結果就是出現頻率為1的單詞有3個(出現頻率為其他次數的完全沒有),因此結果表只有一行“1——3”。當單詞不斷更新,再增加一個Hello時,因為Hello的出現頻率變為2次,我們在詞頻的結果表中插入“2——1”這么一行新的數據。
顯然,出現兩次的單詞是一個,那么“2——1”這個結果是對的,但是出現頻率為1次的單詞數已經錯了,應該是2個,而不是3個。出現這種問題的本質原因是因為流計算輸出的結果是對計算的一個提前觀測,隨著數據的不斷更新,計算結果必然會發生改變,這就要求我們對之前發生的結果做撤回(retraction)再把更新的結果發出去,不然數據結果就不錯誤。對于上面的例子,當Hello的頻率從1變到2的時候,我們不僅需要在結果表中插入“2——1”這么一行,還需要對“1——3”這一行做撤回更新操作。
值得一提的是什么時候需要撤回,什么時候不需要,完全由SQL的Query Optimizer來判斷,這個用戶是完全不需要感知的,用戶只需要通過SQL描述他的業務計算邏輯就好了。如圖所示,***個場景不需要撤回而第二個需要,這完全是由優化框架決定而非用戶 。這一點,大大體現了使用SQL,并利用SQL中所擁有的天然優化框架的好處。
3) Window聚合
Window聚合是Flink SQL的一個重要能力。圖中的這個例子我們對每一個小時的數據做聚合統計。除了這種Tumble window我們還支持了Sliding Window和Session Window。將來還會支持用戶自定義的window。
4) 查詢優化Query Optimization
除了添加新的功能,我們還做了大量的查詢優化。例如micro-batching。如果沒有micro-batching,處理每一條數據就會伴隨著幾次IO讀寫。有了micro-batching之后我們可以用幾次IO處理來處理上千條數據。除此之外,我們還做了大量的的filter/join/aggregate pushdown以及TopN的優化,下面再舉例解釋TopN的優化:
如上圖,我們想取銷售量前三的city,對用戶的Query有兩種底層的實現:
a)一種方式是當沒一條數據來的時候,對保存的所有city進行排序,再截取前三個city。這種設計每條數據跟新都會重新排列所有city,勢必會造成大量計算資源浪費。
b)我們的Query Optimizer會自動識別到查詢語句,對這種計算做優化,真正執行過程中只需要不停的更新排前三的city就可以了,這樣大大優化了計算的復雜度,提升了性能
阿里巴巴實時計算應用
基于流計算SQL之上我們開發了兩個計算平臺。
1.阿里云流計算開發平臺
一個是阿里云流計算平臺(streamCompute),該平臺允許用戶編寫SQL,并在平臺內部調試debug。調試正確后,用戶可以通過這個平臺直接將作業發布在阿里云集群上部署,部署完成后后檢測運維上線的。因此這個平臺整合了所有實時計算的需求,集開發、Debug、上線部署、運維于一體,大大加速了用戶開發和上線的效率。值得一提的是,2017年雙11期間阿里集團絕大多數的實時計算Job均通過這個平臺發布。我們今年9月開始,通過阿里云,包括公共云、專有云也將這個平臺開放給外部企業,讓他們能夠使用到阿里巴巴實時計算的能力。
2.阿里實時機器學習平臺Porsche
為了方便算法同學開發機器學習任務,我們基于Flink SQL以及Hbase,設計實現了一個面向算法人員、支持可視化自助開發運維的在線機器學習平臺——Porsche。如上圖所示,用戶在Porsche平臺的IDE,通過可視化的方式將組件拖入畫布中,配置好組件屬性,定義好完整的計算DAG。這個DAG會被翻譯成SQL,最終提交給Blink執行。另外,值得一提的是,Porsche平臺還支持Tensorflow,今年雙11也是大放異彩,本平臺免去了算法同學學習使用SQL的成本,暫時只對內開放。
雙11實時計算總結
上圖是阿里巴巴實時計算架構,底層是數千規模的物理機,之上是統一部署的Resource Management和Storage,然后是Blink Runtime和Flink SQL,用戶通過StreamCompute和Porsche平臺提交Job,現在已經在阿里內部支持了數百個工程師近千個Flink SQL Job。上述就是阿里巴巴實時計算的現狀。
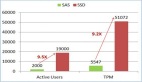
在實時計算的助力下,阿里雙11拿到1682億的輝煌戰果,實時計算的貢獻主要體現在以下幾點:
1.本次雙11是互聯網歷史***規模的并發,每秒幾十萬的交易和支付的實時聚合統計操作全部是是由Blink計算帶來的
2.3分01秒100億數據的展現不僅需要較高的Data Base的高吞吐能力,還考驗著實時計算的速度
3.算法平臺幫助算法同學取得了很好的搜索和推薦效果,獲得了整體GMV的增長
總之,實時計算不僅滿足了阿里巴巴內部多種多樣的需求,還提升了GMV。我們希望通過阿里云實時計算平臺(StreamCompute)把Blink實時計算能力輸出給阿里之外的所有企業,讓他們能從中獲益。以上就是本次的分享,謝謝大家。