深入淺出Zookeeper(一)Zookeeper架構及FastLeaderElection機制
一、Zookeeper是什么
Zookeeper是一個分布式協調服務,可用于服務發現,分布式鎖,分布式領導選舉,配置管理等。
這一切的基礎,都是Zookeeper提供了一個類似于Linux文件系統的樹形結構(可認為是輕量級的內存文件系統,但只適合存少量信息,完全不適合存儲大量文件或者大文件),同時提供了對于每個節點的監控與通知機制。
既然是一個文件系統,就不得不提Zookeeper是如何保證數據的一致性的。本文將介紹Zookeeper如何保證數據一致性,如何進行領導選舉,以及數據監控/通知機制的語義保證。
二、Zookeeper架構
1. 角色
Zookeeper集群是一個基于主從復制的高可用集群,每個服務器承擔如下三種角色中的一種
- Leader 一個Zookeeper集群同一時間只會有一個實際工作的Leader,它會發起并維護與各Follwer及Observer間的心跳。所有的寫操作必須要通過Leader完成再由Leader將寫操作廣播給其它服務器。
- Follower 一個Zookeeper集群可能同時存在多個Follower,它會響應Leader的心跳。Follower可直接處理并返回客戶端的讀請求,同時會將寫請求轉發給Leader處理,并且負責在Leader處理寫請求時對請求進行投票。
- Observer 角色與Follower類似,但是無投票權。

2. 原子廣播(ZAB)
為了保證寫操作的一致性與可用性,Zookeeper專門設計了一種名為原子廣播(ZAB)的支持崩潰恢復的一致性協議。基于該協議,Zookeeper實現了一種主從模式的系統架構來保持集群中各個副本之間的數據一致性。
根據ZAB協議,所有的寫操作都必須通過Leader完成,Leader寫入本地日志后再復制到所有的Follower節點。
一旦Leader節點無法工作,ZAB協議能夠自動從Follower節點中重新選出一個合適的替代者,即新的Leader,該過程即為領導選舉。該領導選舉過程,是ZAB協議中最為重要和復雜的過程。
3. 寫操作
(1) 寫Leader
通過Leader進行寫操作流程如下圖所示
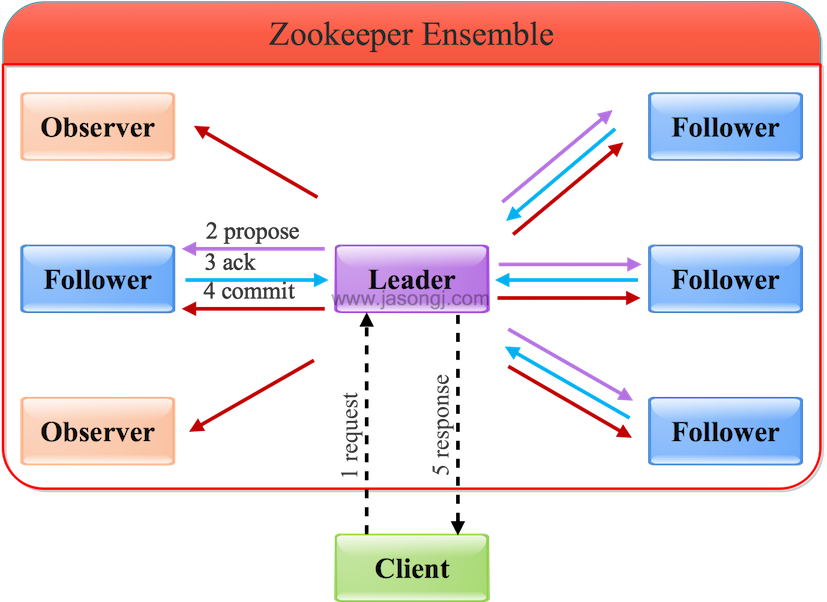
由上圖可見,通過Leader進行寫操作,主要分為五步:
- 客戶端向Leader發起寫請求
- Leader將寫請求以Proposal的形式發給所有Follower并等待ACK
- Follower收到Leader的Proposal后返回ACK
- Leader得到過半數的ACK(Leader對自己默認有一個ACK)后向所有的Follower和Observer發送Commmit
- Leader將處理結果返回給客戶端
這里要注意
- Leader并不需要得到Observer的ACK,即Observer無投票權
- Leader不需要得到所有Follower的ACK,只要收到過半的ACK即可,同時Leader本身對自己有一個ACK。上圖中有4個Follower,只需其中兩個返回ACK即可,因為(2+1) / (4+1) > 1/2
- Observer雖然無投票權,但仍須同步Leader的數據從而在處理讀請求時可以返回盡可能新的數據
(2) 寫Follower/Observer
通過Follower/Observer進行寫操作流程如下圖所示:
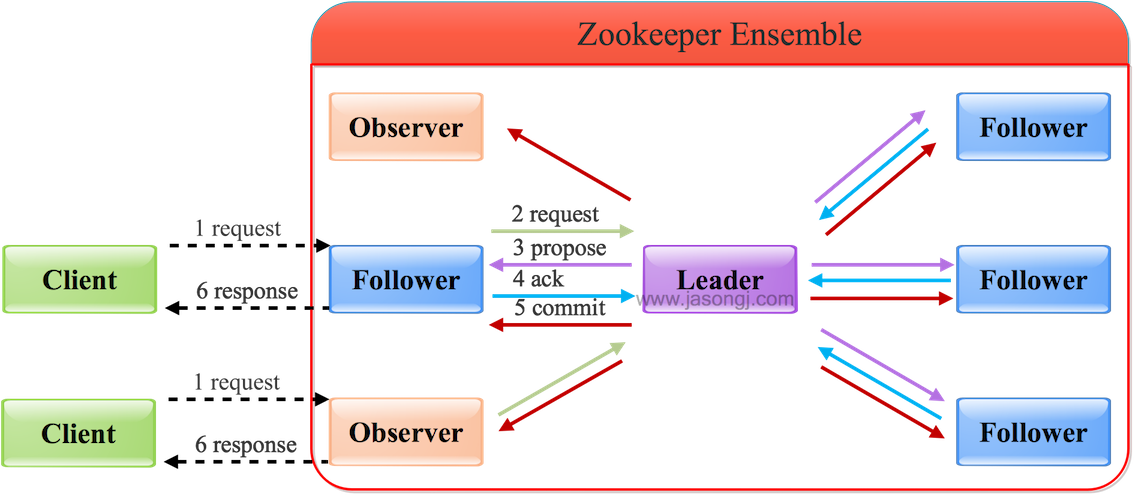
從上圖可見
- Follower/Observer均可接受寫請求,但不能直接處理,而需要將寫請求轉發給Leader處理
- 除了多了一步請求轉發,其它流程與直接寫Leader無任何區別
4. 讀操作
Leader/Follower/Observer都可直接處理讀請求,從本地內存中讀取數據并返回給客戶端即可。
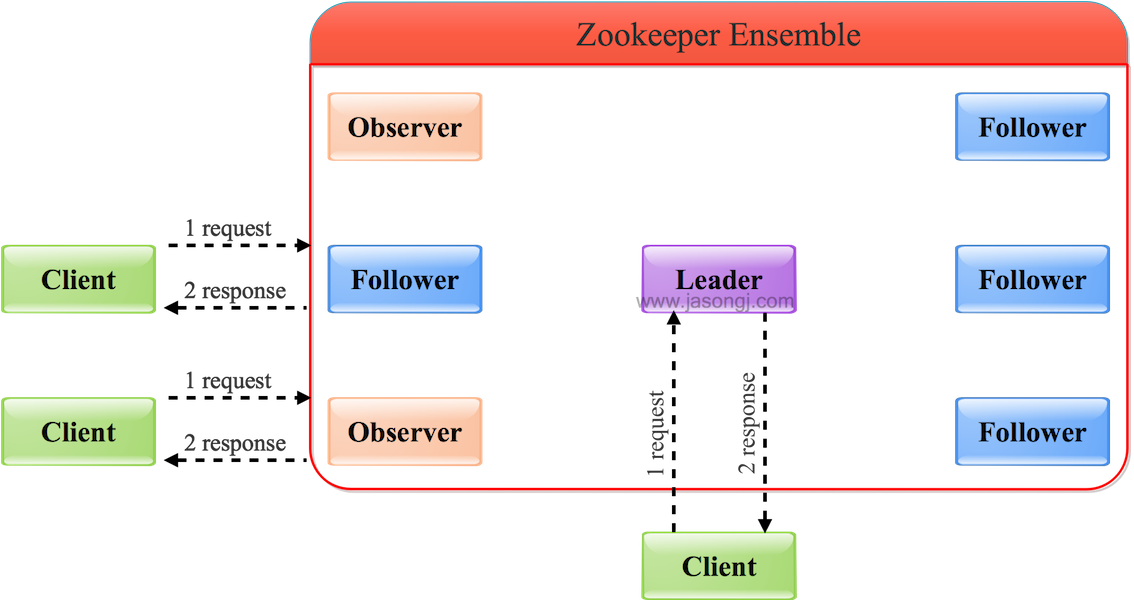
由于處理讀請求不需要服務器之間的交互,Follower/Observer越多,整體可處理的讀請求量越大,也即讀性能越好。
三、FastLeaderElection原理
1. 術語介紹
(1) myid
每個Zookeeper服務器,都需要在數據文件夾下創建一個名為myid的文件,該文件包含整個Zookeeper集群唯一的ID(整數)。例如某Zookeeper集群包含三臺服務器,hostname分別為zoo1、zoo2和zoo3,其myid分別為1、2和3,則在配置文件中其ID與hostname必須一一對應,如下所示。在該配置文件中,server.后面的數據即為myid
- server.1=zoo1:2888:3888
- server.2=zoo2:2888:3888
- server.3=zoo3:2888:3888
(2) zxid
類似于RDBMS中的事務ID,用于標識一次更新操作的Proposal ID。為了保證順序性,該zkid必須單調遞增。因此Zookeeper使用一個64位的數來表示,高32位是Leader的epoch,從1開始,每次選出新的Leader,epoch加一。低32位為該epoch內的序號,每次epoch變化,都將低32位的序號重置。這樣保證了zkid的全局遞增性。
2. 支持的領導選舉算法
可通過electionAlg配置項設置Zookeeper用于領導選舉的算法。
到3.4.10版本為止,可選項有
- 基于UDP的LeaderElection
- 基于UDP的FastLeaderElection
- 基于UDP和認證的FastLeaderElection
- 基于TCP的FastLeaderElection
在3.4.10版本中,默認值為3,也即基于TCP的FastLeaderElection。另外三種算法已經被棄用,并且有計劃在之后的版本中將它們徹底刪除而不再支持。
3. FastLeaderElection
FastLeaderElection選舉算法是標準的Fast Paxos算法實現,可解決LeaderElection選舉算法收斂速度慢的問題。
4. 服務器狀態
- LOOKING 不確定Leader狀態。該狀態下的服務器認為當前集群中沒有Leader,會發起Leader選舉
- FOLLOWING 跟隨者狀態。表明當前服務器角色是Follower,并且它知道Leader是誰
- LEADING 領導者狀態。表明當前服務器角色是Leader,它會維護與Follower間的心跳
- OBSERVING 觀察者狀態。表明當前服務器角色是Observer,與Folower唯一的不同在于不參與選舉,也不參與集群寫操作時的投票
5. 選票數據結構
每個服務器在進行領導選舉時,會發送如下關鍵信息
- logicClock 每個服務器會維護一個自增的整數,名為logicClock,它表示這是該服務器發起的第多少輪投票
- state 當前服務器的狀態
- self_id 當前服務器的myid
- self_zxid 當前服務器上所保存的數據的最大zxid
- vote_id 被推舉的服務器的myid
- vote_zxid 被推舉的服務器上所保存的數據的最大zxid
6. 投票流程
(1) 自增選舉輪次
Zookeeper規定所有有效的投票都必須在同一輪次中。每個服務器在開始新一輪投票時,會先對自己維護的logicClock進行自增操作。
(2) 初始化選票
每個服務器在廣播自己的選票前,會將自己的投票箱清空。該投票箱記錄了所收到的選票。例:服務器2投票給服務器3,服務器3投票給服務器1,則服務器1的投票箱為(2, 3), (3, 1), (1, 1)。票箱中只會記錄每一投票者的最后一票,如投票者更新自己的選票,則其它服務器收到該新選票后會在自己票箱中更新該服務器的選票。
(3) 發送初始化選票
每個服務器最開始都是通過廣播把票投給自己。
(4) 接收外部投票
服務器會嘗試從其它服務器獲取投票,并記入自己的投票箱內。如果無法獲取任何外部投票,則會確認自己是否與集群中其它服務器保持著有效連接。如果是,則再次發送自己的投票;如果否,則馬上與之建立連接。
(5) 判斷選舉輪次
收到外部投票后,首先會根據投票信息中所包含的logicClock來進行不同處理
- 外部投票的logicClock大于自己的logicClock。說明該服務器的選舉輪次落后于其它服務器的選舉輪次,立即清空自己的投票箱并將自己的logicClock更新為收到的logicClock,然后再對比自己之前的投票與收到的投票以確定是否需要變更自己的投票,最終再次將自己的投票廣播出去。
- 外部投票的logicClock小于自己的logicClock。當前服務器直接忽略該投票,繼續處理下一個投票。
- 外部投票的logickClock與自己的相等。當時進行選票PK。
(6) 選票PK
選票PK是基于(self_id, self_zxid)與(vote_id, vote_zxid)的對比
- 外部投票的logicClock大于自己的logicClock,則將自己的logicClock及自己的選票的logicClock變更為收到的logicClock
- 若logicClock一致,則對比二者的vote_zxid,若外部投票的vote_zxid比較大,則將自己的票中的vote_zxid與vote_myid更新為收到的票中的vote_zxid與vote_myid并廣播出去,另外將收到的票及自己更新后的票放入自己的票箱。如果票箱內已存在(self_myid, self_zxid)相同的選票,則直接覆蓋
- 若二者vote_zxid一致,則比較二者的vote_myid,若外部投票的vote_myid比較大,則將自己的票中的vote_myid更新為收到的票中的vote_myid并廣播出去,另外將收到的票及自己更新后的票放入自己的票箱
(7) 統計選票
如果已經確定有過半服務器認可了自己的投票(可能是更新后的投票),則終止投票。否則繼續接收其它服務器的投票。
(8) 更新服務器狀態
投票終止后,服務器開始更新自身狀態。若過半的票投給了自己,則將自己的服務器狀態更新為LEADING,否則將自己的狀態更新為FOLLOWING
四、幾種領導選舉場景
1. 集群啟動領導選舉
(1) 初始投票給自己
集群剛啟動時,所有服務器的logicClock都為1,zxid都為0。
各服務器初始化后,都投票給自己,并將自己的一票存入自己的票箱,如下圖所示。

在上圖中,(1, 1, 0)第一位數代表投出該選票的服務器的logicClock,第二位數代表被推薦的服務器的myid,第三位代表被推薦的服務器的最大的zxid。由于該步驟中所有選票都投給自己,所以第二位的myid即是自己的myid,第三位的zxid即是自己的zxid。
此時各自的票箱中只有自己投給自己的一票。
(2) 更新選票
服務器收到外部投票后,進行選票PK,相應更新自己的選票并廣播出去,并將合適的選票存入自己的票箱,如下圖所示。

服務器1收到服務器2的選票(1, 2, 0)和服務器3的選票(1, 3, 0)后,由于所有的logicClock都相等,所有的zxid都相等,因此根據myid判斷應該將自己的選票按照服務器3的選票更新為(1, 3, 0),并將自己的票箱全部清空,再將服務器3的選票與自己的選票存入自己的票箱,接著將自己更新后的選票廣播出去。此時服務器1票箱內的選票為(1, 3),(3, 3)。
同理,服務器2收到服務器3的選票后也將自己的選票更新為(1, 3, 0)并存入票箱然后廣播。此時服務器2票箱內的選票為(2, 3),(3, ,3)。
服務器3根據上述規則,無須更新選票,自身的票箱內選票仍為(3, 3)。
服務器1與服務器2更新后的選票廣播出去后,由于三個服務器最新選票都相同,最后三者的票箱內都包含三張投給服務器3的選票。
(3) 根據選票確定角色
根據上述選票,三個服務器一致認為此時服務器3應該是Leader。因此服務器1和2都進入FOLLOWING狀態,而服務器3進入LEADING狀態。之后Leader發起并維護與Follower間的心跳。

2. Follower重啟
(1) Follower重啟投票給自己
Follower重啟,或者發生網絡分區后找不到Leader,會進入LOOKING狀態并發起新的一輪投票。
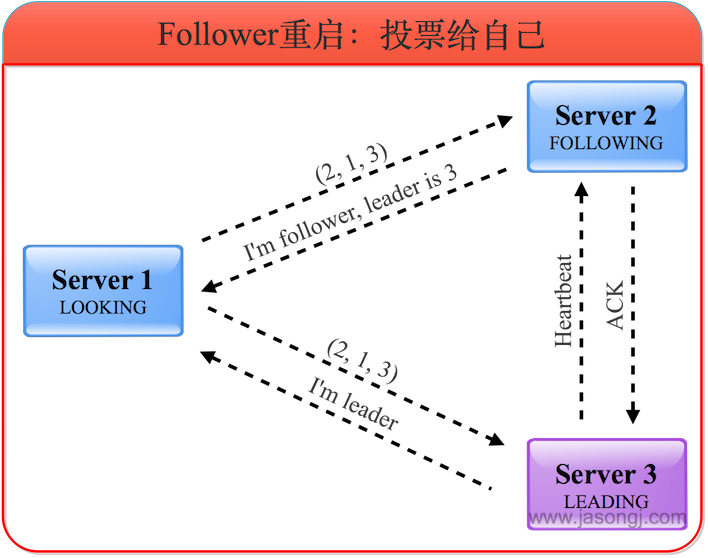
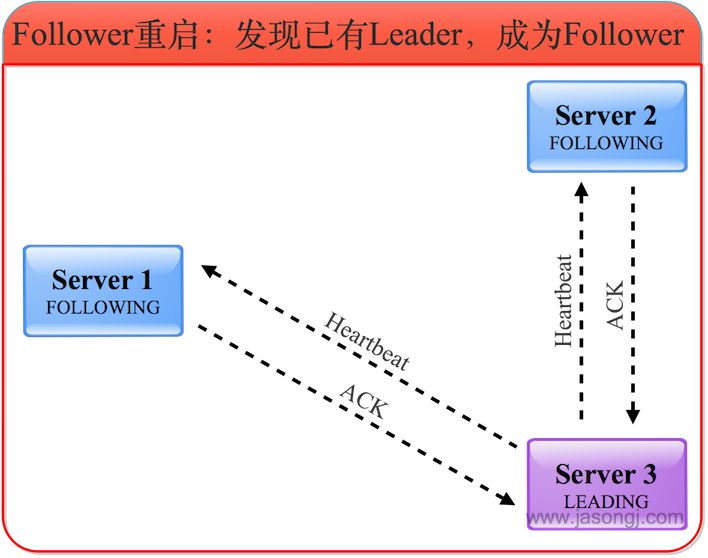
(2) 發現已有Leader后成為Follower
服務器3收到服務器1的投票后,將自己的狀態LEADING以及選票返回給服務器1。服務器2收到服務器1的投票后,將自己的狀態FOLLOWING及選票返回給服務器1。此時服務器1知道服務器3是Leader,并且通過服務器2與服務器3的選票可以確定服務器3確實得到了超過半數的選票。因此服務器1進入FOLLOWING狀態。
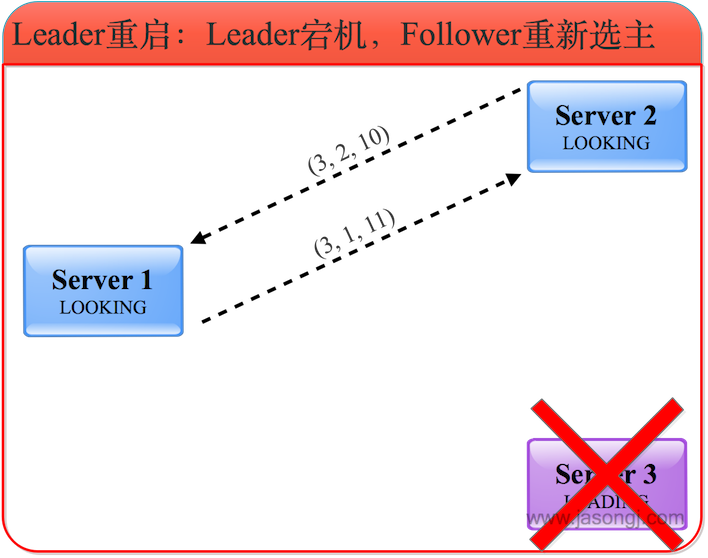
3. Leader重啟
(1) Follower發起新投票
Leader(服務器3)宕機后,Follower(服務器1和2)發現Leader不工作了,因此進入LOOKING狀態并發起新的一輪投票,并且都將票投給自己。
(2) 廣播更新選票
服務器1和2根據外部投票確定是否要更新自身的選票。這里有兩種情況
- 服務器1和2的zxid相同。例如在服務器3宕機前服務器1與2完全與之同步。此時選票的更新主要取決于myid的大小
- 服務器1和2的zxid不同。在舊Leader宕機之前,其所主導的寫操作,只需過半服務器確認即可,而不需所有服務器確認。換句話說,服務器1和2可能一個與舊Leader同步(即zxid與之相同)另一個不同步(即zxid比之小)。此時選票的更新主要取決于誰的zxid較大
在上圖中,服務器1的zxid為11,而服務器2的zxid為10,因此服務器2將自身選票更新為(3, 1, 11),如下圖所示。
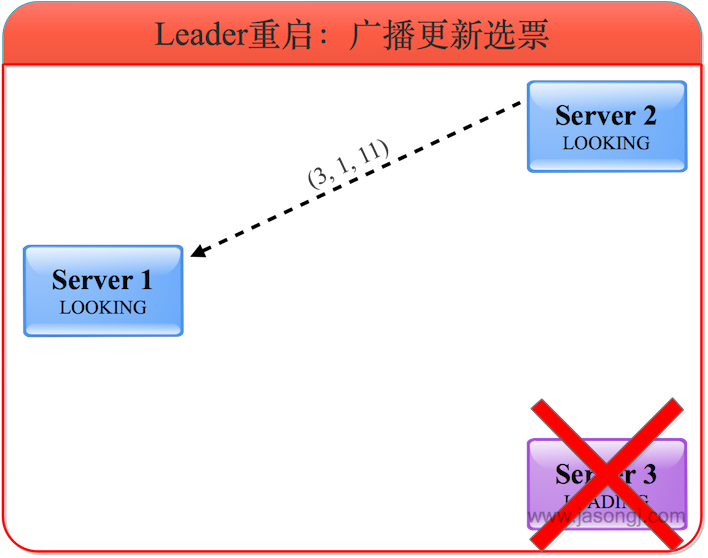
(3) 選出新Leader
經過上一步選票更新后,服務器1與服務器2均將選票投給服務器1,因此服務器2成為Follower,而服務器1成為新的Leader并維護與服務器2的心跳。
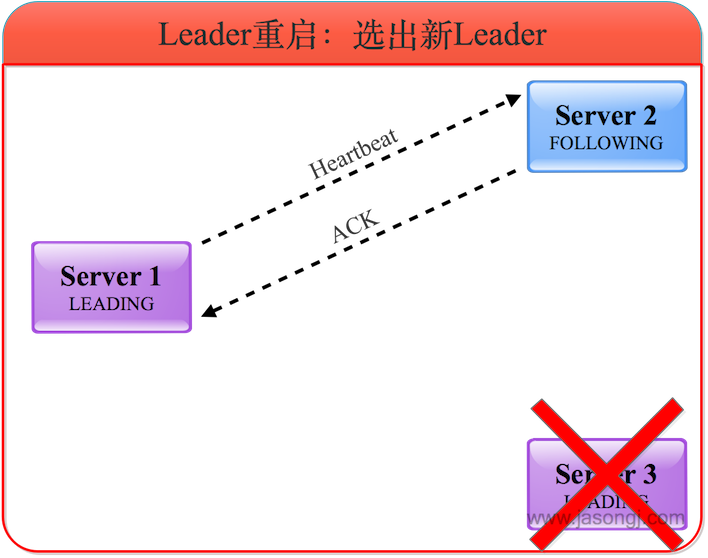
(4) 舊Leader恢復后發起選舉
舊的Leader恢復后,進入LOOKING狀態并發起新一輪領導選舉,并將選票投給自己。此時服務器1會將自己的LEADING狀態及選票(3, 1, 11)返回給服務器3,而服務器2將自己的FOLLOWING狀態及選票(3, 1, 11)返回給服務器3。如下圖所示。
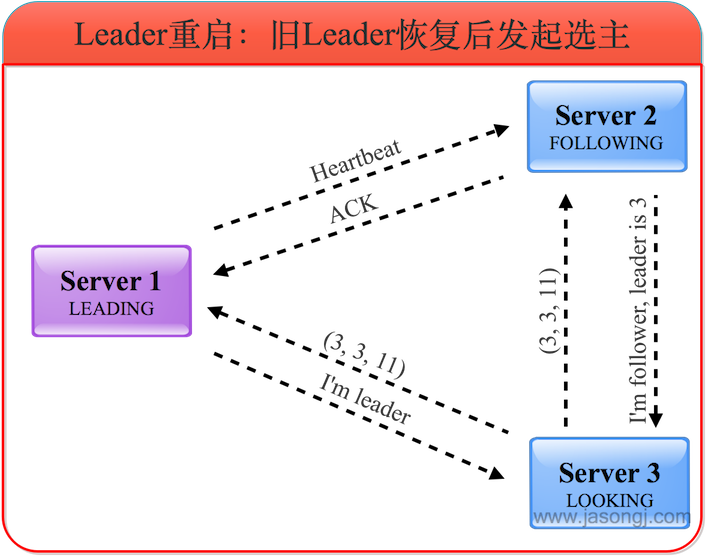
(5) 舊Leader成為Follower
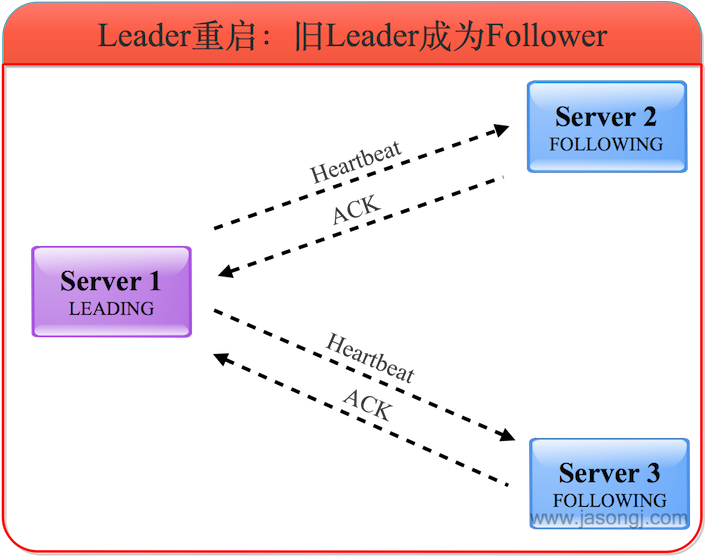
服務器3了解到Leader為服務器1,且根據選票了解到服務器1確實得到過半服務器的選票,因此自己進入FOLLOWING狀態。
五、一致性保證
ZAB協議保證了在Leader選舉的過程中,已經被Commit的數據不會丟失,未被Commit的數據對客戶端不可見。
1. Commit過的數據不丟失
(1) Failover前狀態
為更好演示Leader Failover過程,本例中共使用5個Zookeeper服務器。A作為Leader,共收到P1、P2、P3三條消息,并且Commit了1和2,且總體順序為P1、P2、C1、P3、C2。根據順序性原則,其它Follower收到的消息的順序肯定與之相同。其中B與A完全同步,C收到P1、P2、C1,D收到P1、P2,E收到P1,如下圖所示。
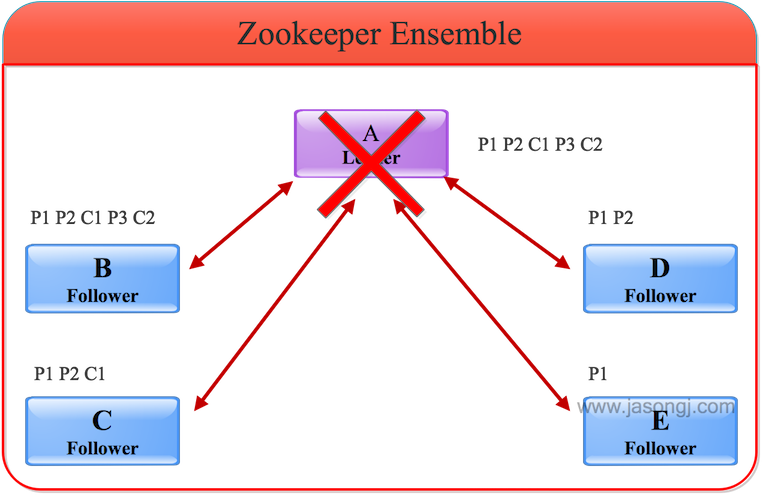
這里要注意
- 由于A沒有C3,意味著收到P3的服務器的總個數不會超過一半,也即包含A在內最多只有兩臺服務器收到P3。在這里A和B收到P3,其它服務器均未收到P3
- 由于A已寫入C1、C2,說明它已經Commit了P1、P2,因此整個集群有超過一半的服務器,即最少三個服務器收到P1、P2。在這里所有服務器都收到了P1,除E外其它服務器也都收到了P2
(2) 選出新Leader
舊Leader也即A宕機后,其它服務器根據上述FastLeaderElection算法選出B作為新的Leader。C、D和E成為Follower且以B為Leader后,會主動將自己最大的zxid發送給B,B會將Follower的zxid與自身zxid間的所有被Commit過的消息同步給Follower,如下圖所示。
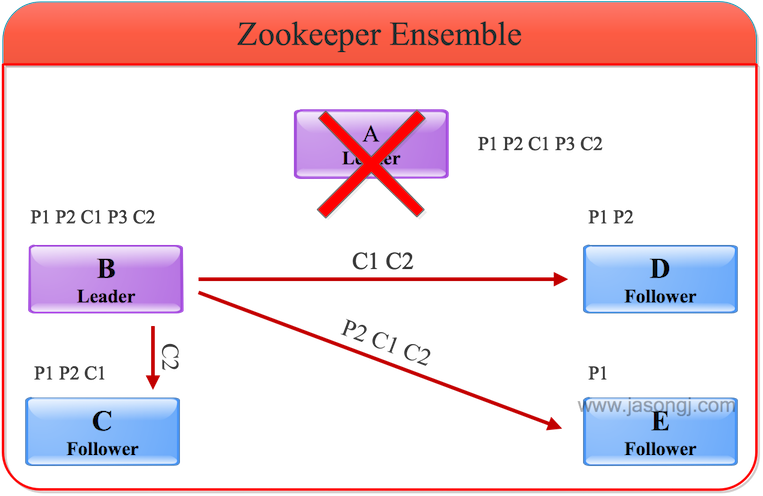
在上圖中
- P1和P2都被A Commit,因此B會通過同步保證P1、P2、C1與C2都存在于C、D和E中
- P3由于未被A Commit,同時幸存的所有服務器中P3未存在于大多數據服務器中,因此它不會被同步到其它Follower
(3) 通知Follower可對外服務
同步完數據后,B會向D、C和E發送NEWLEADER命令并等待大多數服務器的ACK(下圖中D和E已返回ACK,加上B自身,已經占集群的大多數),然后向所有服務器廣播UPTODATE命令。收到該命令后的服務器即可對外提供服務。
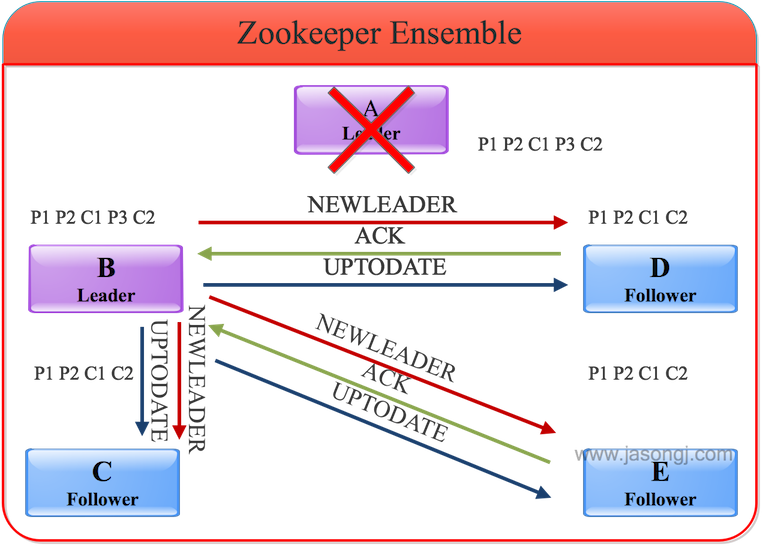
2. 未Commit過的消息對客戶端不可見
在上例中,P3未被A Commit過,同時因為沒有過半的服務器收到P3,因此B也未Commit P3(如果有過半服務器收到P3,即使A未Commit P3,B會主動Commit P3,即C3),所以它不會將P3廣播出去。
具體做法是,B在成為Leader后,先判斷自身未Commit的消息(本例中即P3)是否存在于大多數服務器中從而決定是否要將其Commit。然后B可得出自身所包含的被Commit過的消息中的最小zxid(記為min_zxid)與最大zxid(記為max_zxid)。C、D和E向B發送自身Commit過的最大消息zxid(記為max_zxid)以及未被Commit過的所有消息(記為zxid_set)。B根據這些信息作出如下操作
- 如果Follower的max_zxid與Leader的max_zxid相等,說明該Follower與Leader完全同步,無須同步任何數據
- 如果Follower的max_zxid在Leader的(min_zxid,max_zxid)范圍內,Leader會通過TRUNC命令通知Follower將其zxid_set中大于Follower的max_zxid(如果有)的所有消息全部刪除
上述操作保證了未被Commit過的消息不會被Commit從而對外不可見。
上述例子中Follower上并不存在未被Commit的消息。但可考慮這種情況,如果將上述例子中的服務器數量從五增加到七,服務器F包含P1、P2、C1、P3,服務器G包含P1、P2。此時服務器F、A和B都包含P3,但是因為票數未過半,因此B作為Leader不會Commit P3,而會通過TRUNC命令通知F刪除P3。如下圖所示。
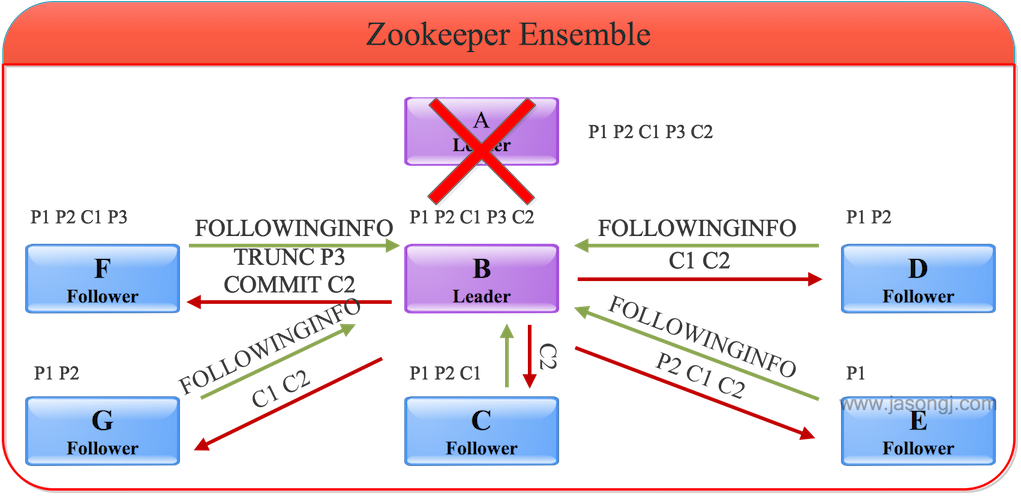
六、總結
- 由于使用主從復制模式,所有的寫操作都要由Leader主導完成,而讀操作可通過任意節點完成,因此Zookeeper讀性能遠好于寫性能,更適合讀多寫少的場景
- 雖然使用主從復制模式,同一時間只有一個Leader,但是Failover機制保證了集群不存在單點失敗(SPOF)的問題
- ZAB協議保證了Failover過程中的數據一致性
- 服務器收到數據后先寫本地文件再進行處理,保證了數據的持久性
【本文為51CTO專欄作者“郭俊”的原創稿件,轉載請聯系原作者】