深入淺出 Zookeeper 中的 ZAB 協議
ZAB 協議的全稱是 Zookeeper Atomic Broadcase,原子廣播協議。
作用:通過這個 ZAB 協議可以進行集群間主備節點的數據同步,保證數據的一致性。
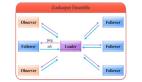
在講解 ZAB 協議之前,我們必須要了解 Zookeeper 的各節點的角色。

Zookeeper 各節點的角色
Leader:
- 負責處理客戶端發送的讀、寫事務請求。這里的事務請求可以理解這個請求具有事務的 ACID 特性。
- 同步寫事務請求給其他節點,且需要保證事務的順序性。
- 狀態為 LEADING。
Follower:
- 負責處理客戶端發送的讀請求
- 轉發寫事務請求給 Leader。
- 參與 Leader 的選舉。
- 狀態為 FOLLOWING。
Observer:
- 和 Follower 一樣,唯一不同的是,不參與 Leader 的選舉,且狀態為 OBSERING。
- 可以用來線性擴展讀的 QPS。
啟動階段,如何選 Leader?
Zookeeper 剛啟動的時候,多個節點需要找出一個 Leader。怎么找呢,就是用投票。
比如集群中有兩個節點,A 和 B,原理圖如下所示:

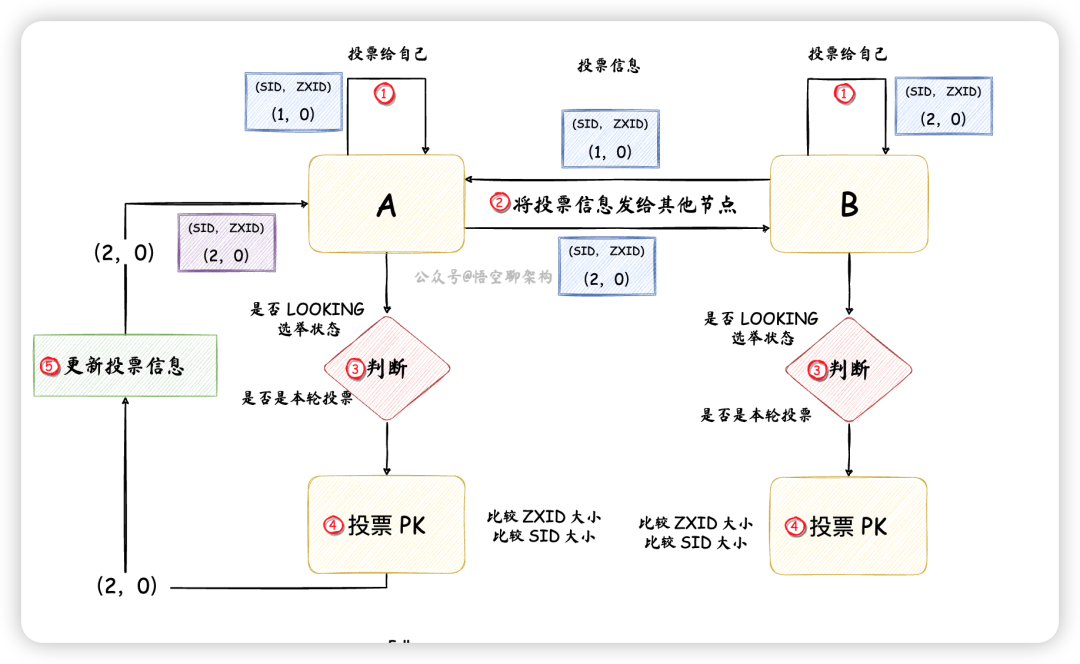
- 節點 A 先投票給自己,投票信息包含節點 id(SID) 和一個 ZXID,如 (1,0)。SID 是配置好的,且唯一,ZXID 是唯一的遞增編號。
- 節點 B 先投票給自己,投票信息為(2,0)。
- 然后節點 A 和 B 將自己的投票信息投票給集群中所有節點。
- 節點 A 收到節點 B 的投票信息后,檢查下節點 B 的狀態是否是本輪投票,以及是否是正在選舉(LOOKING)的狀態。
- 投票 PK:節點 A 會將自己的投票和別人的投票進行 PK,如果別的節點發過來的 ZXID 較大,則把自己的投票信息更新為別的節點發過來的投票信息,如果 ZXID 相等,則比較 SID。這里節點 A 和 節點 B 的 ZXID 相同,SID 的話,節點 B 要大些,所以節點 A 更新投票信息為(2,0),然后將投票信息再次發送出去。而節點 B 不需要更新投票信息,但是下一輪還需要再次將投票發出去。
這個時候節點 A 的投票信息為(2,0),如下圖所示:
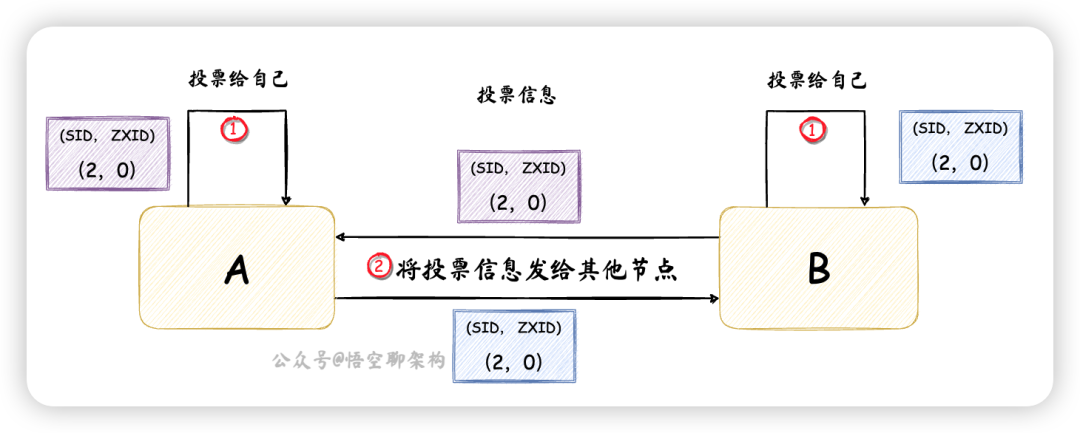
- 統計投票:每一輪投票,都會統計每臺節點收到的投票信息,判斷是否有過半的節點收到了相同的投票信息。節點 A 和 節點 B 收到的投票信息都為(2,0),且數量來說,大于一半節點的數量,所以將節點 B 選出來作為 Leader。
- 更新節點狀態:節點 A 作為 Follower,更新狀態為 FOLLOWING,節點 B 作為 Leader,更新狀態為 LEADING。
運行期間,Leader 宕機了怎么辦?
在 Zookeeper 運行期間,Leader 會一直保持為 LEADING 狀態,直到 Leader 宕機了,這個時候就要重新選 Leader,而選舉過程和啟動階段的選舉過程基本一致。
需要注意的點:
- 剩下的 Follower 進行選舉,Observer 不參與選舉。
- 投票信息中的 zxid 用的是本地磁盤日志文件中的。如果這個節點上的 zxid 較大,就會被當選為 Leader。如果 Follower 的 zxid 都相同,則 Follower 的節點 id 較大的會被選為 Leader。
節點之間如何同步數據的?
不同的客戶端可以分別連接到主節點或備用節點。
而客戶端發送讀寫請求時是不知道自己連的是Leader 還是 Follower,如果客戶端連的是主節點,發送了寫請求,那么 Leader 執行 2PC(兩階段提交協議)同步給其他 Follower 和 Observer 就可以了。但是如果客戶端連的是 Follower,發送了寫請求,那么 Follower 會將寫請求轉發給 Leader,然后 Leader 再進行 2PC 同步數據給 Follower。
兩階段提交協議:
- 第一階段:Leader 先發送 proposal 給 Follower,Follower 發送 ack 響應給 Leader。如果收到的 ack 過半,則進入下一階段。
- 第二階段: Leader 從磁盤日志文件中加載數據到內存中,Leader 發送 commit 消息給 Follower,Follower 加載數據到內存中。
我們來看下 Leader 同步數據的流程:
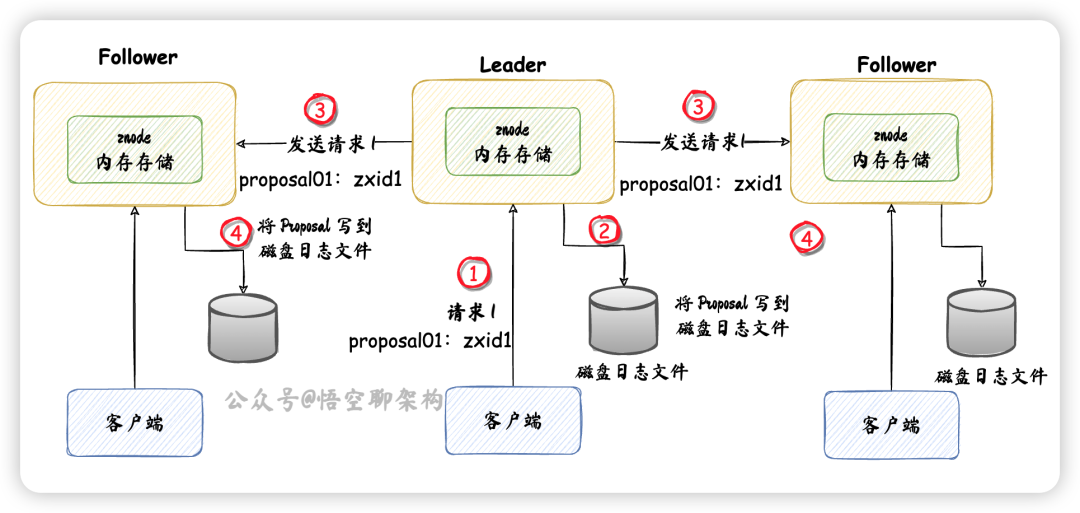
- ① 客戶端發送寫事務請求。
- ② Leader 收到寫請求后,轉化為一個 "proposal01:zxid1" 事務請求,存到磁盤日志文件。
- ③ 發送 proposal 給其他 Follower。
- ④ Follower 收到 proposal 后,Follower 寫磁盤日志文件。
接著我們看下 Follower 收到 Leader 發送的 proposal 事務請求后,怎么處理的:
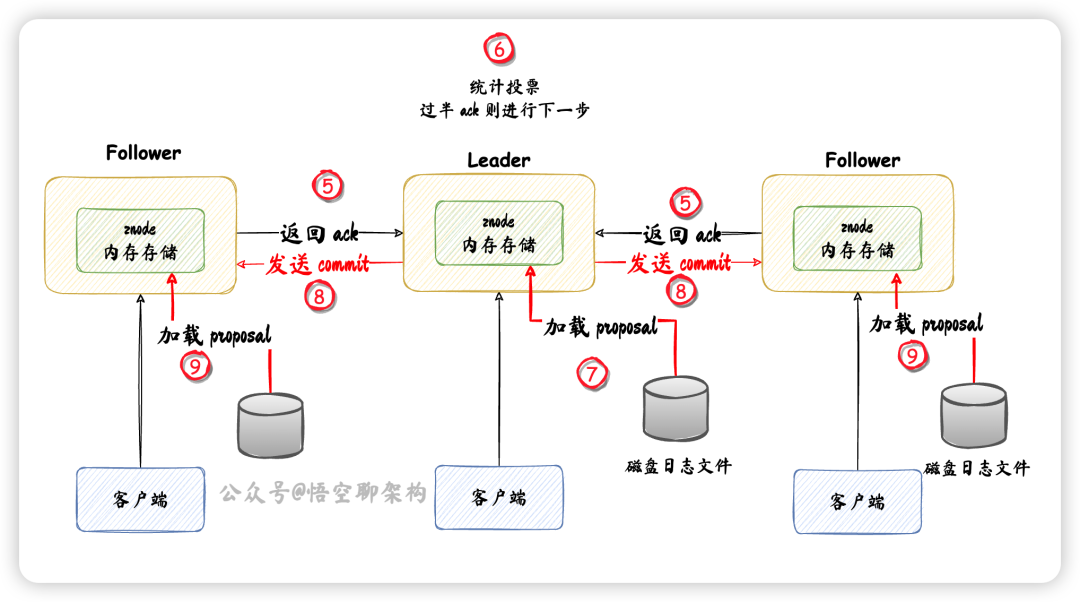
- ⑤ Follower 返回 ack 給 Leader。
- ⑥ Leader 收到超過一半的 ack,進行下一階段
- ⑦ Leader 將磁盤中的日志文件的 proposal 加載到 znode 內存數據結構中。
- ⑧ Leader 發送 commit 消息給所有 Follower 和 Observer。
- ⑨ Follower 收到 commit 消息后,將 磁盤中數據加載到 znode 內存數據結構中。
現在 Leader 和 Follower 的數據都是在內存數據中的,且是一致的,客戶端從 Leader 和 Follower 讀到的數據都是一致的。
ZAB 的順序一致性怎么做到的?
Leader 發送 proposal 時,其實會為每個 Follower 創建一個隊列,都往各自的隊列中發送 proposal。
如下圖所示是 Zookeeper 的消息廣播流程:
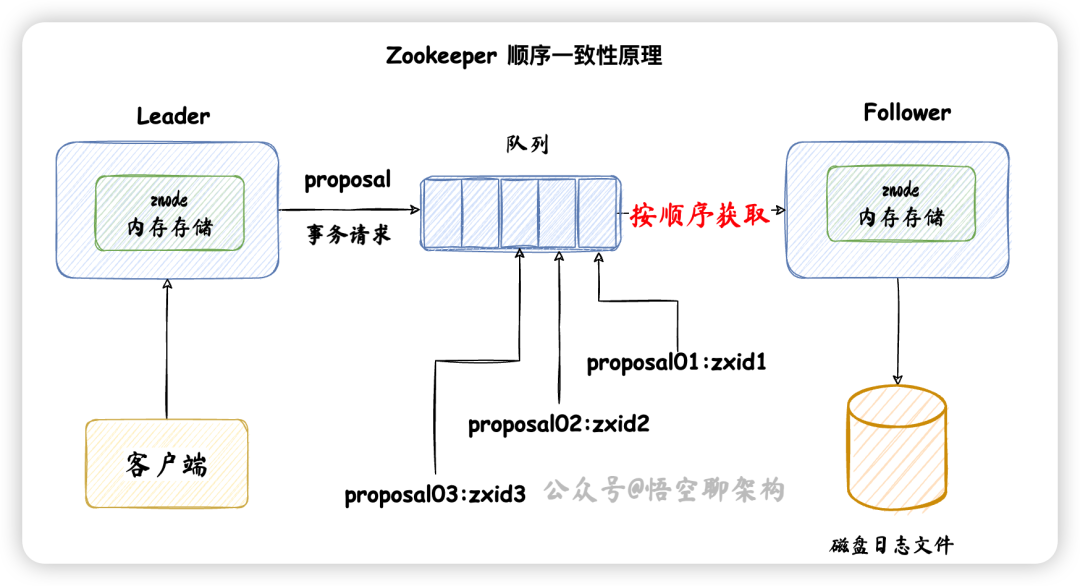
客戶端發送了三條寫事務請求,對應的 proposal 為:
proposal01:zxid1
proposal02:zxid2
proposal03:zxid3
Leader 收到請求后,依次放到隊列中,然后 Follower 依次從隊列中獲取請求,這樣就保證了數據的順序性。
Zookeeper 到底是不是強一致性?
官方定義:順序一致性。
不保證強一致性,為什么呢?
因為 Leader 再發送 commit 消息給所有 Follower 和 Observer 后,它們并不是同時完成 commit 的。
比如因為網絡原因,不同節點收到的 commit 較晚,那么提交的時間也較晚,就會出現多個節點的數據不一致,但是經過短暫的時間后,所有節點都 commit 后,數據就保持同步了。
另外 Zookeeper 支持強一致性,就是手動調用 sync 方法來保證所有節點都 commit 才算成功。
這里有個問題:如果某個節點 commit 失敗,那么 Leader 會進行重試嗎?如何保證數據的一致性?歡迎討論。
Leader 宕機數據丟失問題
第一種情況:
假設 Leader 已經將消息寫入了本地磁盤,但是還沒有發送 proposal 給 Follower,這個時候 Leader 宕機了。
那就需要選新的 Leader,新 Leader 發送 proposal 的時候,包含的 zxid 自增規律會發生一次變化:
- zxid 的高 32 位自增 1 一次,高 32 位代表 Leader 的版本號。
- zxid 的低 32 位自增 1,后續還是繼續保持自增長。
當老 Leader 恢復后,會轉成 Follower,Leader 發送最新的 proposal 給它時,發現本地磁盤的 proposal 的 zxid 的高 32 位小于新 Leader 發送的 proposal,就丟棄自己的 proposal。
第二種情況:
如果 Leader 成功發送了 commit 消息給 Follower,但是所有或者部分 Follower 還沒來得及 commit 這個 proposal,也就是加載磁盤中的 proposal 到 內存中,這個時候 Leader 宕機了。
那么就需要選出磁盤日志中 zxid 最大的 Follower,如果 zxid 相同,則比較節點 id,節點 id 大的作為 Leader。
本篇盡量用大白話+畫圖的方式進行講解,希望能給大家帶來啟發。