這些主流分布式存儲系統,你都知道嗎?
Hadoop HDFS(大數據分布式文件系統)
Hadoop分布式文件系統(HDFS)是一個分布式文件系統,適用于商用硬件上高數據吞吐量對大數據集的訪問的需求。
該系統仿效了谷歌文件系統(GFS),數據在相同節點上以復制的方式進行存儲以實現將數據合并計算的目的。
該系統的主要設計目標包括:容錯,可擴展性,高效性和可靠性。
HDFS采用了MapReduce,不遷移數據而是以將處理任務遷移到物理節點(保存數據)的方式降低網絡I/O。HDFS是Apache Hadoop的一個子項目并且安裝Hadoop。
OpenStack的對象存儲Swift
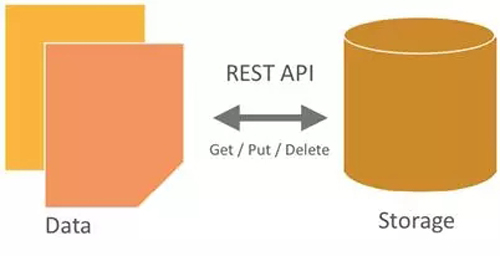
OpenStack Swift提供一個類似Amazon S3的對象存儲。其主要特點為:
- 所有的存儲對象都有自身的元數據和一個URL,這些對象在盡可能唯一的區域復制3次,而這些區域可被定義為一組驅動器,一個節點,一個機架等。
- 開發者通過一個RESTful HTTP API與對象存儲系統相互作用。
- 對象數據可以放置在集群的任何地方。
- 在不影響性能的情況下,集群通過增加外部節點進行擴展。這是相對全面升級,性價比更高的近線存儲擴展。
- 數據無需遷移到一個全新的存儲系統。
- 集群可無宕機增加新的節點。
- 故障節點和磁盤可無宕機調換。
- 在標準硬件上運行,例如戴爾,HP和Supermicro。
公有云對象存儲
公有云大都只有對象存儲。例如,谷歌云存儲是一個快速,具有可擴展性和高可用性的對象存儲。而且云存儲無需一種模式也就是圖像,視頻文件就可以存儲海量數據。
Amazon類似產品就是S3: http://aws.amazon.com/s3;
微軟類似產品Azure Bolb:http://azure.microsoft.com/en-us/documentation/articles/storage-dotnet-how-to-use-blobs/;
阿里類似的有OSS:https://www.aliyun.com/product/oss/;
Facebook用于圖片存儲的Haystack

Facebook Haystack擁有大量元數據,適用于圖片的對象存儲,采用每張圖片一個文件的方式取代NFS文件系統。
http://cse.unl.edu/~ylu/csce990/notes/HayStack_Facebook_ShakthiBachala.ppt;
此外,Facebook著眼于長尾服務,因此傳統緩存和CDN(內容發布網絡)的表現并不甚佳。一般正常的網站有99%CDN點擊量,但Facebook只有約80%CDN點擊率。
f4: Facebook的暖性BLOB存儲
Haystack最初是用于Facebook圖片應用的主要存儲系統。到2016年已有近8年的歷史。
這期間它通過比如減少磁盤數設法讀取一個BLOB到1,跨地理位置通過復制(3個復制因子即文件副本數)實現容錯等更多優化而運作良好。在此期間Facebook雖然服務良好但依然進行了演變。
截止2014年2月,Haystack存儲了約4000億張圖片。
https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-muralidhar.pdf
目前,f4存儲了超過65PB的本地BLOB,而且將其有效復制因子從3.6降低到任意2.8或2.1。
f4提供低延遲,可恢復磁盤,主機,機柜和數據中心故障并為暖性BLOB提供足夠的吞吐量。
PS:f4僅存儲“暖性”圖片
OpenStack塊存儲Cinder
OpenStack(類似商業云)還可以作為一個Linux訪問的文件系統提供傳統塊存儲。Cinder能虛擬化塊存儲設備池并向需要和消費這些資源的終端用戶提供一個自助服務API,而無需了解存儲部署的實際位置或是存儲設備的類型。
OpenStack Cinder類似于亞馬遜EBS(Elastic Block Storage )和微軟Azure Files以及谷歌Persistent Storage。
Lustre
Lustre是一個并行分布式文件系統,通常用于大規模集群計算。??它的名字取自Linux和cluster(集群)的組合詞。Lustre文件系統軟件遵循GPL2認證協議并為(各類規模)計算機集群提供高性能文件系統。
因為Lustre文件系統擁有高性能的能力和開放式認證,所以經常應用于超級計算機。
Lustre文件系統具有可擴展性,可支持在數百臺服務器上配置數萬客戶端節點,PB級容量的多個計算機集群,并超出TB級聚合I/O吞吐量。
這讓Lustre文件系統受到擁有大型數據中心企業的青睞,其中也包括例如氣象,虛擬,石油天然氣,生命科學,多功能媒體和金融行業。Lustre曾輾轉過幾家企業,最近的三個所有者(時間先后排序)依次為甲骨文,Whamcloud和英特爾。
Gluster
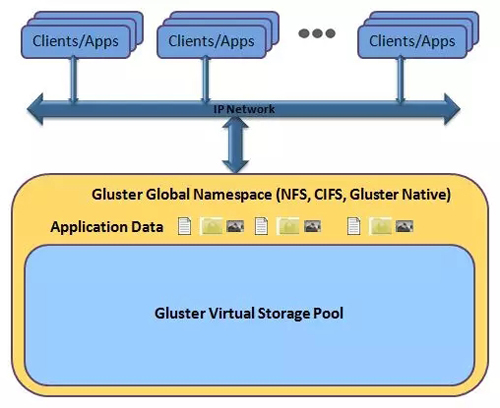
http://www.gluster.org/http://en.wikipedia.org/wiki/Gluster
GlusterFS遵循Infiniband RDMA或TCP/IP協議創建塊集中存儲,在單一全局命名空間內集中磁盤和內存資源并管理數據。
對于公有云部署,GlusterFS提供了一個AWS AMI(亞馬遜機器鏡像)。它不是在物理服務器上部署,而是在Elastic Compute Cloud (EC2)實例上部署,并且地層存儲空間是Amazon的Elastic Block Storage(EBS)。
在這樣的環境里,容量通過部署更多EBS存儲設備進行擴展,性能則通過部署更多EC2實例進行增強,而可用性通過AWS可用區域之間進行多方復制來提升。
FUSE(Filesystem in Userspace 用戶空間文件系統)
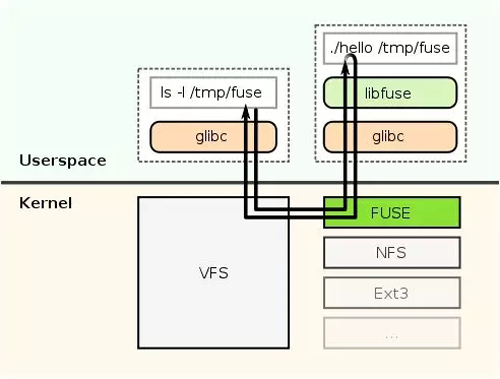
FUSE GPL/LGPL認證是一個操作系統機制,針對類Unix計算操作系統,讓用戶無需編輯內核代碼即可構建自身文件系統。這雖然是通過在用戶空間內運行文件系統代碼實現,但FUSE模塊僅提供了一個到達真正內核接口的一架“橋梁”。
FUSE最初是作為一個可加載的核心模塊來實現的,通過GlusterFS使用,尤其適用于編寫虛擬文件系統。但與傳統文件系統,尤其是可存儲數據和從磁盤上檢索數據的系統不同,虛擬文件系統檢索實際上無法存儲自身數據。它們充當一個現有文件系統或存儲設備的視圖或翻譯。
Ceph
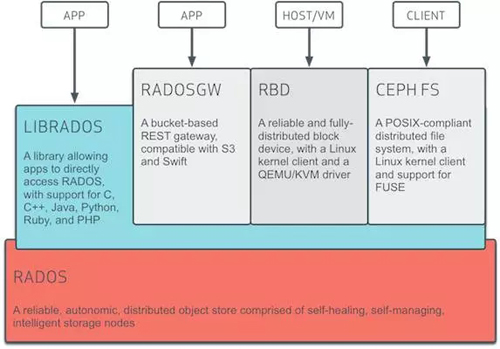
Cphe是紅帽的,Ceph是一個遵循LGPL協議的存儲平臺,它可以在單個分布式節點上同時支持對象存儲,塊存儲和文件存儲。
Cphe主要設計的初衷是變成一個可避免單節點故障的分布式文件系統,EB級別的擴展能力,而且是一種開源自由軟件,許多超融合的分布式文件系統都是基于Ceph開發的,作為開源軟件在超融合商業領域的應用,Ceph因為性能等問題被詬病,但不乏許多廠商在Ceph上不斷優化和努力。
IBM General Parallel File System(GPFS通用并行文件系統)
這個專有GPFS是一個由IBM開發的高性能集群文件系統。它可以在共享磁盤或非共享分布式并行模式中進行部署。
GPFS-SNC,其中SNC代表Shared Nothing Cluster(非共享集群),它是2012年12月正式發布的GPFS 3.5版本,如今被稱為GPFS-FPO(文件配置優化)。這讓GPFS可以在一個聯網服務器的集群上采用本地連接磁盤,而不需要配置共享磁盤的專用服務器(例如使用SAN),GPFS-FPO可充當HDFS兼容的文件系統。
GPFS時常通過調用計算集群上的MPI-IO(Message Passing Interface)進行訪問。功能包括:
分布式元數據處理。包括目錄樹。沒有單獨的“目錄控制器”或“索引服務器”管理文件系統。
對非常大的目錄進行高效索引目錄項。很多文件系統被限制在單一目錄(通常, 65536或類似的小二進制數)中的少數文件內,而GPFS并沒有這樣的限制。
分布式鎖定。該功能考慮了完整的Posix文件系統語義,包括鎖定文件進行獨占訪問。
Global Federated File System(GFFS全局聯合文件系統)
XSEDE文件系統在美國弗吉尼亞大學Genesis II項目的一部分。
GFFS的出現是源于一個對諸如文件系統的資源以一種聯合,安全,標準化,可擴展和透明化的方式進行訪問和遠程操作的需求,而無需數據所有者或應用程序開發者和用戶改變他們存儲和訪問數據的任何方式。
GFFS通過采用一個全局基于路徑的命名空間實現,例如/data/bio/file1。
在現有文件系統中的數據,無論它們是否是 Windows文件系統, MacOS文件系統,AFS,Linux或者Lustre文件系統都可以導出或鏈接到全局命名空間。
例如,一個用戶可以將它 “C” 盤上一個本地根目錄結構,C:\work\collaboration-with-Bob導出到全局命名空間,/data/bio/project-Phil,那么用戶 “C” 盤\work\collaboration-with-bob 內的文件和目錄將會受到訪問限制,用戶可以通過/data/bio/project-Bob路徑在 GFFS上訪問。
***談一下,最常見的GPFS和HDFS有什么區別?
GPFS和Hadoop的HDFS系統對比起來相當有趣,它設計用于在商用硬件上存儲類似或更大的數據——換言之就是,不配置 RAID 磁盤的數據中心和一個SAN。
HDFS還將文件分割成塊,并將它們存儲在不同的文件系統節點內。
HDFS對磁盤可靠性的依賴并不高,它可以在不同的節點內存儲塊的副本。保存單一副本塊的一個節點出現故障是小問題,可以再復制該組其它有效塊內的副本。相較而言,雖然GPFS支持故障節點恢復,但它是一個更嚴重的事件,它可能包括數據(暫時性)丟失的高風險。
GPFS支持完整的Posix文件系統語義。 HDFS和GFS(谷歌文件系統)并不支持完整的Posix語義。
GPFS跨文件系統分布它的目錄索引和其它元數據。相反, Hadoop將它們保留在主要和次要Namenode中,大型服務器必須在RAM內存儲所有的索引信息。
GPFS將文件分割成小塊。Hadoop HDFS喜歡64MB甚至更多的塊,因為這降低了Namenode的存儲需求。小塊或很多小的文件會快速填充文件系統的索引,因此限制了文件系統的大小。
說到分布式文件系統,不得不提到許多超融合廠商,一部分是基于Ceph的,還有一部分是完全自主研發的。