













一行代碼,Pandas秒變分布式,快速處理TB級數據
剛剛在Pandas上為十幾KB的數據做好了測試寫好了處理腳本,上百TB的同類大型數據集擺到了面前。這時候,你可能面臨著一個兩難的選擇:
- 繼續用Pandas?可能會相當慢,上百TB數據不是它的菜。
(ಥ_ಥ) 然而,Spark啊分布式啊什么的,學習曲線好陡峭哦~在Pandas里寫的處理腳本都作廢了好桑心哦~
別灰心,你可能真的不需要Spark了。
加州大學伯克利分校RiseLab最近在研究的Pandas on Ray,就是為了讓Pandas運行得更快,能搞定TB級數據而生的。這個DataFrame庫想要滿足現有Pandas用戶不換API,就提升性能、速度、可擴展性的需求。
研究團隊說,只需要替換一行代碼,8核機器上的Pandas查詢速度就可以提高4倍。
其實也就是用一個API替換了Pandas中的部分函數,這個API基于Ray運行。Ray是伯克利年初推出的分布式AI框架,能用幾行代碼,將家用電腦上的原型算法轉換成適合大規模部署的分布式計算應用。
Pandas on Ray的性能雖說比不上另一個分布式DataFrame庫Dask,但更容易上手,用起來和Pandas幾乎沒有差別。用戶不需要懂分布式計算,也不用學一個新的API。
與Dask不同的是,Ray使用了Apache Arrow里的共享內存對象存儲,不需要對數據進行序列化和復制,就能跨進程通訊。
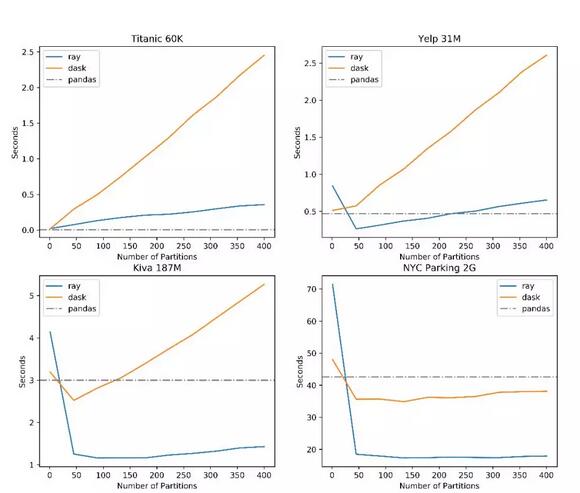
在8核32G內存的AWS m5.2xlarge實例上,Ray、Dask和Pandas讀取csv的性能對比
它將Pandas包裹起來并透明地把數據和計算分布出去。用戶不需要知道他們的系統或者集群有多少核,也不用指定如何分配數據,可以繼續用之前的Pandas notebook。
前面說過,使用Pandas on Ray需要替換一行代碼,其實就是換掉導入語句。
- # import pandas as pd
- import ray.dataframe as pd
這時候你應該看到:
初始化完成,Ray自動識別了你機器上可用的核心,接下來的用法,就和Pandas一樣了。
Pandas on Ray目前還處于早期,實現了Pandas的一部分功能。以一個股票波動的數據集為例,它所支持的Pandas功能包括檢查數據、查詢上漲的天數、按日期索引、按日期查詢、查詢股票上漲的所有日期等等。
這個項目的最終目標是在Ray上完整實現Pandas API的功能,讓用戶可以在云上用Pandas。
目前,伯克利RiseLab的研究員們已經用45天時間,實現了Pandas DataFrame API的25%。
革命尚未成功,項目仍在繼續。這些人都在為之努力:
Devin Petersohn, Robert Nishihara, Philipp Moritz, Simon Mo, Kunal Gosar, Helen Che, Harikaran Subbaraj, Peter Veerman, Rohan Singh, Joseph Gonzalez, Ion Stoica, Anthony Joseph
- 更深入地了解Pandas on Ray請看RiseLab博客原文:https://rise.cs.berkeley.edu/blog/pandas-on-ray/
- 試用Pandas on Ray請參考這個文檔:https://rise.cs.berkeley.edu/blog/pandas-on-ray/
- 給Ray團隊提要求請到GitHub開issue:https://github.com/ray-project/ray/issues
- 如果對Ray感興趣,可以讀一讀他們的論文:https://arxiv.org/abs/1712.05889


















