













一行代碼將Pandas加速4倍
導(dǎo)讀
雖然Pandas的功能非常強(qiáng)大,但是對于大數(shù)據(jù)集來說,確實是很慢的。
雖然 panda 是 Python 中用于數(shù)據(jù)處理的庫,但它并不是真正為了速度而構(gòu)建的。了解一下新的庫 Modin,Modin 是為了分布式 panda 的計算來加速你的數(shù)據(jù)準(zhǔn)備而開發(fā)的。
Pandas是處理 Python 數(shù)據(jù)的首選庫。它易于使用,并且在處理不同類型和大小的數(shù)據(jù)時非常靈活。它有大量的函數(shù),使得操縱數(shù)據(jù)變得輕而易舉。
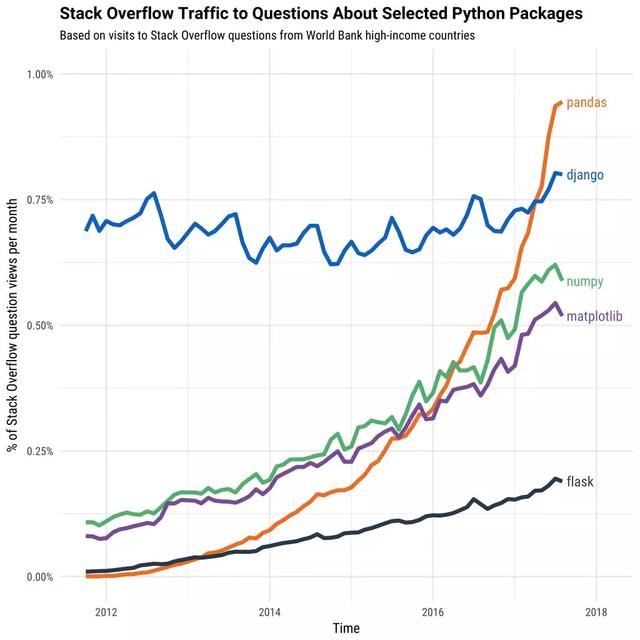
隨著時間的推移,各種Python包的流行程度
但是有一個缺點:對于較大的數(shù)據(jù)集來說,panda“慢”。
默認(rèn)情況下,panda 使用單個 CPU 內(nèi)核作為單個進(jìn)程執(zhí)行其函數(shù)。這對于較小的數(shù)據(jù)集工作得很好,因為你可能不會注意到速度上的差異。但是,隨著數(shù)據(jù)集越來越大,計算量越來越大,如果只使用單個 cpu 核,速度會受到很大的影響。它在數(shù)據(jù)集上同一時間只能計算一次,但該數(shù)據(jù)集可以有數(shù)百萬甚至數(shù)十億行。
然而,大多數(shù)用于數(shù)據(jù)科學(xué)的現(xiàn)代機(jī)器都有至少 2 個 CPU 核。這意味著,以 2 個 CPU 核為例,在使用 pandas 時,50%或更多的計算機(jī)處理能力在默認(rèn)情況下不會執(zhí)行任何操作。當(dāng)你使用 4 核(現(xiàn)代 Intel i5)或 6 核(現(xiàn)代 Intel i7)時,情況會變得更糟。pandas 的設(shè)計初衷并不是為了有效利用這種計算能力。
Modin是一個新的庫,通過在系統(tǒng)所有可用的 CPU 核上自動分配計算來加速 pandas。有了它,對于任何尺寸的 pandas 數(shù)據(jù)數(shù)據(jù)集,Modin 聲稱能夠以 CPU 內(nèi)核的數(shù)量得到近乎線性的加速。
讓我們看看它是如何工作的,并通過一些代碼示例進(jìn)行說明。
Modin 如何用 Pandas 并行計算
給定 pandas 中的 DataFrame ,我們的目標(biāo)是以盡可能快的方式對其執(zhí)行某種計算或處理。可以用*.mean()取每一列的平均值,用groupby對數(shù)據(jù)進(jìn)行分組,用drop_duplicates()*刪除所有重復(fù)項,或者使用其他任何內(nèi)置的 pandas 函數(shù)。
在前一節(jié)中,我們提到了 pandas 如何只使用一個 CPU 核進(jìn)行處理。自然,這是一個很大的瓶頸,特別是對于較大的 DataFrames,計算時就會表現(xiàn)出資源的缺乏。
理論上,并行計算就像在每個可用的 CPU 核上的不同數(shù)據(jù)點上應(yīng)用計算一樣簡單。對于一個 pandas 的 DataFrame,一個基本的想法是將 DataFrame 分成幾個部分,每個部分的數(shù)量與你擁有的 CPU 內(nèi)核的數(shù)量一樣多,并讓每個 CPU 核在一部分上運行計算。最后,我們可以聚合結(jié)果,這是一個計算上很 cheap 的操作。
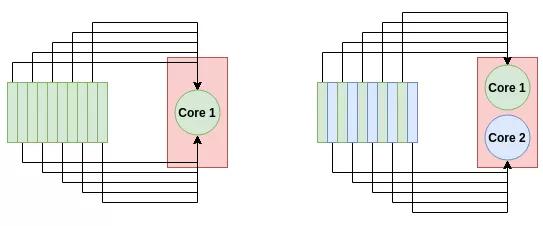
多核系統(tǒng)如何更快地處理數(shù)據(jù)。對于單核進(jìn)程(左),所有10個任務(wù)都放在一個節(jié)點上。對于雙核進(jìn)程(右圖),每個節(jié)點承擔(dān)5個任務(wù),從而使處理速度加倍。
這正是 Modin 所做的。它將 DataFrame 分割成不同的部分,這樣每個部分都可以發(fā)送到不同的 CPU 核。Modin 在行和列之間劃分 DataFrame。這使得 Modin 的并行處理可擴(kuò)展到任何形狀的 DataFrame。
想象一下,如果給你一個列多行少的 DataFrame。有些庫只執(zhí)行跨行分區(qū),在這種情況下效率很低,因為我們的列比行多。但是對于 Modin 來說,由于分區(qū)是跨兩個維度進(jìn)行的,所以并行處理對于所有形狀的數(shù)據(jù)流都是有效的,不管它們是更寬的(很多列)、更長的(很多行),還是兩者都有。
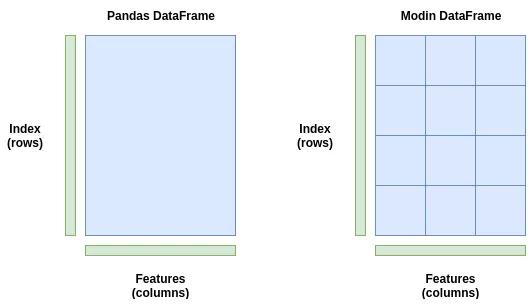
panda的DataFrame(左)存儲為一個塊,只發(fā)送到一個CPU核。Modin的DataFrame(右)跨行和列進(jìn)行分區(qū),每個分區(qū)可以發(fā)送到不同的CPU核上,直到用光系統(tǒng)中的所有CPU核。
上面的圖是一個簡單的例子。Modin 實際上使用了一個“分區(qū)管理器”,它可以根據(jù)操作的類型改變分區(qū)的大小和形狀。例如,可能有一個操作需要整個行或整個列。在這種情況下,“分區(qū)管理器”將以它能找到的最優(yōu)方式執(zhí)行分區(qū)和分配到 CPU 核上。它是非常靈活的。
為了在執(zhí)行并行處理時完成大量繁重的工作,Modin 可以使用 Dask 或 Ray。它們都是使用 Python api 的并行計算庫,你可以選擇一個或另一個在運行時與 Modin 一起使用。Ray 目前是最安全的一個,因為它更穩(wěn)定 —— Dask 后端是實驗性的。
已經(jīng)有足夠的理論了。讓我們來看看代碼和速度基準(zhǔn)測試!
Modin 速度基準(zhǔn)測試
安裝 Modin 的最簡單的方法是通過 pip。下面的命令安裝 Modin、Ray 和所有相關(guān)的依賴項:
- pip install modin[ray]
對于我們下面的例子和 benchmarks,我們使用了 Kaggle 的 CS:GO Competitive Matchmaking Data。CSV 的每一行都包含了 CS:GO 比賽中的一輪數(shù)據(jù)。
現(xiàn)在,我們嘗試使用最大的 CSV 文件(有幾個),esea_master_dmg_demo .part1.csv,它有 1.2GB。有了這樣的體量,我們應(yīng)該能夠看到 pandas 有多慢,以及 Modin 是如何幫助我們加速的。對于測試,我使用一個 i7-8700k CPU,它有 6 個物理內(nèi)核和 12 個線程。
我們要做的第一個測試是使用 read_csv()讀取數(shù)據(jù)。Pandas 和 Modin 的代碼是完全一樣的。
- ### Read in the data with Pandasimport pandas as pds = time.time()df
- = pd.read_csv("esea_master_dmg_demos.part1.csv")e =
- time.time()print("Pandas Loading Time = {}".format(e-s))### Read in
- the data with Modinimport modin.pandas as pds = time.time()df =
- pd.read_csv("esea_master_dmg_demos.part1.csv")e =
- time.time()print("Modin Loading Time = {}".format(e-s))
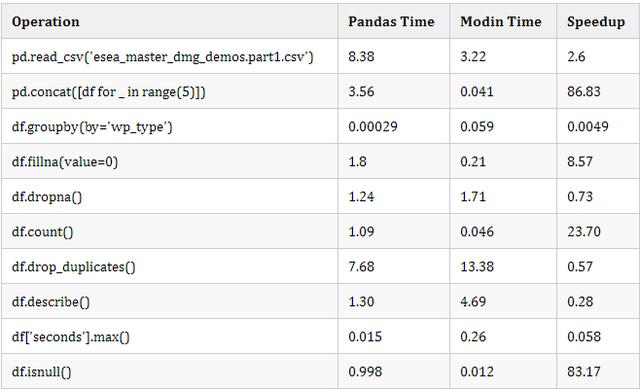
為了測量速度,我導(dǎo)入了time模塊,并在read_csv()之前和之后放置了一個time()。panda 將數(shù)據(jù)從 CSV 加載到內(nèi)存需要 8.38 秒,而 Modin 需要 3.22 秒。這是 2.6 倍的加速。對于只修改 import 語句來說,這不算太寒酸!
讓我們在 DataFrame 上做一些更復(fù)雜的處理。連接多個 DataFrames 是 panda 中的一個常見操作 — 我們可能有幾個或多個包含數(shù)據(jù)的 CSV 文件,然后必須一次讀取一個并連接它們。我們可以使用 panda 和 Modin 中的*pd.concat()*函數(shù)輕松做到這一點。
我們希望 Modin 能夠很好地處理這種操作,因為它要處理大量的數(shù)據(jù)。代碼如下所示。
- import pandas as pddf =
- pd.read_csv("esea_master_dmg_demos.part1.csv")s = time.time()df =
- pd.concat([df for _ in range(5)])e = time.time()print("Pandas Concat
- Time = {}".format(e-s))import modin.pandas as pddf =
- pd.read_csv("esea_master_dmg_demos.part1.csv")s = time.time()df =
- pd.concat([df for _ in range(5)])e = time.time()print("Modin Concat
- Time = {}".format(e-s))
在上面的代碼中,我們將 DataFrame 與自身連接了 5 次。pandas 在 3.56 秒內(nèi)完成了連接操作,而 Modin 在 0.041 秒內(nèi)完成,速度提高了 86.83 倍!看起來,即使我們只有 6 個 CPU 核心,DataFrame 的分區(qū)也有助于提高速度。
用于 DataFrame 清洗的 panda 函數(shù)是*.fillna()*函數(shù)。此函數(shù)查找 DataFrame 中的所有 NaN 值,并將它們替換為你選擇的值。panda 必須遍歷每一行和每一列來查找 NaN 值并替換它們。這是一個應(yīng)用 Modin 的絕佳機(jī)會,因為我們要多次重復(fù)一個非常簡單的操作。
- import pandas as pddf =
- pd.read_csv("esea_master_dmg_demos.part1.csv")s = time.time()df =
- df.fillna(value=0)e = time.time()print("Pandas Concat Time =
- {}".format(e-s))import modin.pandas as pddf =
- pd.read_csv("esea_master_dmg_demos.part1.csv")s = time.time()df =
- df.fillna(value=0)e = time.time()print("Modin Concat Time =
- {}".format(e-s))
這次,Pandas 運行*.fillna()*用了 1.8 秒,而 Modin 用了 0.21 秒,8.57 倍的加速!
警告!
Modin 總是這么快嗎?
并不是這樣。
在有些情況下,panda 實際上比 Modin 更快,即使在這個有 5,992,097(近 600 萬)行的大數(shù)據(jù)集上也是如此。下表顯示了我進(jìn)行的一些實驗中 panda 與 Modin 的運行時間。
正如你所看到的,在某些操作中,Modin 要快得多,通常是讀取數(shù)據(jù)并查找值。其他操作,如執(zhí)行統(tǒng)計計算,在 pandas 中要快得多。
使用 Modin 的實用技巧
Modin 仍然是一個相當(dāng)新的庫,并在不斷地發(fā)展和擴(kuò)大。因此,并不是所有的 pandas 功能都被完全加速了。如果你在 Modin 中嘗試使用一個還沒有被加速的函數(shù),它將默認(rèn)為 panda,因此不會有任何代碼錯誤或錯誤。
默認(rèn)情況下,Modin 將使用計算機(jī)上所有可用的 CPU 內(nèi)核。在某些情況下,你可能希望限制 Modin 可以使用的 CPU 內(nèi)核的數(shù)量,特別是如果你希望在其他地方使用這種計算能力。我們可以通過 Ray 中的初始化設(shè)置來限制 Modin 可以訪問的 CPU 內(nèi)核的數(shù)量,因為 Modin 在后端使用它。
- import rayray.init(num_cpus=4)import modin.pandas as pd
在處理大數(shù)據(jù)時,數(shù)據(jù)集的大小超過系統(tǒng)上的內(nèi)存(RAM)的情況并不少見。Modin 有一個特殊的標(biāo)志,我們可以設(shè)置為“true”,這將使其進(jìn)入“out of core”模式。這意味著 Modin 將使用你的磁盤作為你的內(nèi)存溢出存儲,允許你處理比你的 RAM 大得多的數(shù)據(jù)集。我們可以設(shè)置以下環(huán)境變量來啟用此功能:
- export MODIN_OUT_OF_CORE=true
總結(jié)
這就是使用 Modin 加速 panda 函數(shù)的指南。只需修改 import 語句就可以很容易地做到這一點。希望你發(fā)現(xiàn) Modin 至少在一些情況下對加速 panda有用。


























