













數據科學速成課:給Python新手的實操指南

大數據文摘作品
編譯:王夢澤、丁慧、笪潔瓊、Aileen
數據科學團隊在持續穩定的發展壯大,這也意味著經常會有新的數據科學家和實習生加入團隊。我們聘用的每個數據科學家都具有不同的技能,但他們都具備較強的分析背景和在真正的業務案例中運用此背景的能力。例如,團隊中大多數人都曾研究計量經濟學,這為概率論及統計學提供了堅實的基礎。
典型的數據科學家需要處理大量的數據,因此良好的編程技能是必不可少的。然而,我們的新數據科學家的背景往往是各不相同的。編程環境五花八門,因此新的數據科學家的編程語言背景涵蓋了R, MatLab, Java, Python, STATA, SPSS, SAS, SQL, Delphi, PHP to C# 和 C++。了解許多不同的編程語言在有些時候確實很有必要,然而我們更希望使用一種編程語言來完成大多數的項目,這樣我們可以在項目上更容易的進行合作。由于無人知曉一切,一種***的編程語言讓我們有機會互相學習。
我們公司更傾向于使用Python。在開源社區的大力支持下,Python已經成為了處理數據科學強有力的工具。Python容易使用的語法,強大的數據處理能力和極好的開源統計庫,例如Numpy, Pandas, Scikit-learn, Statsmodels等,使我們可以完成各種各樣的任務,范圍從探索性分析到構建可伸縮的大數據管道和機器學習算法。只有對那些較寬松的統計模型我們有時會將Python和R結合使用,其中Python執行大量的數據處理工作和R進行統計建模。
我的理念是通過實踐來學習,因此為了幫助新數據科學家使用Python進行數據科學研究,我們創建了Python數據科學(速成)課(Python Data Science (Crash) Course)。這門課的目標是使我們的新員工(也包括其他部門的同事)以互動的方式和自己的節奏來學習解決實際的業務問題。與此同時,更有經驗的數據科學家可以回答任何問題,但也不要小看從StackOverflow或者圖書館的文檔中尋找答案的的技能,我們也當然愿意向新數據科學家傳授這項技能!
在文章中,我們會按階段來介紹這個實踐課程。
階段一:學習Python的基礎知識
顯而易見,***步是學習Python這個軟件,即學習Python語法及基本操作。幸運的是,如果你能處理好代碼縮進的話,Python語法就不沒那么難了。我在使用Java編程語言時無需考慮注意縮進問題,然而當我之后開始使用Python時在縮進上容易出錯。
因此,如何開始學習Python?由于我們更喜歡通過實踐來學習的方式,所以我們總是讓新員工從Codecademy Python課程開始。Codecademy提供了交互式的Python課程體驗,無需擔心安裝軟件會麻煩,可以在瀏覽器中直接學習使用Python。
Codecademy Python課程用時大約13個小時,完成之后,你應該能夠在Python中進行簡單的操作。
提示:數據科學家還可以在Codecademy上學習SQL,這門課程也十分重要。

階段二:在Anaconda環境下本地安裝Python
在結束了Codecademy課程后,我們顯然會想去開始編寫自己的代碼,然而因為我們不繼續在瀏覽器中運行Python,需要在我們本地電腦上安裝Python。
Python是開源的,并可通過www.python.org.免費下載。然而官方版本只包含了標準的Python庫,標準庫中包含文本文件、日期時間和基本算術運算之類的函數。Python標準庫不夠全面,無法進行多樣化的數據科學分析,但開源社區已經創建出了很棒的庫來擴展Python的功能,使其能夠進行數據科學研究。
為了避免單獨下載安裝所有的庫,我建議使用Anaconda Python發行版。Anaconda實際上是與大量的庫結合在一起的Python,因此你不需要手動安裝它們。此外,Anaconda附帶了一個簡單的命令行工具,在必要時安裝新的或更新現有的庫。
提示:盡管默認情況下Anaconda幾乎涵蓋了所有很棒的庫,但還有一些沒有包含在內。你可以通過conda install package_name or pip install package_name語句來安裝新的包。例如,我們經常在項目中使用進度條庫 tqdm。因此,我們需要先執行pip install tqdm語句來完成Anaconda的新安裝。

階段三:使用PyCharm進行簡單的編碼
安裝了Python之后,我們可以在本地電腦上運行Python代碼。打開編輯器寫下Python代碼,打開命令行并運行新創建的Python文件,路徑為python C:\Users\thom\new_file.py。
為了使事情變得簡單一些,我更喜歡在Pychanm環境中編寫Python代碼。PyCharm是一種所謂的集成開發環境,對開發人員編寫代碼時提供支持。它可以處理常規任務,例如通過提供一個簡單的運行腳本按鈕來運行程序,此外它還可以通過提供自動完成功能和實時錯誤檢查來提高效率。如果忘記了某處的空格或使用了未被定義的變量名稱,PyCharm會發出警告提示。想要使用版本控制系統例如Git來進行項目合作?PyCharm會幫助你。不管怎樣,使用Pycham可以在編寫Python程序時節省大量的時間,charm名副其實。

階段四:解決一個模擬的業務問題
1. 定義研究的問題
假設現在經理提出了一個他面對的業務問題,他希望能夠預測用戶在公司網站上進行***點擊/參與(例如訂閱簡報)的概率。在給出了一些想法后,我們提出可以基于用戶的頁面瀏覽量來預測訂閱轉換概率,此外,你構建了以下假設:更多的頁面瀏覽量會導致用戶***訂閱的概率增大。
為了檢驗假設是否成立,我們需要從網絡分析師處獲得兩個數據集:
(1) Session數據集 包含所有用戶的所有頁面瀏覽量。
- user_id: 用戶標識符
- session_number: 會話數量(升序排列)
- session_start_date: 會話的開始日期時間
- unix_timestamp: 會話的開始unix時間標記
- campaign_id: 將用戶帶到網站的活動的ID
- domain: 用戶在會話中訪問的(子)域
- entry: 會話的進入頁面
- referral: 推薦網站,例如:google.com
- pageviews: 會話期間的頁面訪問量
- transactions: 會話期間的交易量
(2) Engagement數據集 包含所有用戶的所有參與活動。
- user_id:唯一的用戶標識符
- site_id: 產生參與活動的網站ID
- engagement_unix_timestamp: 發生參與活動的unix時間標記
- engagement_type: 參與活動的類型,例如訂閱簡報
- custom_properties: 參與活動的其他屬性
不幸的是,我們有兩個單獨的數據集,因為它們來自不同的系統。然而,兩個數據集可以通過唯一用戶標識符user_id來匹配。我已經在GitHub上放置了我用來解決業務問題的最終代碼 ,然而我強烈建議你僅在自己解決了這個問題后再去查看代碼。此外,你還可以找到創建兩個虛構數據集的代碼。
代碼鏈接:
https://github.com/thomhopmans/themarketingtechnologist/tree/master/7_data_science_in_python
2. 使用Pandas進行簡單的數據處理
無論我們應用任何統計模型解決問題,都需要預先清洗和處理數據。例如,我們需要為會話數據集中的每個用戶找到其***活動的數據(如果有的話)。這就要求在user_id上加入兩個數據集,并刪除***活動后的其他所有活動數據。
Codecademy Python課程已經告訴你如何逐行閱讀文本文件。Python非常適合數據管理和預處理,但不適用于數據分析和建模。
Python的Pandas庫克服了這個問題。Pandas提供了(數值)表和時間序列的數據結構和操作。因此,Pandas讓Python數據科學工作變得更加簡單!
3. 使用pd.read_csv()讀取數據集
我們的Python代碼中的***步是加載Python中的兩個數據集。Pandas提供了一個簡單易用的函數來讀取.csv文件:read_csv()。本著學習的原則,我們建議您自己找出如何讀取這兩個數據集。***,你應該建立兩個獨立的DataFrames,每個數據集都需要有一個。
小貼士:在這兩個文件中,我們都有不同的分隔符。此外,請務必查看read_csv()中的date_parser選項,將UNIX時間標記轉換為正常的日期時間格式。
4. 過濾無用數據
任何(大)數據問題中的下一步是減少問題規模的大小。在我們的例子中,有很多與我們問題無關的列,例如會話的媒介/來源。因此,我們在Dataframes上應用索引和選擇只保留相關的列,比如user_id(必需加入這兩個DataFrames),每個會話和活動的日期(在此之前搜索***活動和會話)以及頁面訪問量(假設驗證的必要條件)。
另外,我們會篩選出DataFrame中所有非***的活動。可以通過查找每個user_id的最早日期來完成。具體怎樣做呢?使用GroupBy:split-apply-combine邏輯!
Pandas***大的操作之一是合并,連接和序列化表格。它允許我們執行任何從簡單的左連接和合并到復雜的外部連接。因此,可根據用戶的唯一標識符結合會話和***活動的DataFrames。
5. 刪除***活動后的所有會話
在上一步中使用簡單的合并,我們為每個會話添加了***活動的時間標記。通過比較會話時間標記與***活動時間標記,你應該能夠過濾掉無用的數據并縮小問題的規模。
6. 添加因變量y:參與/訂閱活動轉換
如上所述,我們希望預測頁面訪問量對轉換(即***活動)概率的影響。因此,我們的因變量y是一個二進制變量,用它表示會話內是否發生了轉換。由于我們做了上面的過濾(即在***活動后刪除所有非***活動和會話),所以這種轉換按照定義在每個用戶的最近一次會話中進行。同樣,使用GroupBy:split-apply-combine邏輯,我們可以創建一個包含觀察值的新列,如果它是用戶的***一個會話,觀察值將為1,否則為0。
7. 添加自變量X:訪問量的累計總和
我們的自變量是頁面訪問量。但是,我們不能簡單地將會話中的頁面訪問量計算在內,因為早期會話中的頁面訪問會影響轉換概率。因此,我們創建一個新的列,用來計算用戶頁面訪問量的累計總和。這才是我們的自變量X。
8. 使用StatsModels擬合邏輯回歸
通過Pandas庫我們最終得到了一個包含單個離散X列和單個二進制Y列的小型DataFrame。并用(二元)邏輯回歸模型來估計基于一個或多個獨立變量的因變量的二元響應概率。StatsModels是Python的統計和計量經濟學庫,提供了參數估計和統計測試工具。因此,它包含邏輯回歸函數也就不足為奇了。那么,如何通過StatsModels來擬合邏輯回歸模型呢?請自行百度...
技巧1:不要忘記給邏輯回歸添加一個常數。
技巧2:另一個非常棒的擬合統計模型(如邏輯回歸)庫是scikit-learn。
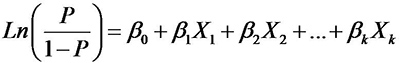
9. 使用Matplotlib或Seaborn進行可視化
在擬合邏輯回歸模型之后,我們可以預測每個累計訪問量的轉換概率。但是,我們不能僅僅通過交付一些原始數據來將我們***發現的結果傳達給管理層。因此,數據科學家的重要任務之一就是要清晰有效地展示他的成果。在大多數情況下,這意味著提供我們的可視化結果,因為眾所周知,一圖勝千言...
Python包含幾個非常棒的可視化庫,其中MatplotLib是最知名的。而Seaborn是建立在MatplotLib上的另一個很棒的庫。
MatplotLib的語法大概是以前使用過MatLab的用戶所熟知的。但是,我們傾向選擇Seaborn,是因為它提供更漂亮的圖表而且外觀很重要。
我們通過Seaborn得到了模型擬合的可視化結果,如下所示:

我們可以很好地利用這個可視化結果來證明我們的假設是否成立。
10. 驗證假設
***一步是就驗證我們提出的假設是否成立。回想一下,我們認為更多的網頁訪問量導致***活動的可能性更高。
首先,我們從以前的可視化結果中可以看出,假設是成立的。不然,預測的概率也不會單調遞增。盡管如此,我們還是可以從擬合的模型總結中得出同樣的結論,如下所示。
- Logit Regression Results
- ==============================================================================
- Dep. Variable: is_conversion No. Observations: 12420
- Model: Logit Df Residuals: 12418
- Method: MLE Df Model: 1
- Date: Tue, 27 Sep 2016 Pseudo R-squ.: 0.3207
- Time: 21:44:57 Log-Likelihood: -5057.6
- converged: True LL-Null: -7445.5
- LLR p-value: 0.000
- ====================================================================================
- coef std err z P>|z| [95.0% Conf. Int.]
- ------------------------------------------------------------------------------------
- const -3.8989 0.066 -59.459 0.000 -4.027 -3.770
- pageviews_cumsum 0.2069 0.004 52.749 0.000 0.199 0.215
- ====================================================================================
我們看到,統計結果中,pagesviews_cumsum系數在顯著性水平為1%時顯示為正。因此,這足以表明我們的假設成立,加油!此外,您剛剛已經完成了***個Python數據科學分析工作!:)
是不是感覺很棒?快上手試試吧!
原文鏈接:
https://www.themarketingtechnologist.co/helping-our-new-data-scientists-start-in-python-a-guide-to-learning-by-doing/
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】
















