如何可視化卷積網絡分類圖像時關注的焦點
你在訓練神經網絡進行圖片分類時,有沒有想過網絡是否就是像人類感知信息一樣去理解圖像?這個問題很難回答,因為多數情況下深度神經網絡都被視作黑箱。我們喂給它輸入數據進而得到輸出。整個流程如果出現問題很難去調試。盡管預測的已經相當精準,但這并不能說明他們足以和人類感知的方式媲美。
為何會這樣?
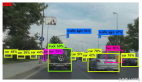
假設你需要對大象和企鵝進行二分類(我知道這個任務十分簡單)。現在你已經獲取了數據集,訓好了模型并完成部署。這個模型想必是適用于絕大多數數據的,但是總有可能會出現誤判。有人可能會把它看作是一個極端情況,但是你覺得對于 CNN 來說,什么時候物體才是明確可辨的?
結合上述內容,顯然在圖像中,大象常伴著草木出現,企鵝常伴著冰雪出現。所以,實際上模型已經學會了分辨草木與冰雪的顏色/形狀,而不是真的學會了按對象分類。
由上文案例知,如顏色通道統計那樣的簡單圖像處理技術,與訓練模型是一樣的。因為在沒有智能的情況下,模型只能依靠顏色辯物。現在你或許會問,如何知道 CNN 究竟在尋找什么?答案就是,Grad-CAM。
加權梯度類激活映射(Grad-CAM)
我們在本篇博客中實現了加權梯度類激活映射。首先,我們要知道這不是唯一的解決方案。原作說,
加權梯度類激活映射 (Grad-CAM) 通過任意目標概念的梯度(比如說類別「狗」的分對數甚至是「狗」這個字),將這些知識傳遞到***的卷積層進而產生一張粗略的定位圖,用于凸顯圖像中對于預測相關概念至關重要的區域。
通俗點講,我們只取最終卷積層的特征圖,然后將該特征中的每個通道通過與該通道相關的類的梯度進行加權。這種方法只不過是輸入圖像如何通過每個通道對于類的重要性來激活不同的通道,最重要的是它不需要對現有架構進行任何重訓練或更改。
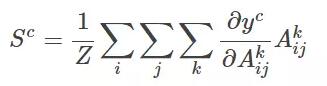
特定類的特征空間得分就是對應類的輸出值 y^c 關于特征圖 A_ij 的偏導在 i 和 j 維上的特征進行全局平均池化操作。然后,我們將結果與特征圖沿其通道軸 k 相乘。***,將結果在通道維度 k 上求平均/池化。因此,特征空間的得分凸的大小是 i×j。Σ 符號用于描述池化和平均操作。

ReLU 激活函數用于得分圖,隨后被歸一化以便輸出正區域預測
實現
為了達到本篇博客的目的,我們套用一個預訓練好的 VGG 模型,并導入一些必要包開始實現代碼。
- from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
- from keras.preprocessing import image
- import keras.backend as K
- import numpy as np
- import cv2
- import sys
我們使用 Keras 自帶的 VGG16 模型。并加載一些有助于加載和處理圖像的函數。
- model = VGG16(weights="imagenet")
- img_path = sys.argv[1]
- img = image.load_img(img_path, target_size=(224, 224))
- x = image.img_to_array(img)
- x = np.expand_dims(x, axis=0)
- x = preprocess_input(x)
我們先初始化模型并通過命令行參數加載圖片。VGG 網絡只接受 (224×224×3) 大小的圖片,所以我們要把圖片放縮到指定大小。由于我們只通過網絡傳遞一個圖像,因此需要擴展***個維度,將其擴展為一個大小為 1 的批量。然后,我們通過輔助函數 preprocess_input 從輸入圖像中減去平均 RGB 值來實現圖像的歸一化。
- preds = model.predict(x)
- class_idx = np.argmax(preds[0])
- class_output = model.output[:, class_idx]
- last_conv_layer = model.get_layer("block5_conv3")
此處,我們來看看頂部預測的特征圖。所以我們得到圖像的預測,并給得分靠前的類做個索引。請記住,我們可以為任意類計算特征圖。然后,我們可以取出 VGG16 中***一個卷積層的輸出 block5_conv3。得到的特征圖大小應該是 14×14×512。
- grads = K.gradients(class_output, last_conv_layer.output)[0]
- pooled_grads = K.mean(grads, axis=(0, 1, 2))
- iterate = K.function([model.input], [pooled_grads, last_conv_layer.output[0]])
- pooled_grads_value, conv_layer_output_value = iterate([x])
- for i in range(512):
- conv_layer_output_value[:, :, i] *= pooled_grads_value[i]
如上所述,我們計算相類輸出值關于特征圖的梯度。然后,我們沿著除了通道維度之外的軸對梯度進行池化操作。***,我們用計算出的梯度值對輸出特征圖加權。
- heatmap = np.mean(conv_layer_output_value, axis=-1)
- heatmap = np.maximum(heatmap, 0)
- heatmap /= np.max(heatmap)
然后,我們沿著通道維度對加權的特征圖求均值,從而得到大小為 14*14 的熱力圖。***,我們對熱力圖進行歸一化處理,以使其值在 0 和 1 之間。
- img = cv2.imread(img_path)
- heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
- heatmap = np.uint8(255 * heatmap)
- heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
- superimposed_img = cv2.addWeighted(img, 0.6, heatmap, 0.4, 0)
- cv2.imshow("Original", img)
- cv2.imshow("GradCam", superimposed_img)
- cv2.waitKey(0)
***,我們使用 OpenCV 來讀圖片,將獲取的熱力圖放縮到原圖大小。我們將原圖和熱力圖混合,以將熱力圖疊加到圖像上。
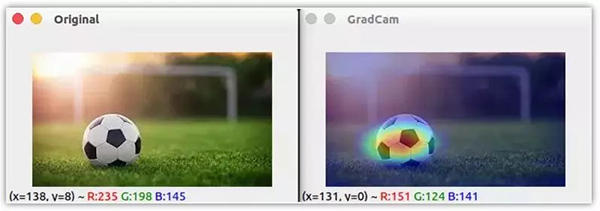
從上面的圖片可以清楚地看到 CNN 在圖像中尋找的是區分這些類的地方。這種技術不僅適用于定位,還可用于視覺問答、圖像標注等。
此外,它在調試建立精確模型的數據需求方面非常有幫助。雖然此技術并未過多涉及調參,但我們可以使用額外的數據和數據增強技術更好地泛化模型。
原文鏈接:http://www.hackevolve.com/where-cnn-is-looking-grad-cam/
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】