決策樹(shù)分類預(yù)測(cè)過(guò)程可視化
作者:王彥平
首先導(dǎo)入所需庫(kù)文件,numpy,pandas用于數(shù)值處理,DictVectorizer用于特征處理,graphviz用于模型可視化。 導(dǎo)入所需的數(shù)據(jù)文件,用于訓(xùn)練和評(píng)估模型表現(xiàn)。
開(kāi)始前的準(zhǔn)備工作
首先導(dǎo)入所需庫(kù)文件,numpy,pandas用于數(shù)值處理,DictVectorizer用于特征處理,graphviz用于模型可視化。
- #導(dǎo)入所需庫(kù)文件
- import numpy as np
- import pandas as pd
- from sklearn.feature_extraction import DictVectorizer
- from sklearn import cross_validation
- from sklearn import tree
- import graphviz
導(dǎo)入所需的數(shù)據(jù)文件,用于訓(xùn)練和評(píng)估模型表現(xiàn)。
- #導(dǎo)入數(shù)據(jù)表
- test=pd.DataFrame(pd.read_csv('TEST_ML_v2.csv',header=0,encoding='GBK'))
特征處理
第二步,對(duì)特征進(jìn)行處理。
- #特征處理
- X_df=test[['City', 'Item category', 'Period', 'Gender', 'Age', 'Market channels', 'Self-agent', 'Category', 'Loan channels']]
- X_list=X_df.to_dict(orient="records")
- vec = DictVectorizer()
- X=vec.fit_transform(X_list)
- Y=np.array(test['Status'])劃分訓(xùn)練集和測(cè)試集數(shù)據(jù)。
劃分訓(xùn)練集和測(cè)試集數(shù)據(jù)
- X_train,X_test,y_train,y_test=cross_validation.train_test_split(X.toarray(),Y,test_size=0.4,random_state=0)
訓(xùn)練模型并進(jìn)行預(yù)測(cè)
使用訓(xùn)練集數(shù)據(jù)對(duì)決策樹(shù)模型進(jìn)行訓(xùn)練,使用測(cè)試集數(shù)據(jù)評(píng)估模型表現(xiàn)。
- #訓(xùn)練模型
- clf = tree.DecisionTreeClassifier(max_depth=5)
- clf=clf.fit(X_train,y_train)
- clf.score(X_test,y_test)
- 0.85444078947368418
簡(jiǎn)單對(duì)測(cè)試集的***組特征進(jìn)行預(yù)測(cè),結(jié)果與實(shí)際值相符。
- #對(duì)測(cè)試集數(shù)據(jù)進(jìn)行預(yù)測(cè)
- clf.predict(X_test[0]),y_test[0]
- (array(['Charged Off'], dtype=object), 'Charged Off')
查看具體的分類概率值。
- #查看分類概率
- clf.predict_proba(X_test[0])
- array([[ 1., 0.]])
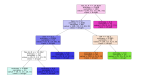
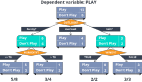
決策樹(shù)分類預(yù)測(cè)可視化
第三步,對(duì)決策樹(shù)的分類預(yù)測(cè)過(guò)程進(jìn)行可視化,首先查看分類結(jié)果及特征的名稱。
- #獲取分類名稱
- clf.classes_
- array(['Charged Off', 'Fully Paid'], dtype=object)
對(duì)決策樹(shù)進(jìn)行可視化,feature_names為特征名稱,class_names為分類結(jié)果名稱。
- #決策樹(shù)可視化
- dot_data = tree.export_graphviz(clf, out_file=None,
- feature_names=vec.get_feature_names(),
- class_names=clf.classes_,
- filled=True, rounded=True,
- special_characters=True)
- graph = graphviz.Source(dot_data)
- graph

將分類結(jié)果保存為PDF格式文檔。
- #導(dǎo)出PDF文檔
- graph.render("test_e1")
責(zé)任編輯:龐桂玉
來(lái)源:
36大數(shù)據(jù)