













機器學習新風暴:如何用ML模型預測房價?
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
從駕駛汽車到識別語音+翻譯,機器學習通過軟件預測變幻莫測的現實世界,正在人工智能領域掀起一場風暴。
所以,什么是機器學習?
機器學習是教計算機系統使用反饋的舊數據進行預測的過程,基本上是訓練計算機根據過去的數據預測未來的數據。這些預測可以很簡單,例如鑒定照片中的動物是貓還是狗,難度也可以遞進至對語音準確識別來生成網站字幕或運行視頻或音樂之類的事情。
機器學習種類
機器學習大致分為兩大類:監督學習和無監督學習。
監督學習是用示例教學機器的方法。這些機器接受了大量數據的訓練,從而學會識別圖案,并可以根據訓練數據來識別和區分數據。
而無監督學習是使用算法來識別數據集的模式,其中的數據點既未分類也未標記。算法從數據集中提取有用的信息或特征來分析其底層結構,并依此對數據進行分類。
來看看怎樣使用監督學習來構建機器學習模型。
第一步:熟悉數據
任何機器學習項目的第一步都是熟悉數據。對此可以使用Pandas庫。Pandas是數據科學家探索和處理數據的主要工具。
Pandas庫中最重要的是DataFrame。DataFrame相當于保存數據的表,類似SQL數據庫中的表。Pandas有處理DataFrame中數據的強大方法。拿加利福尼亞房價數據舉例。(文件路徑:../input/california-housing-prices/housing.csv)使用以下命令加載和瀏覽數據:
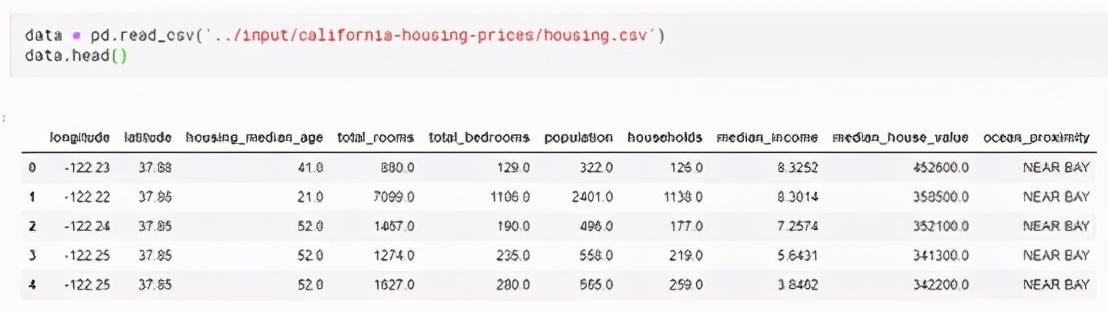
第二步:選擇建模數據
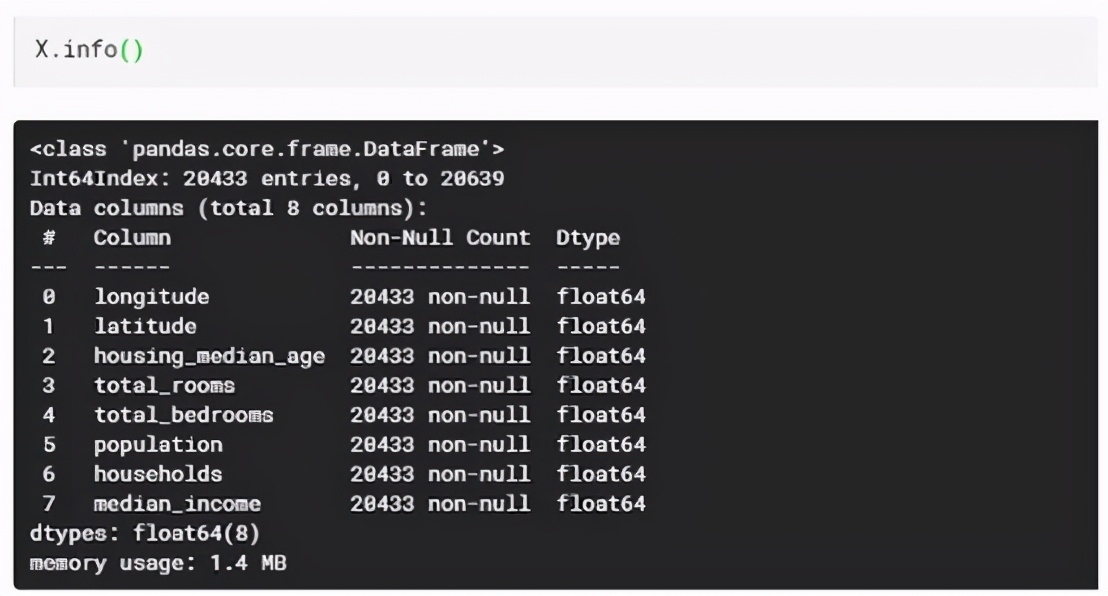
研究DataFrame的數據后會發現它有10列,其中有9列是數字數據,“Ocean proximity”一列有字符串類型數據。我們只用數字數據就可以構建任何模型,因此可以直接刪掉“Ocean proximity”列。
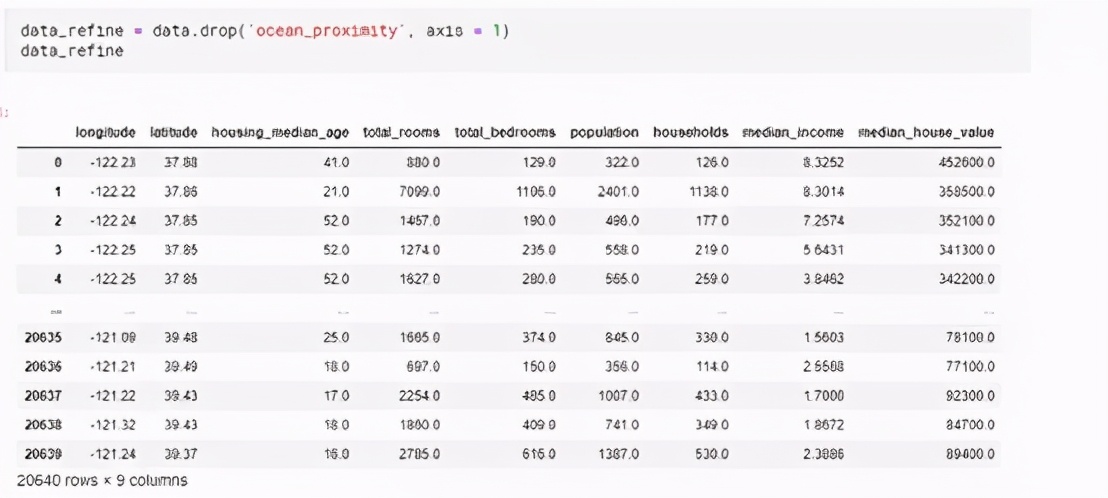
然后刪掉空值的列,如下:
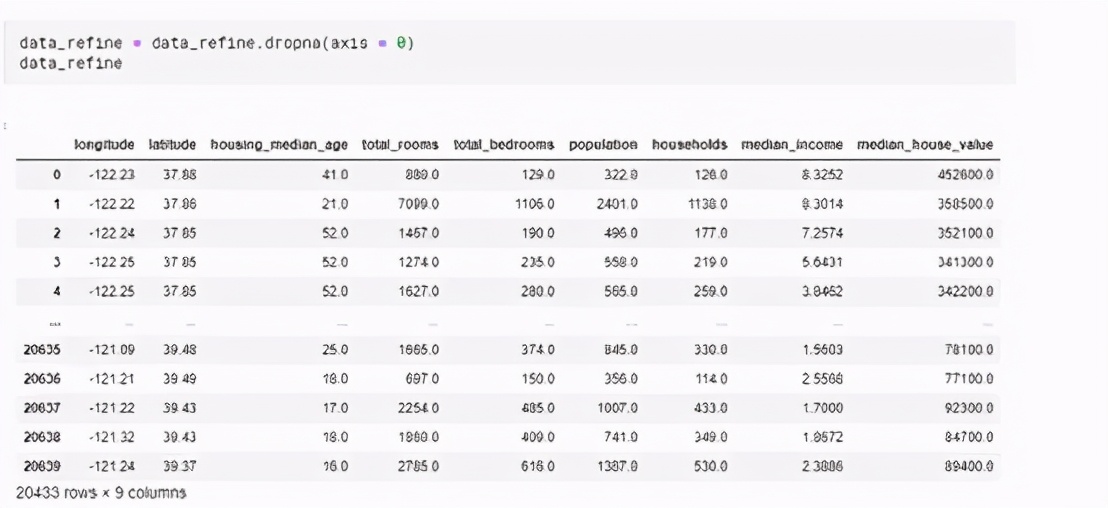
第三步:選擇預測目標(Y)和特征(X)
下一步是選擇預測目標(Y),也就是“median_house_value”列。所以分配Y為“ median_house_value”。其余特征為X。從數據集中移除“ median_house_value”列,然后將余下的分配為X,如下所示:
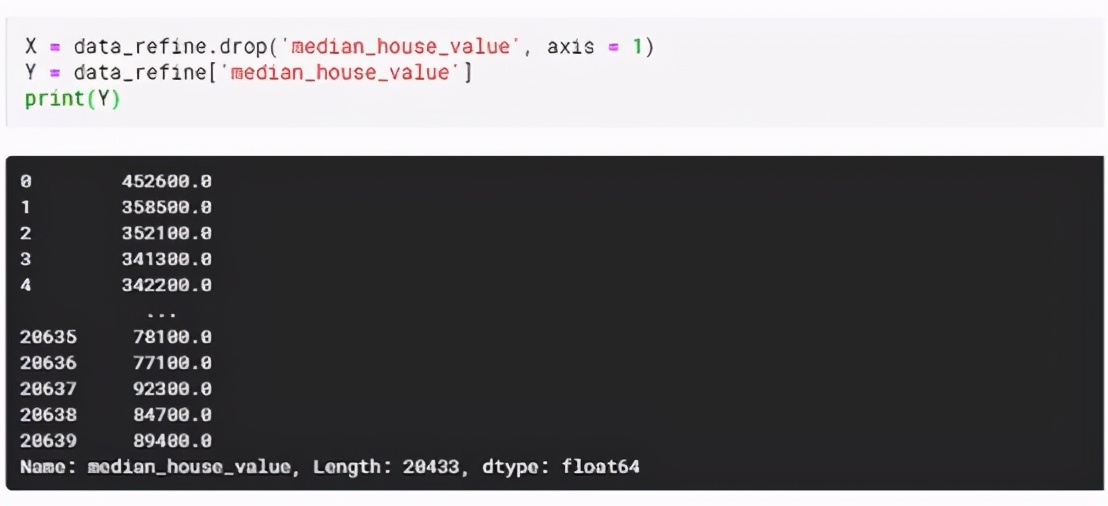
第四步:構建模型
使用scikit-learn庫創建模型。該庫在代碼中以sklearn形式編寫。當用存儲在DataFrames中的數據類型進行建模時,最受歡迎的庫就是Scikit-learn。建立和使用模型的步驟是:
- 定義:模型類型是什么?是線性回歸還是其他類型?
- 擬合:從現有數據中獲取模式(建模的核心)。
- 預測:預測目標
- 評估:確定模型預測的準確度。
現在,使用scikit-learn(sklearn)來定義線性回歸模型,并將其與特征和目標變量進行擬合,并獲得“ median_house_value”的預測值。導入以下庫使用scikit-learn(sklearn)。

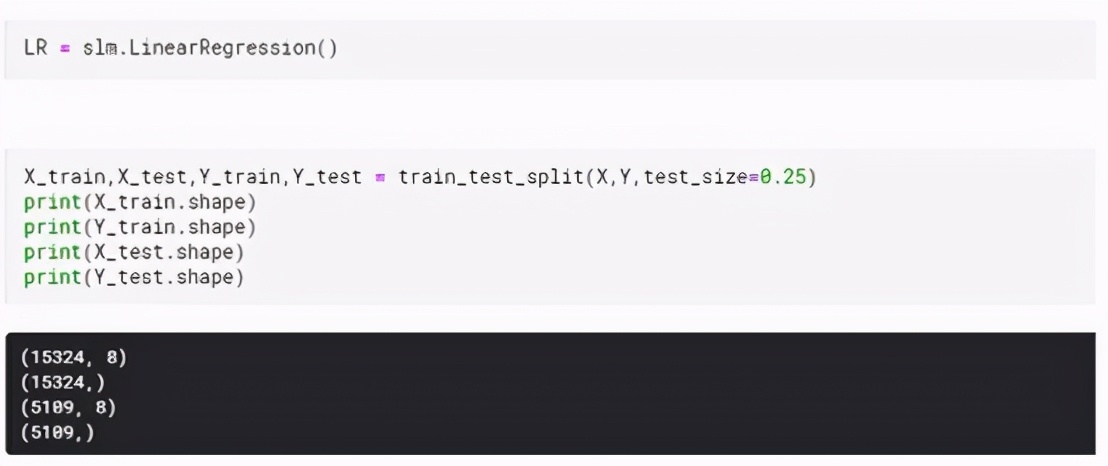
為線性回歸模型創建一個變量。并且還使用train_test_split函數將數據分為訓練和測試數據。在這里,我使用了25%的數據進行測試,而剩余的75%則用于訓練模型。
第五步:擬合模型
用訓練數據擬合線性回歸模型。

完成后,預測功能通過使用X的測試值來預測房價。然后使用得分功能通過模型獲得預測值的準確度,如下所示:
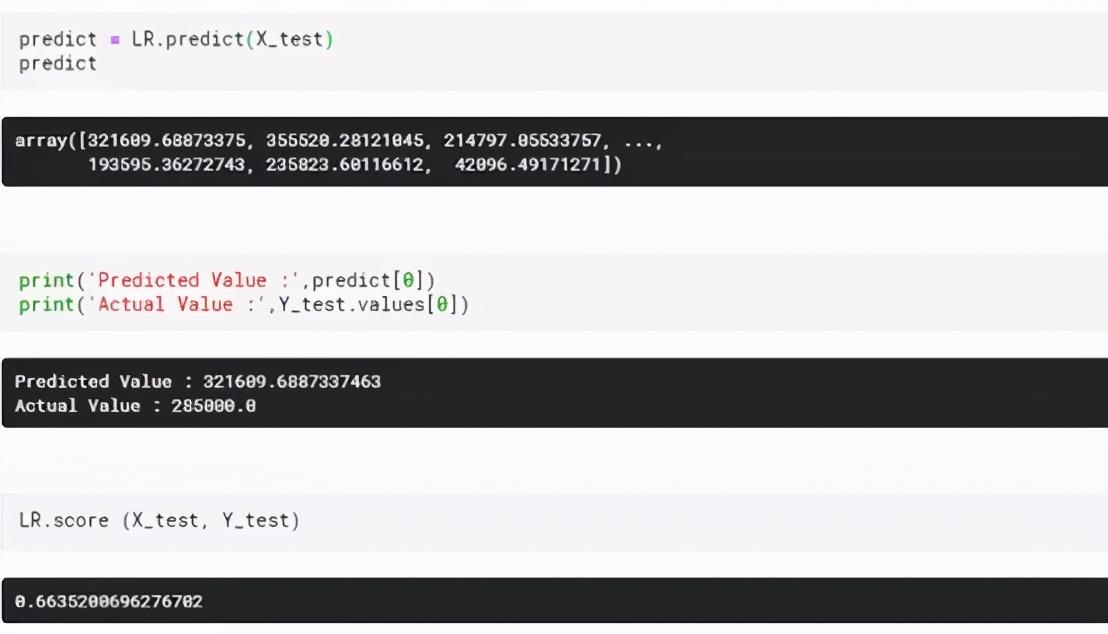
可以看到,模型預測正確率在66%左右。
第六步:畫圖
現在用X測試值和預測值(輸出)畫圖,如下:
一個擬合的模型完成啦,我們可以用它預測。實際使用時,我們可以對即將上市的新房子做預測。
本例是關于如何在數據集上擬合線性回歸模型并用來預測房價。我們還可以將相同的數據擬合到決策樹上或用來支持向量機,并比較哪種模型預測得更好。
希望本文能幫到那些正在嘗試建立第一個機器學習線性回歸模型的人。
















