運維不背鍋!持續兩年數據庫零故障的運維優化之道
大家好,我是來自平安科技數據庫技術部運維團隊的劉書安,從14年開始,配合平安集團的互聯網金融轉型,我們運維的數據庫也從單純的Oracle數據庫轉向到了多種數據庫的運維,當前管理的各類數據庫的實例已經超過了一萬個。在這種情況下,我們連續兩年保持了數據庫零故障的狀態。
事實上在之前,運維團隊也是天天忙著應付各種異常,長久處于高壓狀態下。之后經過我們團隊一系列的優化和改造,目前系統已穩定很多。這期間也確實發生了很多事情。接下來就跟大家簡單介紹一下我們這兩年對一些運維問題的分析和團隊管理的方法,拋磚引玉一下。
一、問題解決
首先我們從以下這張圖說起:
這個是扁鵲向魏王介紹他們三兄弟的醫術:扁鵲自己是在病人病入膏肓時用虎狼之藥將對方救活;扁鵲的二哥是在別人生小病時將人治愈;而扁鵲的大哥則是在病情未發時鏟除病因、避免生病。
在扁鵲看來,三個人的醫術排序應該是:大哥>二哥>扁鵲,但在世人眼里卻是:扁鵲>二哥>大哥。
我比較認同扁鵲的觀點,因為我一直都覺得DB的運維人員不應該只是背鍋俠,而是應該把自己當成醫生來對待問題,不只是關注問題的解決,更需要多關注避免問題的發生。
我們在數據庫異常時去解決問題,別人可能會認為我們是高手,能把問題解決好、事情處理掉。但實際上這時的運維已經是一個被動式的處理,即便我們用了最快的手段去解決,故障已經發生了,可能還造成了比較嚴重的影響。
如果我們能提前發現這些問題并解決掉,就能避免很多故障和影響的發生。因此在我看來,運維相對高明的手段應該是:在做架構或設計時就把能想到的問題預先解決掉,確保系統的可拓展性和高可用性。運維也應該多從架構的角度去考慮問題,并將這些問題提前解決好,而非被動地等待問題發生后才去解決。
接下來和大家介紹我們團隊解決的三個案例,以及之后我們通過什么方式避免問題的發生:
案例一
這是我們在2016年解決的案例,版本是11.2.0.4 的Oracle數據庫,這種數據庫使用SPM固化TOP SQL的執行計劃,確保系統的穩定。

當時異常的問題是,幾乎每次發完大的版本后,已有的功能都會多少受到影響,有一些語句的執行計劃會發生異常。
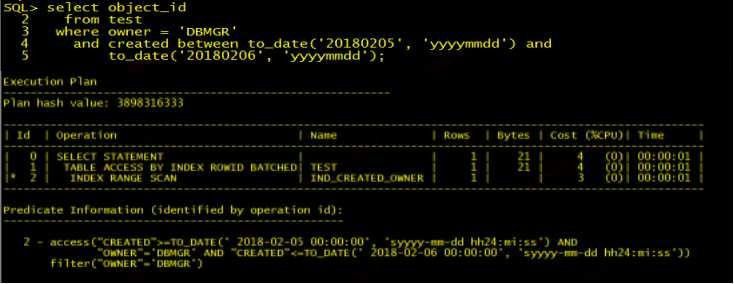
我們發現,絕大多數語句都和這個語句是類似的,中間有一個SKIPSCAN(跳躍式掃描),很明顯可以看出它是一個輸入時間(對著用戶的),有一個范圍查詢。所以我們當時就基本判斷問題出在這里了,使用的解決方案就是通過重新固化執行計劃來選擇好的執行計劃。
接著就開始分析問題產生的原因。
對于索引跳躍式掃描而言,在一般情況下,如果運維索引的***個列沒有用到,當它開始使用到第二個列時,就只能用跳躍式的方法去進行一個索引掃描。而在分析問題原因時,因為類似的語句比較多,我們當時在固化了幾十條后,發現還有源源不斷的類似語句出現,就考慮到問題可能并沒有那么簡單。所以我們又進行了進一步分析,***發現可能是索引的統計信息有問題。于是我們就重新收集了索引的統計信息,至此,類似的語句問題才算是解決了。
但其實這個問題并沒有徹底結束:
我們在處理完后又重新分析了這個索引的問題,發現索引***列是一個空值,但不知道是誰在空列和輸入時間上建了一個符合索引,導致這個索引有可能會被使用。
發現問題后,我們就查詢了這個索引的訪問方式,看看是否全都是INDEX SKIP SCAN。后來發現,基本上訪問這個索引的語句都用的是這種索引跳躍式掃描,所以我們當時就把這個索引設置為不可用,后面把它刪除了。類似的索引,我們當時處理了有三個,之后這個系統就沒有再出現這樣類似的問題。
SPM也是一種固化執行計劃的方式,但為什么在這個庫里,SPM會失效呢?
之后我們分析了它的原因:是因為每次發版本時,有可能會多查一些字段,導致語句發生變化。SPM這類的固化執行計劃的方式都和語句有強關聯,只要語句上有一個小小的改動,都會導致固化的方式失效。這也是每次更新版本語句都會發生異常的原因之一。
之后我們繼續分析,為什么這個時間索引有這種類似問題?
這是我們之前整理的一個案例分析的原因:我們在做索引的范圍查詢時,它的選擇率公式如下
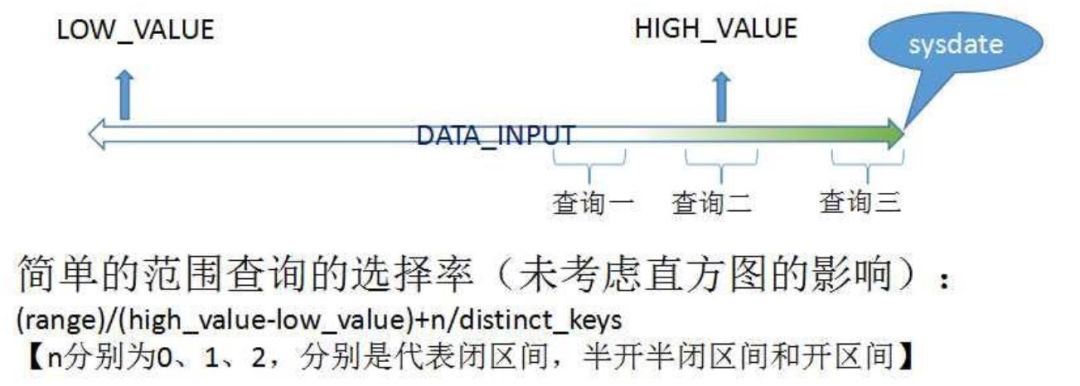
但是在不同情況下,比如這種右側索引,比如創建時間、更新時間、輸入時間,我們寫入數據都是用sysdate寫入的,那么它永遠都在索引列的右側,類似這種方式是往里面插入數據的。
然而我們統計信息的收集又不是一個實時收集的,主要是對一些大表,比如一個一千萬的表可能要到10%,也就是100萬的DMR量;更大的表的DMR量會更大。這就會導致我們的統計信息和當前的值永遠是過時的,就會產生這種問題。
對于這三個查詢來說:***個查詢發生在有效范圍內,所以它可以反映出一個比較真實的數據,第二個查詢也可以反映一部分,但第三個查詢就相當于完成一個超范圍的查詢,計算出一個很低的值,這樣就會導致我們的語句偏異常。
更坑的是在OLPP系統里,新數據查詢的幾率永遠比老數據的大,越新的數據被訪問的幾率越高,這也導致我們的語句每次都會出現異常的情況。
發現這些問題后,我們立即展開了一個行動,就是把數據庫里所有與時間索引相關的字段都提取一下,然后定期修改索引字段上面的HIGH VALUE,統計信息里面的HIGHVALUE,就能避免出現這種問題。
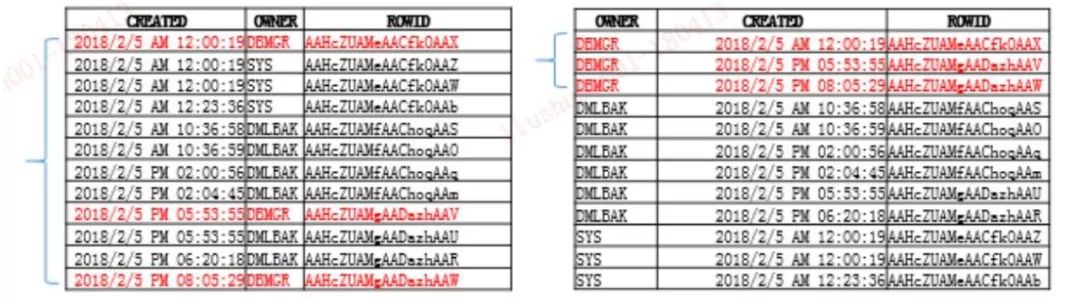
如上圖所示,是一個范圍查詢的情況,即在一個索引前導列的區別,類似于我們在創建時間和OWNER之間建索引。如果把創建時間放在前面,把OWNER放在后面就是***種情況;如果把OWNER放在前面,把CREATED放在后面就是第二種情況。
現在來分析這兩個不同索引的區別:
當我們把創建時間放在前面時,有一個很大的問題,我們通過時間字段去查詢時很難做到等值查詢,即不可能去發現每分每秒插入的值。對于這種查詢,我們一般都使用范圍查詢,比如查一個月或一天、一周的數據。所以大家可以看到,如果我在這個語句內查這一分鐘、這一天DBMGR創建的情況,在***個索引里它整個范圍都會涉及到,隨后取相關聯的三個值;但是在第二個索引里,三個值是連在一起的,因為DBMGR 是有序的,時間也是有序的,它們就可以完成只涉及到自己相關值的值。
這里面還有一些細小的區別:如果我先進行范圍查詢,后做等值查詢,對于這樣的索引,Filter時就會多做一個Filter步驟。但如果把這個順序調整一下,就不會有這種情況。所以我們在做這種符合索引創建的時候,就一定要盡量把等值查詢的放在前面。
之前有一個說法:在選擇符合索引的前導列時,要把選擇率比較低的值放在前導列。
但我們覺得這個說法是不完善的:比如對于一個時間字段而言,一天有86400秒,100天就可能有800多萬的不同值,一年會有更多不同值。可如果把這個作為前導列,有時候是不適合的,因為對它來說,有可能我們是需要查詢一天或一個月的數據,而一年有365天,或者說十二個月。因此更準確的說法應該是把查詢條件中選擇率低的列做為復合索引的前導列。
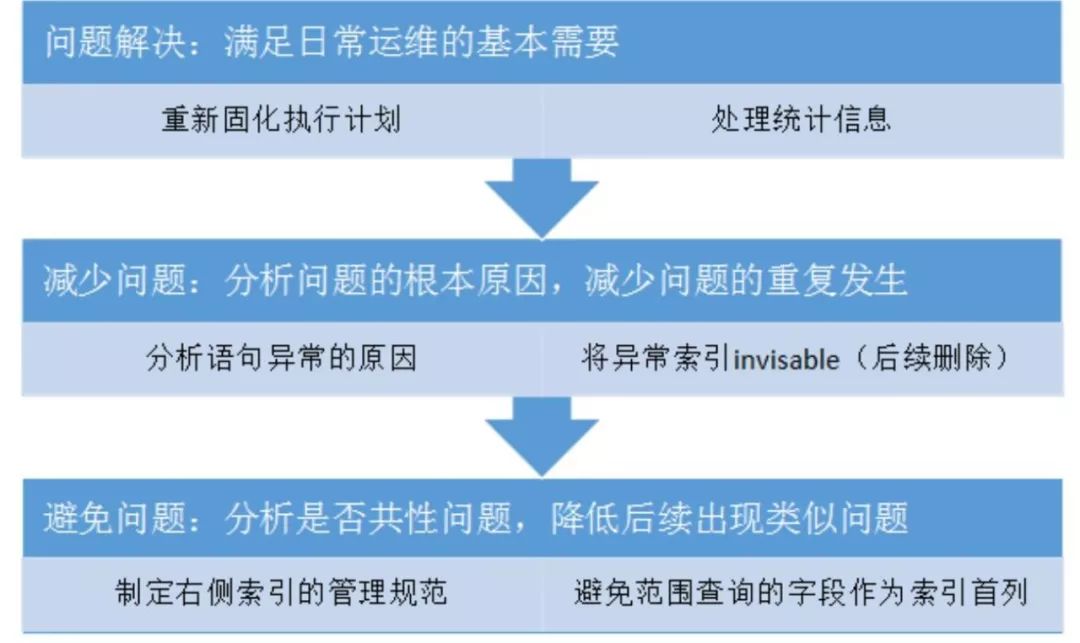
所以通過這個案例,我們就把運維問題的解決分成了三個步驟:
- ***步:快速解決問題,確保應用恢復。對于運維人員來說,恢復應用是***位的;
- 第二步:看問題是不是重復性發生的。比如前面說的案例一,如果我們當時的處理方案僅是固化執行計劃,或是收集統計信息,你沒有辦法保證它以后不會再出現類似的情況。如果我們使用的是收集統計信息的方式,可能再過一個月或兩個月,這種情況又會再次發生,所以根本的解決方案是找到這個問題發生的原因,確保這次問題解決后不會再復發;
- 第三步:避免問題,看這個問題是否屬于共性問題、其他庫里有沒有類似問題。如果有類似問題,就要形成一種規范,去避免這種問題的發生。尤其是對于一些新的應用來說,只有當你制定規范、讓開發遵守后,后續才會減少類似問題的發生,不然就會演變成我們一邊解決問題,新問題又源源不斷發生的情況,***我們只能不斷地去解決這種重復發生的問題。
我記得之前有一個案例就是共性問題:當時是在一個實際的庫里,我們分析發現它存在內存泄漏的問題,但并沒有馬上開始處理,結果第二天另一個庫也發生內存泄漏,于是我們不得不緊急重啟。
當時我們分析出問題是由某一個BUG導致后,就搜索那個BUG相關的信息,發現早在兩三年前(2014年)已經有同事解決了這個問題,只不過在另一個庫里還打了相應的PATCH來解決問題,但就是因為沒有把這個問題推廣到所有系統里,排查是否其他庫也存在這個問題而引起的。
從那之后我們就特別注意這種共性問題,如果每個系統、每個問題都要發生一次,代價實在是太大了,所以我們盡可能在發現共性問題后就解決掉,盡量排除其他庫也發生類似問題的情況。
案例二
第二個案例是一個版本為12.1.0.2的Oracle數據庫,每到晚上總會不定時地主機CPU持續到100%,應用同時會創建大量的數據到數據庫中。
當時我們的應急方案是把這種相關的等待時間全部批量Kill掉,因為這些系統是在比較核心的庫里,基本上每個系統被Kill掉的進程有幾千個,代價還是比較大的。
后來這個問題發生兩次后,我們開始著手重點分析問題,通過ASH分析發現,出現這個異常等待是因為一個很簡單的語句——SELECT USER FROM SYS.DUAL。
之后我們就通過這個語句來一步步關聯, 看到底是哪個地方調用的,結果發現是在一個應用用戶的登錄TRIGGER中的用戶判斷步驟。這個USER是Oracle的內部函數,但就是這么簡單的一個語句,就讓整個庫都Hang住了。
然后我們開始分析原因。我們通過ASH發現該語句在我們恢復應用前有重新加載的過程。當時我們懷疑是硬件導致的,就通過這種方式去分析,結果發現是在晚上10點時被Oracle的自動任務做了一個統計信息的自動收集,收集完后,又因為它是一個登錄的Trigger,用戶在不斷登錄,在做登錄解析時這個語句就沒辦法解析,所以才導致用戶源源不斷地卡在那里。而應用是需要新建連接的,新建的連接又無法進到庫里面,就會導致連接數越來越多,全都卡在那里。***我們通過鎖定dual表統計信息的收集來從根本上解決這個問題。
案例三
第三個案例有兩個問題,但后來我們發現這兩個問題是由相同的原因引起的。
我們有一個數據庫是從10.2.0.5.X升級到10.2.0.5.18版本,升級后會不定時出現cursor:pin相關的一些等待。其實出現cursor:pin是很正常的,因為這個數據庫的負載比較高,變化也較高,但問題是它是在升級之后出現的。運營認為這是升級之后出現的異常,我們就開始著手分析問題的原因。
第二個問題是我們在應急時發現的,有時異常出現時,某個庫里有些語句的執行次數會特別高,甚至15min能達到上億次,這對于一個正常的業務系統來說,出現這么高的執行頻率是不正常的。
之后我們就去分析這些問題,發現這兩個問題有相同的一些點,比如語句中間出現了個函數調用;比如說這個情況下,A表如果訪問的數據量較大時,這些函數就有可能被調用很多次。
我們發現,有一個語句,它執行一次可能會出現十幾萬次的函數調用。如果在調用的過程中,關聯的那張表的執行計劃發生了變化,比如說A表走了一個全程掃描,那可能會出現幾千萬次的函數調用。
當時我們也總結了一些關于通過什么樣的方法去快速定位、是否是函數調用導致的看法。在10g之前確實沒有什么好的辦法,因為它里面沒有一個顯示的關聯,就可能通過代碼去掃描,去找對應的語句。在11g后會比較簡單一些,通過AS值相關的TOP LEVEL SQL ID就可以直接關聯到是哪個語句調的函數導致的問題。
這里還有一個問題是函數調用。因為它調用的函數可能都是特別快的,但次數有會比較高,性能波動可能帶來比較大的影響。之前我們有一個案例就發生在月底高峰,我們當時發現某個數據庫中會出現很多CBC的等待,后來又發現有一個小表被頻繁訪問,那個小表就100多行數據,但可能它相關的語句每隔15min就調用了上千萬次。
其實這么高的并發下,出現這種CBC的等待是很正常的。不過因為它只有100多行數據,且都集中在一個數據塊里,所以才導致這個數據塊特別熱,就會一直出現這種CBC的等待。
于是我們就找辦法解決這個熱快的問題,但又因為不能在月底沖業績時停運來做修改,所以我們就想了一個方案:建一個PCT FREE 99的索引,把表所有列的數據都包含進去,確保每個索引塊里面只保留了一行數據,變相地把這100多行數據分到100多個塊里。
做了這個操作后,CBC相關的問題被解決了,也順利地撐過了業務高峰期,但是第二天月初的報表發現又掉坑里了。
因為我們在每個月月初需要上報給監管的一個報表,這種報表是屬于一個長事務,但是它在那個報表里面也是調了之前優化的那個索引,優化后的語句雖然降低高峰期CBC的等待,但因為它是要訪問100多個數據塊,單次訪問從0.25毫秒變成了1毫秒,相當于效率降低了4倍。由于報表是一種長事務的處理,相當于那個進程比原來多花了一倍多的時間也沒跑完。所以之后我們發現這個問題后,又不得不把那個索引給干掉了,讓它恢復原來那種狀態。
尤其是現在對IT的要求越來越高,時限的要求也越來越高,很多系統基本都是用這種敏捷的開發方式盡快地上線。新系統上線有一個很大的問題就是剛上線時壓力都不會很大、負載也不高,但其實是很多問題在開始階段被隱藏了。等到真正發生問題時,負載高了或者壓力大了再去解決問題,難度就會比較大一點。
尤其對于數據庫來說,數據庫量小的時候,比如說300、500M的數據,這個表格怎么整改都很簡單,但等到這個表漲到300、500G甚至1、2T時再想去做這個表數據類的整改,難度就會大很多。
比如說,我們之前做分期表整改時會用這種在線重定義的方式,但對于一些比較大的表,幾百G甚至上T的表,再用這種在線重定義的方式,就會遇到各種各樣的BUG。
后來坑踩多了,我們現在對于大表的分表改造就是先同步歷史數據級改造,后做一個數據增量,方法會復雜很多。但其實如果在開始階段,我們對于這種大表就已經設計好它的分區,尤其在時間索引上,基于時間去做一個分區,可以避免很多問題。
為什么我們的歷史庫里有那么多時間索引?
很大的一個原因是有很多報表是基于時間去查詢的,比如說要查這一個月或者這一天新增的一些數據的情況,都需要通過時間的字段去訪問。我之前就見過很多關于時間的索引,但***卻因為時間索引的特性,導致系統源源不斷地出現各種各樣的問題。如果在設計階段把這些大表提前就設計成分區表,完全可以避免這些不必要的問題。
二、運維管理
因為各個公司具體情況不同,我接下來就簡單介紹一下我司關于運維管理的一些做法,給大家做個參考。
1、變更管理
相對來說,我們公司的變更管理比較嚴格,后續可能會更加嚴格。
變更管控
對于變更管控,比如在白天嚴禁做任何變更,工作時間內任何變更都不能做,即便是一些緊急或故障的修復,也是需要通過部門負責人確認、領導同意后才可以做的,確保風險可控。
變更流程
可能每個公司都有變更流程,但我們公司有一個比較特殊的地方。因為一些兼容數據庫的要求可能會高一些,流程管控的每個部分都要確保到位。
變更方案
我們的變更方案是每個人要提前去做評審和驗證,包括制定方案的同事和實施操作的同事,就需要變更實施人員提前在一個環境下做完整的驗證,確保每個步驟都是驗證通過的。
2、規范管理
架構規范
我自己之前在做架構師時,制定各種各樣的規范是一項重點的工作。可能是養成習慣了,現在也和大家一起制定各式各樣的運維規范。但我自己感受最深的是:規范一定要有統一的標準,如果做不到統一就有可能會在后續產生問題。
比如我們之前有些開發測試環境不是那么規范,現在想改造做自動化時,發現根本就做不起來,因為每個庫的情況不一樣,自動化的腳本不可能適應所有情況來做這種標準化的改造。
把它弄成不標準是很簡單的,但要想把不標準的改成標準的,難度就大了,尤其是在我們已經形成習慣之后。
運維規范
在2014年前,我們做的是純Oracle數據庫的運維,因為之前建立的是一個傳統的金融企業,運維的都是Oracle數據庫,但2014年后我們逐步轉向了互聯網金融。因此我們陸續研究了MySQL、PG、Redis、MongDB、SQL Server、HBase等7、8種數據庫,在運維過程中遇的坑就會比較多。
最初有很多標準,但沒有一個是***的實踐,很多也是根據業界、自己的經驗制定出來了;還有各種不同的數據庫里,不同的團隊制定了不同標準,***就有各種各樣的標準了。
所以我們在運維中會發現各種各樣的問題,***要強制去做這方面的規范整改。而且,之前的標準大部分都沒有經過大規模使用和大規模負載的驗證,很多標準并不那么統一、規范和有效。因此,我們在運維過程中對于這種規范,還是在不斷地去優化和改進,畢竟很多情況在沒有遇到時,你真的是沒有辦法去解決這個問題。
規范優化
舉個例子,最初我們并沒有規定Redis一定要和應用放在同一個網絡區域,但隨著 Redis的負載增加,我們發現防火墻已經承受不了。當時平安的WiFi剛上線不久,但關于Redis的訪問,幾個實例每秒都有高達到上萬次調用,整個防火墻都撐不住了,還差點導致一個比較嚴重的故障。
在解決這個問題后,我們就制定了一條強制的規范:Redis這種高并發訪問的數據庫,一定要和應用放在一起,不能有出現跨墻訪問的情況。
所以這個規范也是不斷去優化的,包括我們運維的一些標準。因為在最初創建標準時,我們可能會因為使用時間不長而考慮不到一些問題。
我印象比較深刻的是MySQL剛引入時的一個問題,對于軟件的版本沒有明確到小版本,后來甚至出現有MySQL停庫時是5.6.22的版本,在維護完成后就被啟動成5.6.16的版本,***是通過不斷地優化來確保我們的規范和實際是相結合的,避免這種問題的發生。
3、 人員發展
團隊意識
關于團隊這塊,需要提升每個人在團隊中的作用,需要確保團隊里的每個人都是有備份的。如果發展成離開誰都不行,那對團隊的整體發展來說是不正常的。
所以我們在安排工作時,對于比較重要的工作,我會盡量不讓熟悉的同事重復去做,而是盡量讓一些不熟悉的同事參與去做。之前每走一個資深成員,都會明顯感覺到團隊的整體技能或知識少了一塊。為了避免類似問題的發生,從2017年開始我們就制定了一些策略,讓大家做知識技能的分享,每周抽取兩個下午,每個下午抽取一到兩個小時做分享。
另一個策略是技能的積累,即把我們在工作中遇到和解決的一些問題都錄入問題管理系統。這樣做有兩個好處:一是可以把重復的問題記錄下來,因為我們想要去分析哪些問題是重復發生的、哪些是有共性的,就需要有一個這樣的系統去拉對應的問題清單,***去解決問題;二是即便人員流失了,他們之前解決的一些問題和技能也能讓團隊其他人發現,不至于每走一個人就留下一個坑。
所以我們是通過這種手段來盡量避免人員流失或變動給團隊帶來的一些問題。但說到底,其實這是沒辦法完全避免的,因為數據庫運維有一定的復雜度,需要依靠不斷地發生故障、解決故障,包括一些人為失誤來提升。
權責分明
我們的輪班人員是7×24小時,即上三班的方式來輪班的。之前團隊有一個比較嚴重的問題,當一件事情發生了,輪班人員有可能將問題交接給下一班次;或是升級給其他人后,就覺得與自己沒有關系了。還有就是風險意識不強,有一些操作沒有評估過影響就開始在生產庫里操作。
當時我們也發生了不少問題,后來在內部重點提升兩點意識:責任人意識和風險意識。
首先你需要在生產做措施前,確保要做的操作會有什么影響、導致什么后果,不能在做完后才去想這個問題:比如說我們現在每天變更,都需要提前把腳本和手冊做好,讓值班人員熟悉。操作會有什么后果?后續有什么異常會發生?應對方法又是什么?……這些都是需要提前評估好的。
技能提升
關于技能提升,雖然必要的培訓是必不可少的,但我們認為關鍵還是要靠自己的學習、理解和在實踐中的積累,并沒有什么好的捷徑去實現,大多時候還是要通過不斷地解決問題、發現問題甚至包括犯錯的代價來提升的。