差異數據的對比和整理
在我們日常的工作中,常常會遇到很多結構相同,但來源不同的數據。有時,這些數據之間完全獨立,互不重疊,例如各個分公司從自己系統中導出的銷售數據;但有時,這些數據之間又會有大量的重疊,例如常見的一個完整業務流程中涉及的各個系統、各個環節,都可能根據各自收到的單據進行錄入。這時,如何對這些重疊數據進行對比,從而發現和糾正其中的錯誤,就需要我們常說的“自動對賬”操作了。
在一般業務系統的設計開發中,這種對賬功能的邏輯基本上都是通過循環遍歷一套數據的記錄,在另一套記錄數據中逐一比對查找。雖然代碼邏輯高度類似,但又常常因為比對所用關鍵字的差異,以及可能發生的需求變化而需要單獨編寫,最終導致開發成本居高不下,維護難度越來越大。
現在有了集算器,類似問題的處理,就會變得直觀而且便捷,因為集算器中提供了真正面向集合的各種運算。具體到差異數據的對比和整理,只需要sort()和merge()兩個函數既可以了。
我們以一個簡化了的銷售記錄合并的例子來進行說明。
下表顯示的兩個文件old.csv和new.csv分別代表預計銷售的情況和實際銷售的情況,都包含了銷售人員姓名userName、銷售日期date、銷售額saleValue、銷售數量saleCount。在業務分析時,需要分別找出新增的、刪除的、修改的數據行進行分析,其中userName和date作為進行比對的關鍵字,也稱為邏輯主鍵:
| Old.csv | New.csv | |
| . 1 2 3 4 5 6 7 8 9 |
userName,date,saleValue,saleCount Rachel,2015-03-01,4500,9 Rachel,2015-03-03,8700,4 Tom,2015-03-02,3000,8 Tom,2015-03-03,5000,7 Tom,2015-03-04,6000,12 John,2015-03-02,4000,3 John,2015-03-02,4300,9 John,2015-03-04,4800,4 . |
userName,date,saleValue,saleCount Rachel,2015-03-01,4500,9 Rachel,2015-03-02,5000,5 Ashley,2015-03-01,6000,5 Rachel,2015-03-03,11700,4 Tom,2015-03-03,5000,7 Tom,2015-03-04,6000,12 John,2015-03-02,4000,3 John,2015-03-02,4300,9 John,2015-03-04,4800,4 |
可以看到new.csv中的第2、3行是新增的記錄,可能對應額外成交的新訂單,第4行是修改的記錄,可能對應成交價格變化,old.csv中第3行是刪除的記錄,可能對應撤銷的訂單。
傳統邏輯的比對代碼我們不再贅述,直接看一看在集算器中是如何處理的:
| A | B | |
| 1 | =file(“d:\\old.csv”).import@t(;”,”) | =file(“d:\\new.csv”).import@t(;”,”) |
| 2 | =A1.sort(userName,date) | =B1.sort(userName,date) |
| 3 | =new=[B2,A2].merge@d(userName,date) | |
| 4 | =detete=[A2,B2].merge@d(userName,date) | |
| 5 | =diff=[B2,A2].merge@d(userName,date,saleValue,saleCount) | |
| 6 | =update=[diff,new].merge@d(userName,date) | result update |
沒錯,就這么幾行,沒有循環遍歷,沒有查詢算法優化,而且如果比對的關鍵字變化了,只需要修改這么一目了然的幾行。讓我們從上到下捋一下:
A1,B1:以逗號為分隔符讀入文件,形成兩個原始的數據集合。這里也可以從其他格式的文件或數據庫的數據表中讀取。
A2,B2:使用sort()函數,將數據按照關鍵字,也就是邏輯主鍵排序,形成新的集合。以便后面的merge()函數使用。
A3:查找新增記錄,也就是關鍵字userName和date在集合B2中同時不在集合A2中,這就是集合的“差集”計算,是通過函數選項@d指定的,類似的還有并集@u,交集@i。計算得到一個新的集合“new”如下:

A4:這次查找被刪除的記錄,也就是關鍵字userName和date在集合A2中但不在B2中的記錄,注意merger()函數前方括號中A2、B2的次序不同。同樣計算得到一個新的集合“delete”結果如下:

A5:和A3一樣,查找B2與A2的差集,但這次將所有字段都作為關鍵字,因此會找到所有變化的記錄,包括修改過的和新增的記錄。這個結果形成的新集合“diff”如下:
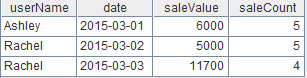
A6:很明顯“diff”集合中去掉新增的記錄,也就“new”集合,就是被修改過的記錄,對應的集合“update”如下:

可以看到,在集合的概念下,記錄的新增、刪除、修改都有著直觀的含義,無非就是新、老集合的不同部分,通過相應的集合運算可以非常方便的表示。
這樣計算得到的結果,除了可以在計算的IDE中查看,或者通過文件處理函數輸出到文件中,還可以通過JDBC方式返回給 Java 程序或其他報表工具,代碼中的 B6 就顯示如何將這種對賬處理的結果非常簡單作為結果集返回給其他系統模塊,下面是Java程序中使用這個結果集的示例:
- //建立esProc jdbc連接
- Class.forName(“com.esproc.jdbc.InternalDriver”);
- con= DriverManager.getConnection(“jdbc:esproc:local://”);
- //調用esProc,其中test是腳本文件名,可接收參數
- st =(com.esproc.jdbc.InternalCStatement)con.prepareCall(“call test()”);
- st.execute();//執行esProc存儲過程
- ResultSet set = st.getResultSet();//獲得計算結果
可以看到,集算器處理差異數據,真正體現和“差異”的本質含義,也就是集合的差異。事實上,這種差異數據廣泛存在與各種系統之中和不同系統之間,大到銀行、運營商系統中的賬目數據,小到個人文件系統中的查重和版本比較,只要明確了需要對比的數據集合和關鍵字,就可以靈活地通過集合運算進行各種整理工作了。