手把手:掃描圖片又大又不清晰?這個Python小程序幫你搞定!
大數(shù)據(jù)文摘作品
編譯:HAPPEN、于樂源、小魚
一位樂于分享學生精彩筆記的大學教授對于掃描版的文件非常不滿意——顏色不清晰并且文件巨大。他因此用python自己寫了一個小程序來解決這個問題。
這個程序可以用來整理手寫筆記的掃描件哦,輸出的圖片不僅很清晰,而且文件大小只有100多KB!
先來看一個例子:

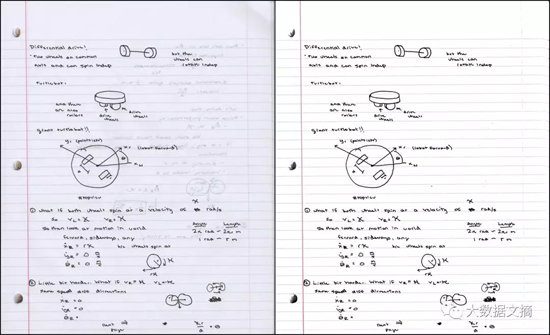
左:輸入掃描件(300 DPI,7.2MB PNG/790KB JPG.)
右:輸出圖片(300 DPI,121KB PNG)。
如果你急于上手操作,可以直接查看Github repo中的代碼,或跳到本文結果部分,看看炫酷的顏色簇交互式三維圖。
免責聲明:上述過程或許可以用Office Lens應用程序實現(xiàn),或者其他工具也可以實現(xiàn)。本文只是一個實用方法分享,不是什么發(fā)明創(chuàng)造。
起因
一些我任課的班級沒有指定的教材,這是因為我更喜歡每周指定一個“學生記錄員”,與班里其他同學分享他們的講義。這樣可以為學生提供一些書面資源,以便他們需要時可以進行對照。筆記以PDF的格式發(fā)布在課程網(wǎng)站。
在學校,我們有一臺能夠將筆記掃描成PDF文件的“智能”復印機,但是它生成的文件不夠招人喜歡。下圖是手寫筆記的輸出示例:
復印機好像隨意地決定是否將每個數(shù)學符號進行二值化,或者轉換后的JPG很不理想(如上圖中的平方根符號)。因此我決定對上述問題進行優(yōu)化。
概述
我們從某位同學一頁漂亮的筆記開始處理,筆記掃描件如下:

以300 DPI精度掃描的原始PNG圖像大小約為7.2MB;轉換為圖像品質較高的JPG格式后,文件大小約為790KB。由于PDF掃描件通常采用PNG或JPG作為容器格式,我們當然不希望在轉換為PDF時損失文件信息。
但是考慮到網(wǎng)頁加載時間,每頁筆記800KB已經(jīng)相當大了,我希望獲得文件大小更接近100KB/頁的圖像。
雖然這位學生的筆記很整潔,但筆記的掃描件看起來有點亂。原因是復印機將這頁筆記的反面內容也進行了掃描,這會分散讀者的注意力,而對于JPG或PNG編碼器來說,這種情況比純色背景的圖片更難壓縮。
下圖是我寫的noteshrink.py程序的輸出結果:

輸出結果是一個相對較小的PNG文件,大小只有121KB。不僅圖像內存變小,而且看起來更清晰!這才是我想要的!
處理過程和彩色圖像基礎
以下是生成小內存且清晰的圖像所需的步驟:
- 識別原始掃描圖像的背景色。
- 根據(jù)背景色的不同閾值分離出前景色。
- 從前景色中選擇幾種“代表性顏色”,作為生成PNG過程中需要的索引色。
在深入研究這些步驟之前,先來了解下彩色圖像是如何以數(shù)字形式進行存儲的。由于人類眼睛中有三種不同類型的感色細胞,因此我們可以通過組合不同強度的紅色、綠色和藍色來重建任何顏色。重構過程就是將每種顏色與RGB顏色空間中的三維點一一對應,如下所示:
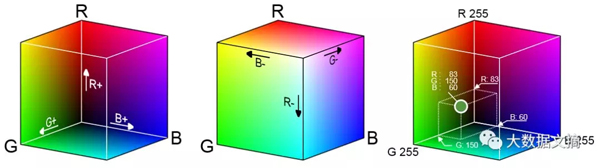
盡管真正的向量空間允許無限數(shù)量的像素亮度連續(xù)變化,但為了將顏色以數(shù)字形式存儲在計算機上,我們需要對上述像素范圍進行離散處理——通常紅色、綠色和藍色分別用8位通道色表示。這種將像素類比成三維色彩空間坐標的分析方法將為我們接下來的理解與重建提供巨大的幫助。
識別背景色
由于頁面的大部分地方?jīng)]有墨跡或線條,也許有人會認為紙張本身的顏色將會是掃描圖像中出現(xiàn)頻率最高的一種顏色——即復印機會將白紙的每個像素表示為相同的RGB值。
如果結果真是這樣,那么分離背景色將不會有任何問題。遺憾的是,情況并非總是如此,由于復印機玻璃板上的灰塵和污跡、頁面本身的顏色變化、傳感器噪聲等不同的因素,像素的RGB值會發(fā)生隨機的變化,頁面的“實際顏色”其實可能涵蓋數(shù)千個不同的RGB值。
掃描圖像的原件大小為2081×2531,共5267011個像素點。雖然我們可以逐一處理每個像素點,但是處理輸入圖像的代表性像素點會更快。
noteshrink.py程序默認采集輸入圖像5%的像素點(在掃描精度為300 DPI的情況下)。接下來,我們先選擇一個10000點的小像素集,結果如下圖所示:

雖然結果與筆記掃描件的頁面差異很大(沒有手寫墨跡)——但兩幅圖像的顏色分布幾乎完全相同。兩張圖片中大多像素點呈灰白色,也有少量紅色、藍色和深灰色的像素點。然后我們對10000個像素點按亮度進行了排序(例如將每個像素點的R、G和B進行求和),結果如下:

從遠處看,圖像底部80-90%的區(qū)域看上去是同一種顏色;然而仔細觀察后,你會發(fā)現(xiàn)很多不一致的細節(jié)。事實上,上圖中主要顏色(RGB值為(240,240,242))的像素個數(shù)僅為226——占比還不到總像素數(shù)10000的3%。
由于上述方法中主要顏色占總像素的比例很小,能否將它作為代表性顏色來描述圖像的顏色分布就值得懷疑。如果在尋找方法之前先減小圖像的位深度,我們將更好地識別頁面的主要顏色。
因此我們把每個色彩通道四個最低有效位置零,將原來每個8位通道色簡化成4位通道色,結果如下所示:

現(xiàn)在主要顏色的RGB值為(224,224,224),并且其像素點數(shù)為3623,占總像素的36%。通過減少位深度,實際上我們將相似的像素分到更大的“組”,這將更容易在數(shù)據(jù)中找到一個強峰。
可靠性和精確度之間存在一個折衷方案:小像素集可以更好地區(qū)分顏色,但大像素集處理起來更可靠。最后,我決定用6位通道色表示來識別背景色,這似乎是兩個極端之間的一個最佳選擇。
分離前景色
一旦識別出背景色,就可以根據(jù)圖像中每個像素與背景色的相似程度來進行閾值計算。通常來說,通過計算兩個像素坐標的歐幾里得距離,再與預設的閥值進行比較就能得到他們之間的相似性。可這個最常用的方法卻無法正確區(qū)分下面的幾個顏色:

下表展示了每種顏色與背景色的歐幾里德距離:
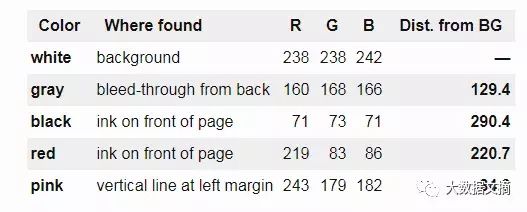
從表中可以看出,筆記反面滲過來的深灰色應該被分為背景色,但它與白色背景的差值要比粉紅色的差值更大,而粉紅色應該是前景色。如果使用這種方法,就無法有效分離出粉紅色的前景色,因為總會包含滲過來的深灰色。
為了解決這個問題,我們可以將圖片從RGB空間移動到色相-飽和度-亮度(Hue-Saturation-Value,HSV)空間,HSV將RGB的立方體轉變?yōu)閳A柱體,其剖面圖如下:
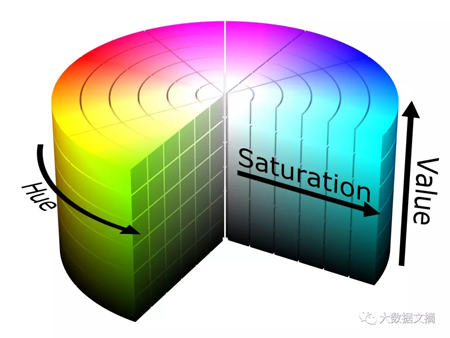
HSV圓柱體上表面邊緣呈現(xiàn)圓形分布的彩虹色,色度(hue)是指圍繞圓柱體的中心軸旋轉的角度(紅色為0°)。圓柱體的中心軸從底部的黑色、中間的灰色漸變到頂部的白色——整個軸的飽和度(saturation)為0,外圓周上鮮艷的顏色飽和度都為1。最后,亮度(value)是指顏色的整體亮度,其變化范圍從底部的暗色調到頂部的亮色調。
現(xiàn)在讓我們用HSV重新區(qū)分一下之前的顏色:
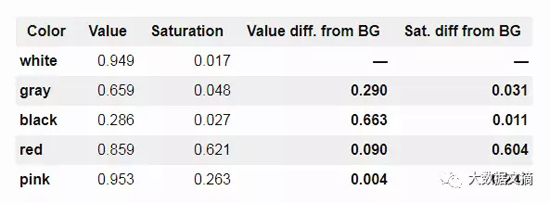
從表中可以看出,白色、黑色和灰色的亮度差別很大,但它們的飽和度都很接近且數(shù)值較低——遠低于紅色或粉紅色。通過分析圖像的HSV值,我們可以利用下面的標準來標記屬于前景色的像素,只需要滿足其中一條就可以:
- 該像素的亮度與背景色的差值大于0.3;
- 該像素的飽和度與背景色的差值大于0.2;
第一條標準可以分離出筆記中的黑色墨跡,第二條標準則可以分離出紅色墨跡和粉色線條,且這兩個標準在選取前景色時排除了筆記反面滲透過來的灰色。但不同的圖像可能需要不同的飽和度或亮度閾值,詳情請參閱結果部分。
選擇一組有代表性的顏色
當我們將前景色分離后,會得到與頁面上筆記的顏色相對應的一組顏色。將得到的像素點重新放進RGB空間并計算每個像素對應的坐標,可以看到新的散點圖呈現(xiàn)簇狀,每一個顏色會形成自己的色塊:

由three.js提供支持的交互式三維圖
現(xiàn)在我們的目標是將原始的圖像(24位/像素)中的所有顏色用8種“索引色”進行替換(8并非固定的數(shù)字)。這樣做有兩種好處:首先,它縮小了文件的大小,因為現(xiàn)在只需要3位就可以指定一種顏色(因為8 = 2^3);此外,它使得生成的圖像在視覺上更美觀,因為在最終輸出的圖像中,相似顏色的筆記都會只用一種顏色替代。
為了實現(xiàn)這個目標,我們通過數(shù)據(jù)驅動的方式,也就是利用上圖中的“簇狀”特性,選擇每個色簇的中心坐標來表示這一組顏色。用術語說,我們將通過聚類分析來解決一個色彩量化問題(其實是向量量化)。
具體的做法是,通過k-means算法在一個顏色簇中找到一個點,這個點到其他每個點的平均距離之和最小。對上述數(shù)據(jù)集使用這個方法,得到7個不同的顏色簇:
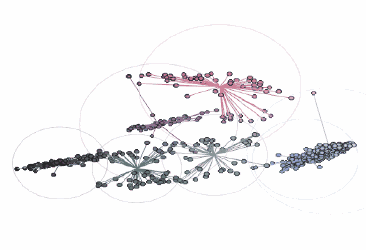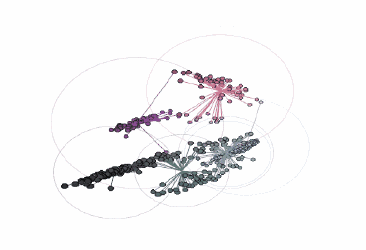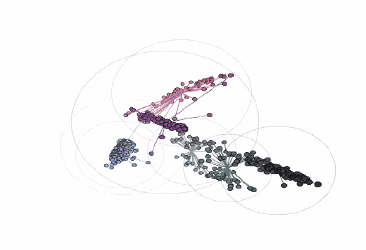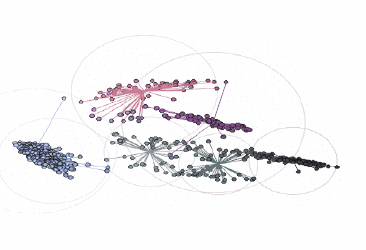
由three.js提供支持的交互式三維圖
在這張圖中,黑色輪廓彩色實心的點表示前景色像素的顏色坐標,通過彩色的線將它們連接到RGB色彩空間中最近的中心點。當圖像轉換為索引顏色時,每個前景色像素的顏色將被替換為距其最近的中心點的顏色。最后,包圍每個顏色簇的圓表示每個中心點距相關像素的最遠距離。
細節(jié)調整
除了能夠設置亮度和飽和度的閾值之外,noteshrink.py還具有幾個其他值得一提的功能。默認情況下,它通過將亮度的最小和最大值重新調整為0和255來增加最終調色板的鮮艷度和對比度。如果不進行調整,上述掃描件的8色調色板將如下所示:

調整后的調色板色彩更鮮明:

在完成前景色分離后,還有一個選項可以強制將背景色變?yōu)榘咨Mㄟ^轉換為索引顏色的圖像可以進一步壓縮PNG文件,noteshrink.py還可以運行如optipng、pngcrush或pngquant等圖像優(yōu)化工具。
該程序最終會將多個壓縮后的圖像合并為一個PDF文件,就像使用ImageMagick的轉換工具一樣。此外,noteshrink.py會自動對輸入文件名進行數(shù)字排序(而不是像shell globbing 那樣按字母順序排列)。當復印機輸出的文件名是scan 9.png和scan 10.png時是非常有幫助的,上述排序功能保證了壓縮后的頁面在PDF中也保持同樣的順序。
結果
以下是一些程序輸出的例子。第一個輸出的PDF使用默認的閾值設置,看起來很棒:
不同顏色簇的可視化:
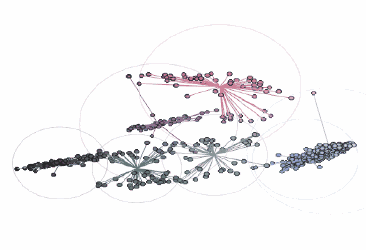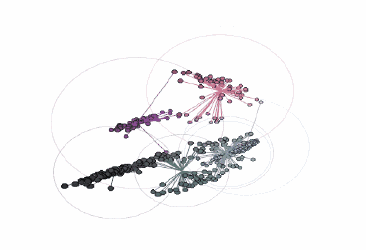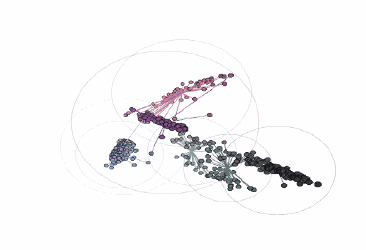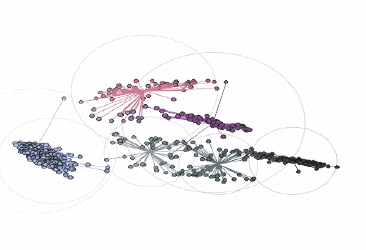
由three.js提供支持的交互式三維圖
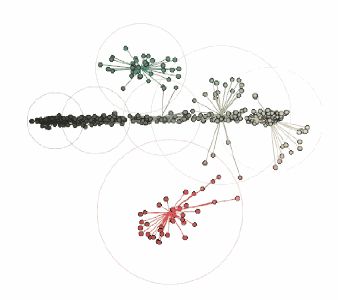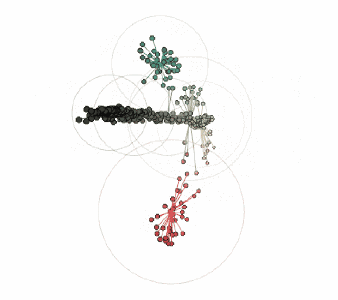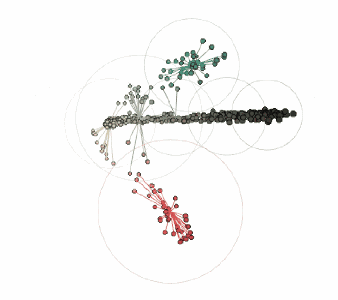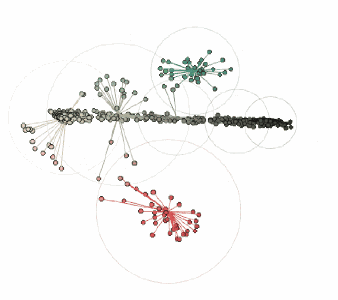
第二個PDF需要將飽和度閾值降低到0.045,因為藍灰色的線條顏色太深不便于閱讀:
對應的顏色簇:

由three.js提供支持的交互式三維圖
最后這個PDF來自于工程師的方格紙,在這個過程中我將亮度閾值設置為0.05,因為背景和線條之間的對比度非常低:

對應的顏色簇:
由three.js提供支持的交互式三維圖
綜上,這四份PDF文件大小約788KB,平均每頁130KB大小。
結論與展望
我很高興能開發(fā)一個實用的工具,這個工具可以將課程網(wǎng)站中的手寫筆記的PDF進行加工和美化。與此同時,記錄下這整個過程也讓我受益匪淺,我先后在維基百科上補充了關于顏色量化的更多內容,也促使我嘗試并學習了three.js。
如果再次啟動這個項目,我想嘗試一下其他的量化方案,就在前幾天還在想用光譜簇結合最近鄰圖的方式去嘗試一下,當時十分興奮認為這是一個絕佳的方案,然后就發(fā)現(xiàn)已經(jīng)有一篇2012年的論文提出了完全一樣的構思,哎…
你也可以嘗試使用最大期望算法來生成描述顏色分布的高斯混合模型——不確定之前是否有人做過類似的實現(xiàn)。當然感興趣的同學也可以試試其他有趣的想法,如使用Lab這類視覺上均勻的色彩空間進行顏色聚類,并嘗試自動給出指定圖像的“最佳”聚類數(shù)量。
原文鏈接:https://mzucker.github.io/2016/09/20/noteshrink.html
【本文是51CTO專欄機構大數(shù)據(jù)文摘的原創(chuàng)譯文,微信公眾號“大數(shù)據(jù)文摘( id: BigDataDigest)”】