













別再讓你的Web頁(yè)面在用戶(hù)瀏覽器端裸奔
- 頁(yè)面在用戶(hù)那里運(yùn)行,如果10%的用戶(hù)頁(yè)面出現(xiàn)問(wèn)題而自己本地沒(méi)有辦法重現(xiàn)?
- 如何先一步了解到前端出現(xiàn)的問(wèn)題,而不是等用戶(hù)反饋?
- 能不能像查看服務(wù)端日志一樣來(lái)定位前端頁(yè)面運(yùn)行的問(wèn)題?
前端在業(yè)務(wù)復(fù)雜度越來(lái)越高的情況下,本地即使做了充分的測(cè)試,依照caniuse做了很多兼容,依然無(wú)法讓人放心頁(yè)面能否正常運(yùn)行或者運(yùn)行得怎么樣。
當(dāng)一個(gè)前端頁(yè)面發(fā)布出去了之后,頁(yè)面所運(yùn)行的設(shè)備、瀏覽器、網(wǎng)絡(luò)環(huán)境、用戶(hù)操作習(xí)慣等等因素都可能是造成頁(yè)面不正常的原因。
所以對(duì)前端頁(yè)面需要做一定的監(jiān)控,而最可行的前端監(jiān)控方式就是將頁(yè)面的日志選擇上報(bào)到監(jiān)控日志服務(wù)器中。
前端日志上報(bào)可以很簡(jiǎn)單
對(duì)業(yè)務(wù)邏輯的執(zhí)行收集了日志數(shù)據(jù)之后可以參數(shù)的形式構(gòu)造一個(gè)url,再通過(guò)一個(gè)Image請(qǐng)求發(fā)送到到服務(wù)器就完成了日志的上報(bào)。
- (new Image).src = `/r.png?page=${location.href}¶m1=${param1}...`;
這樣一行代碼就搞定了日志的上報(bào),然鵝,在生產(chǎn)環(huán)境中,日志上報(bào)所延伸的問(wèn)題要復(fù)雜很多。
日志上報(bào)帶來(lái)的問(wèn)題
日志上報(bào)最終是為了服務(wù)業(yè)務(wù),監(jiān)控業(yè)務(wù)的運(yùn)行狀態(tài),一般而言前端運(yùn)行的場(chǎng)景中開(kāi)發(fā)者最期望監(jiān)控的不外乎頁(yè)面&API請(qǐng)求是否正常響應(yīng)和頁(yè)面js邏輯是否正常執(zhí)行。
為了覆蓋這兩個(gè)監(jiān)控目標(biāo),需要通過(guò)很多類(lèi)型的日志來(lái)覆蓋,還有一些特殊場(chǎng)景下,開(kāi)發(fā)者還希望能與具體業(yè)務(wù)靈活結(jié)合,實(shí)現(xiàn)自定義上報(bào)。所以常見(jiàn)的日志類(lèi)型如下
– 頁(yè)面&API請(qǐng)求是否正常響應(yīng)
– API調(diào)用日志 – API調(diào)用成功與否及其耗時(shí)
– 頁(yè)面性能日志 – 頁(yè)面連接耗時(shí)、首次渲染時(shí)間、資源加載耗時(shí)等
– 訪問(wèn)統(tǒng)計(jì)日志 – PV/UV,短時(shí)間內(nèi)斷崖式的量變化很容易反應(yīng)問(wèn)題
– 頁(yè)面js邏輯是否正常執(zhí)行
– 頁(yè)面穩(wěn)定性日志 – 頁(yè)面加載和頁(yè)面交互產(chǎn)生的js error信息
– 業(yè)務(wù)相關(guān)日志
– 自定義上報(bào) – 某些業(yè)務(wù)邏輯的結(jié)果、速度、統(tǒng)計(jì)值等自定義內(nèi)容
隨著前端業(yè)務(wù)的壯大,日志監(jiān)控上報(bào)的量會(huì)快速增加,監(jiān)控的邏輯也會(huì)越來(lái)越復(fù)雜,而在生產(chǎn)環(huán)境中,前端監(jiān)控的最基本原則是日志獲取和上報(bào)本身不能拋出異常或者影響頁(yè)面性能。
這么多的日志類(lèi)型代表了日志獲取的邏輯復(fù)雜,同時(shí)各種各樣的瀏覽器和環(huán)境會(huì)讓這個(gè)問(wèn)題變得更棘手,例如想用console.warn打印異常信息,但是可能會(huì)出現(xiàn)warn函數(shù)調(diào)用報(bào)錯(cuò);例如捕捉到了error但是error.message全是Script error.…
瀏覽器的兼容性,前端業(yè)務(wù)邏輯依賴(lài),日志上報(bào)方式,日志上報(bào)效率,用戶(hù)操作習(xí)慣,網(wǎng)絡(luò)環(huán)境等因素都可能讓日志上報(bào)產(chǎn)生問(wèn)題甚至影響業(yè)務(wù)。這些因素會(huì)給日志上報(bào)帶來(lái)可靠和性能兩方面的問(wèn)題
日志上報(bào)的可靠性問(wèn)題
瀏覽器兼容性
在不同端和瀏覽器中,因?yàn)榧嫒菪缘牟煌?日志獲取邏輯的和上報(bào)方法需要兼容多種方式來(lái)進(jìn)行,例如fetch方法方法是否可用,頁(yè)面性能(performance)計(jì)算是否可以使用NT2標(biāo)準(zhǔn),這些問(wèn)題可能會(huì)帶來(lái)上報(bào)邏輯本身報(bào)錯(cuò)污染業(yè)務(wù)日志統(tǒng)計(jì);
上報(bào)可靠性
日志采集sdk可能因?yàn)榫W(wǎng)絡(luò)原因無(wú)法加載,所以安全的方式是sdk注入的位置合理的靠后,那么頁(yè)面打開(kāi)到sdk初始化這段時(shí)間就會(huì)產(chǎn)生漏報(bào);
后端為了業(yè)務(wù)分離,通常會(huì)獨(dú)立設(shè)定一個(gè)日志采集服務(wù)器,這種情況下日志上報(bào)可能會(huì)遇到跨域問(wèn)題;
用戶(hù)的頻繁操作和關(guān)閉頁(yè)面會(huì)可能造成很多已經(jīng)收集的數(shù)據(jù)漏報(bào)。
日志上報(bào)的性能問(wèn)題
在一個(gè)復(fù)雜站點(diǎn)中,這些日志數(shù)據(jù)可能會(huì)非常多,上報(bào)可能會(huì)因?yàn)闉g覽器并發(fā)數(shù)量的限制阻塞業(yè)務(wù)的網(wǎng)絡(luò)請(qǐng)求,或者影響頁(yè)面性能。
更優(yōu)雅的上報(bào)姿勢(shì)
姿勢(shì)一 隔離業(yè)務(wù)
資源隔離
為了避免影響業(yè)務(wù),那么理所當(dāng)然,為了不占用業(yè)務(wù)計(jì)算資源,日志上報(bào)需要單獨(dú)設(shè)定后端服務(wù)。
同時(shí)也不能使用與業(yè)務(wù)相同的域名,這跟頁(yè)面盡量使用CDN引入資源的原理相似,瀏覽器會(huì)對(duì)同一個(gè)域名有一定的并發(fā)數(shù)限制。
而頁(yè)面性能、資源加載、初始化API、PV/UV、初始化js邏輯錯(cuò)誤等日志都是頁(yè)面初始化的時(shí)候觸發(fā)上報(bào),這種短時(shí)間大量的上報(bào)可能會(huì)造成網(wǎng)絡(luò)請(qǐng)求延時(shí)。例如chrome對(duì)同一個(gè)域名的最大并發(fā)連接數(shù)為6個(gè),如果日志同時(shí)上報(bào)了6次以上,就會(huì)對(duì)同域名的業(yè)務(wù)造成影響;更壞的情況如頁(yè)面有一些錯(cuò)誤、網(wǎng)絡(luò)連接質(zhì)量質(zhì)量不高會(huì)讓日志上報(bào)阻礙頁(yè)面渲染。
因此日志上報(bào)可以像使用CDN服務(wù)一樣,使用單獨(dú)域名和日志處理服務(wù)。
既然使用了不同的域名,那么跨域問(wèn)題隨之而來(lái),這需要前后端共同支持。服務(wù)器需要允許外部訪問(wèn)Access-Control-Allow-Origin:*;前端在進(jìn)行日志上報(bào)的時(shí)候要添加避免跨域標(biāo)識(shí),如fetch方式:
- var url = 'https://arms-retcode.aliyuncs.com/r.png';
- fetch(
- `${url}?t=perf&page=qar.alibaba-inc.com&load=1168`,
- {mode:'no-cors'}
- )
不同域名一個(gè)性能缺點(diǎn)是增加首次DNS解析時(shí)間,不過(guò)可以通過(guò)在頁(yè)面添加DNS預(yù)解析來(lái)避免。
- <link rel="dns-prefetch" href="https://arms-retcode.aliyuncs.com">
異常隔離
在資源隔離的基礎(chǔ)上,日志上報(bào)的異常處理也需要隔離,日志本身拋出的異常絕對(duì)不能和業(yè)務(wù)異常混在一起上報(bào)。
進(jìn)行充分測(cè)試的前提下,最簡(jiǎn)單粗暴的方式是在整個(gè)監(jiān)控sdk外面添加try...catch...,好處是永遠(yuǎn)不會(huì)出現(xiàn)sdk本身錯(cuò)誤上報(bào),不過(guò)同時(shí)也讓開(kāi)發(fā)者失去了發(fā)現(xiàn)sdk問(wèn)題的途徑。所以?xún)烧呒娴玫姆绞绞潜匾摹?/p>
這里提供一個(gè)關(guān)鍵模塊埋點(diǎn)的方法,它對(duì)整個(gè)前端監(jiān)控sdk多個(gè)關(guān)鍵點(diǎn)上埋點(diǎn)并且收集的結(jié)果中只標(biāo)記是否成功。話不多說(shuō),直接上示例代碼:
- // 全局標(biāo)記匯總,初始化為36個(gè)點(diǎn)位均為1的數(shù)組
- var N = 36;
- var sdkStat = Array.from({length: N}, () => 1);
- /** 日志上報(bào)功能模塊
- * 對(duì)應(yīng)模塊報(bào)錯(cuò)設(shè)置對(duì)應(yīng)點(diǎn)位為0,多個(gè)點(diǎn)位為0可以幫助找到錯(cuò)誤發(fā)生鏈路
- */
- try{/* sdk module 0*/}catch(){sdkStat[0] = 0;}
- /* other modules */
- try{/* sdk module 35*/}catch(){sdkStat[35] = 0;}
- // 日志上報(bào)發(fā)送模塊
- var statStr = parseInt(sdkStat.join(''),2).toString(36);
- (new Image).src = `/r.png?¶m1=${param1}&sdkStat=${statStr}...`;
姿勢(shì)二 壓縮請(qǐng)求響應(yīng)報(bào)文
壓縮之前重新審視一下(new Image).src的日志發(fā)送方式:
HTTP Request: 前端日志數(shù)據(jù)以多組key=value的字符串形式接在一個(gè)Image資源請(qǐng)求的url后面,前端發(fā)送Image請(qǐng)求。
HTTP Responce: 服務(wù)器返回響應(yīng)結(jié)果或者空?qǐng)D片。
日志數(shù)據(jù)直接放到url中的好處是網(wǎng)絡(luò)傳輸效率高。然而url長(zhǎng)度是有限制的,例如IE瀏覽器是2083個(gè)字符,同時(shí)服務(wù)器也會(huì)對(duì)url長(zhǎng)度進(jìn)行限制。
類(lèi)似如下的js error信息就沒(méi)有辦法完整上報(bào),
- $ is not defined@https://www.example.com.cn/catalog/?spm=a2o4k.customer.0.0.37c1379dmQwdrW&q=pediasure&searchclickposition=hint:3:231
- ...
- Tg@https://www.googletagmanager.com/gtm.js?id=GTM-KTVS7D9&l=shadowDatalayerKi7l:64:32
- ...
不僅僅是js error的錯(cuò)誤棧深還因?yàn)閡rlencode對(duì)特殊字符和漢字的轉(zhuǎn)碼,這兩個(gè)因素會(huì)使url長(zhǎng)度輕松突破限制。
另外業(yè)務(wù)邏輯實(shí)際上不關(guān)注而且也應(yīng)關(guān)注日志上報(bào)的響應(yīng)結(jié)果,所以這個(gè)請(qǐng)求的結(jié)果應(yīng)該盡可能省去。
針對(duì)報(bào)文壓縮有以下方式:
HTTP/2頭部壓縮
http請(qǐng)求中,每次請(qǐng)求都會(huì)傳輸一系列的請(qǐng)求頭來(lái)描述請(qǐng)求的資源及其特性,然而實(shí)際上每次請(qǐng)求都有很多相同的值,如Host:,user-agent:,Accept等。這些數(shù)據(jù)能夠占用到300-800byte的傳輸量,如果攜帶大的cookie,請(qǐng)求頭甚至可以占用1kb的空間,而實(shí)際真正需要上報(bào)的日志數(shù)據(jù)僅僅只有10~50byte的大小。在HTTP 1.x中,每次日志上報(bào)請(qǐng)求頭都攜帶了大量的重復(fù)數(shù)據(jù)導(dǎo)致性能浪費(fèi)。
HTTP/2頭部壓縮采用Huffman Code壓縮請(qǐng)求頭,并用動(dòng)態(tài)表更新每次請(qǐng)求不同的數(shù)據(jù)來(lái)把每次請(qǐng)求的頭部壓縮到很小。
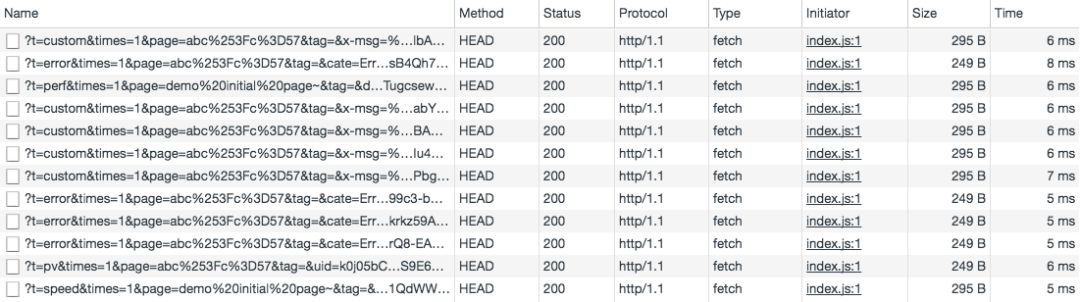
HTTP/1.1效果
HTTP/2.0效果
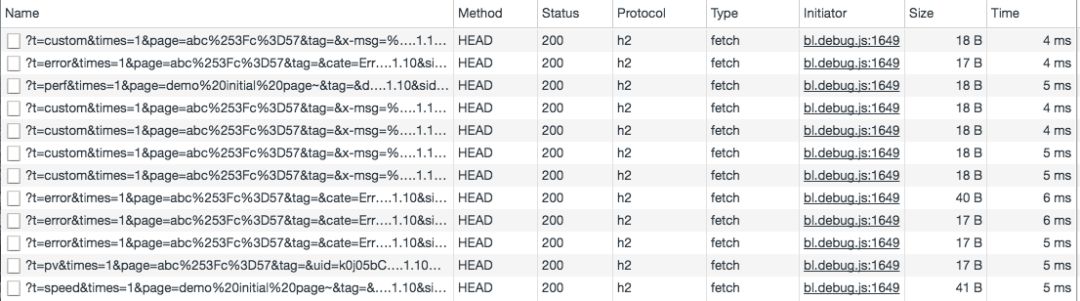
頭部壓縮后每條日志請(qǐng)求的size都大大減小,響應(yīng)的速度也有提升。
壓縮日志的長(zhǎng)度
最需要壓縮即js error的錯(cuò)誤棧,錯(cuò)誤棧當(dāng)中占位最多是錯(cuò)誤定位的文件地址,而很多錯(cuò)誤棧有很多相同的文件,壓縮空間就來(lái)源于stack中js文件的url重復(fù)。
一個(gè)典型的jserror stack經(jīng)常會(huì)出現(xiàn)這種形式如下:
- obj0.fn0 at (http://loooooooooonnnnnnnnnnng/loooooong/long.js 123:1)
- obj1.fn1 at (http://loooooooooonnnnnnnnnnng/loooooong/long.js 234:1)
- obj2.fn2 at (http://loooooooooonnnnnnnnnnng/laaaaaang/lang.js 345:1)
- ...
可考慮把文件url抽取出來(lái)單獨(dú)作為一個(gè)字典,那么上報(bào)內(nèi)容可縮減為
- files={'f1':'http://loooooooooonnnnnnnnnnng/loooooong/long.js','f2':'...'}
- obj0.fn0 at (f1 123:1)
- obj1.fn1 at (f1 234:1)
- obj2.fn2 at (f2 345:1)
- ...
即可大大縮減日志長(zhǎng)度。
省去響應(yīng)體
日志上報(bào)本身只關(guān)注日志有沒(méi)有上報(bào),而對(duì)上報(bào)請(qǐng)求的返回內(nèi)容并不關(guān)注,甚至完全可以不需要返回內(nèi)容。所以使用HTTP HEAD的方式上報(bào),并且返回的響應(yīng)體為空,避免響應(yīng)體傳輸資源損耗。
這時(shí)候只需要設(shè)置一個(gè)nginx服務(wù)器來(lái)記錄日志內(nèi)容并返回200狀態(tài)碼即可。
- fetch(`${url}?t=perf&page=lazada-home&load=1168`,
- {mode:'no-cors',method:'HEAD'}
- )
姿勢(shì)三 合并上報(bào)
既然一個(gè)頁(yè)面上報(bào)的次數(shù)那么多,一個(gè)更容易想到的idea應(yīng)該是把日志合并上報(bào)來(lái)減小請(qǐng)求數(shù)量。
HTTP/2多路復(fù)用
用戶(hù)瀏覽器和日志服務(wù)器之間產(chǎn)生多次HTTP請(qǐng)求,而在HTTP/1.1 Keep-Alive下,日志上報(bào)會(huì)以串行的方式傳輸,會(huì)讓后面的日志上報(bào)延時(shí)。通過(guò)HTTP/2的多路復(fù)用來(lái)合并上報(bào),節(jié)省網(wǎng)絡(luò)連接的開(kāi)銷(xiāo)。
HTTP POST合并
POST請(qǐng)求因?yàn)閞equest body可以有更大施展空間,在HTTP POST中只要一次包含多條日志的內(nèi)容,那么相對(duì)于一條日志一次HTTP HEAD請(qǐng)求的方式會(huì)更加經(jīng)濟(jì)。
在HTTP POST的基礎(chǔ)上,可以順便解決用戶(hù)關(guān)掉或者切換頁(yè)面造成的漏報(bào)問(wèn)題。
以前常見(jiàn)的解決方式是監(jiān)聽(tīng)頁(yè)面的unload或者beforeunload事件,并以通過(guò)同步的XMLHttpRequest請(qǐng)求或者構(gòu)造一個(gè)特定src的<img>標(biāo)簽來(lái)延遲上報(bào)。
- window.addEventListener("unload", uploadLog, false);
- function uploadLog() {
- var xhr = new XMLHttpRequest();
- xhr.open("POST", "/r.png", false); // false表示同步
- xhr.send(logData);
- }
這種上報(bào)的缺點(diǎn)是會(huì)給下一個(gè)頁(yè)面的性能造成影響。更優(yōu)雅的方式是使用navigator.sendBeacon(),它能夠異步地發(fā)送日志數(shù)據(jù)。
- window.addEventListener("unload", uploadLog, false);
- function uploadLog() {
- navigator.sendBeacon("/r.png", logData);
- }
合并前

合并后(navigator.sendBeacon)
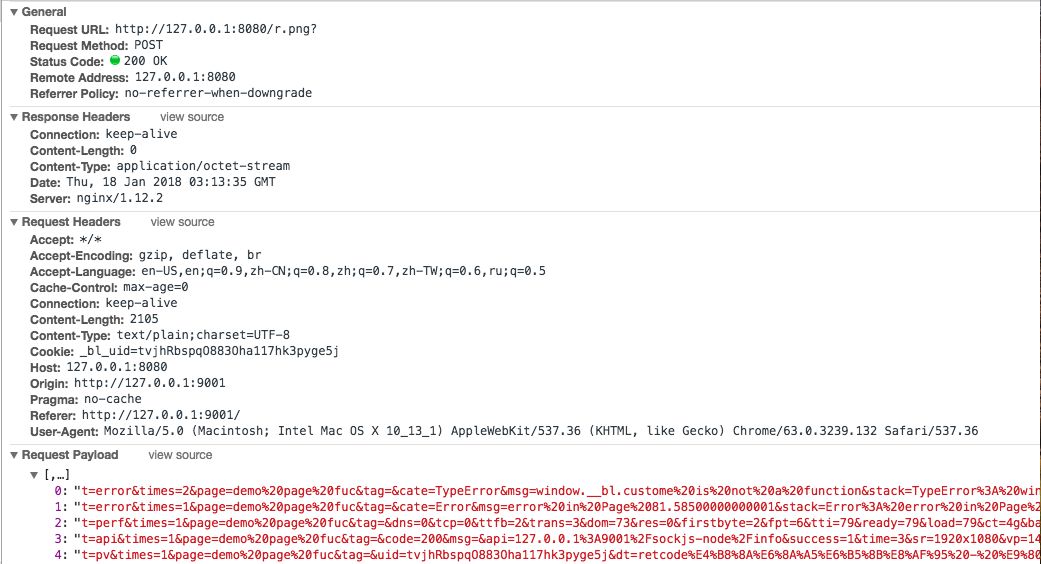
理想情況下,合并n個(gè)日志上報(bào)耗費(fèi)的總時(shí)間能達(dá)到原來(lái)的1/n
小結(jié)
前端業(yè)務(wù)場(chǎng)景和瀏覽器的兼容性千差萬(wàn)別,所以日志上報(bào)要兼容多種方式;頁(yè)面生命周期、業(yè)務(wù)邏輯影響了日志是否可獲取和是否漏報(bào),所以對(duì)應(yīng)的日志類(lèi)型和上報(bào)時(shí)機(jī)要嚴(yán)格把握;前端業(yè)務(wù)邏輯快速迭代且場(chǎng)景多樣,所以日志上報(bào)要做到與業(yè)務(wù)解耦合同時(shí)可以自定義上報(bào)…
這些大大小小的坑促使我們把前端日志監(jiān)控沉淀為一個(gè)獨(dú)立且系統(tǒng)性的工程來(lái)做,在打磨這個(gè)工程的過(guò)程中我們同樣還在探索是否有更加高效、穩(wěn)定的日志上報(bào)方式。

















