時序數據庫技術體系 – InfluxDB TSM存儲引擎之數據寫入
InfluxDB寫入總體框架
InfluxDB提供了多種接口協議供外部應用寫入,比如可以使用collected采集數據上傳,可以使用opentsdb作為輸入,也可以使用http協議以及udp協議批量寫入數據。批量數據進入到InfluxDB之后總體會經過三個步驟的處理,如下圖所示:
1. 批量時序數據shard路由:InfluxDB首先會將這些數據根據shard的不同分成不同的分組,每個分組的時序數據會發送到對應的shard。每個shard相當于HBase中region的概念,是InfluxDB中處理用戶讀寫請求的單機引擎。
2. 倒排索引引擎構建倒排索引:InfluxDB中shard由兩個LSM引擎構成 – 倒排索引引擎和TSM引擎。時序數據首先會經過倒排索引引擎構建倒排索引,倒排索引用來實現InfluxDB的多維查詢。
3. SM引擎持久化時序數據:倒排索引構建成功之后時序數據會進入TSM Engine處理。TMS Engine處理流程和通用LSM Engine基本一樣,先將寫入請求追加寫入WAL日志,再寫入cache,一旦滿足特定條件會將cache中的時序數據執行flush操作落盤形成TSM File。
批量時序數據Shard路由
通常來說時序數據都會以批量的形式寫入數據庫,很少會像關系型數據庫那樣一條一條寫入,這對于追求高吞吐的時序系統來說至關重要。批量數據寫入InfluxDB之后做的***件事情是分組,將時序數據點按照所屬shard劃分為多組(稱為Shard Map),每組時序數據點將會發送給對應的shard引擎并發處理。
這里我們簡單回顧下InfluxDB的Sharding策略(詳見文章《時序數據庫技術體系 – 初識InfluxDB》中Sharding策略一節)。InfluxDB雖說是單機數據庫,但是每個表依然會被分為多個shard。簡單來說,InfluxDB中sharding屬于兩層sharding:首先按照時間進行Range Sharding,即按時間分片,比如7天一個分片的話,最近7天的數據會分到一個shard,一周前到兩周前的數據會被分到上一個shard,以此類推;在時間分片的基礎上還可以再執行Hash Sharding,按照SeriesKey執行Hash(保證同一個SeriesKey對應的所有數據都落到同一個shard),再將數據分散到指定的多個shard中。
當然,經過筆者深進一步了解,發現單機InfluxDB只有***層sharding,即只有根據時間進行Range Sharding,并沒有執行Hash Sharding。Hash Sharding只會在分布式InfluxDB中才會用到。
倒排索引引擎構建倒排索引
InfluxDB中倒排索引引擎使用LSM引擎構建,上篇文章《時序數據庫技術體系 – InfluxDB 多維查詢之倒排索引》其實已經對引擎的工作原理進行了深入的介紹。這里重點將整個流程做一個串聯梳理,其中細節部分不會展開來講,有興趣的話可以參考上一篇文章。
這里首先思考一個問題:為什么InfluxDB倒排索引需要構建成LSM引擎?其實很簡單,LSM引擎天生對寫友好,寫多讀少的系統***選擇就是LSM引擎,所以大數據時代的各種數據存儲系統就是LSM引擎的天下,HBase、Kudu、Druid、TiKV這些系統無一不是這樣。InfluxDB作為一個時序數據庫更是寫多讀少的典型,無論倒排索引引擎還是時序數據處理引擎選用LSM引擎更是無可厚非。
既然是LSM引擎,工作機制必然是這樣的:首先將數據追加寫入WAL再寫入Cache就可以返回給用戶寫入成功,WAL可以保證即使發生異常宕機也可以恢復出來Cache中丟失的數據。一旦滿足特定條件系統會將Cache中的時序數據執行flush操作落盤形成文件。文件數量超過一定閾值系統會將這些文件合并形成一個大文件。那具體到倒排索引引擎整個流程是什么樣的,簡單來看一下:
1. WAL追加寫入:Inverted Index WAL格式很簡單,由一個一個LogEntry構成,如下圖所示:
每個LogEntry由Flag、Measurement、一系列Key\Value以及Checksum組成。其中Flag表示更新類型,包括寫入、刪除等,Measurement表示數據表,Key\Value表示寫入的Tag Set以及Checksum,其中Checksum用于根據WAL回放數據時驗證LogEntry的完整性。注意,LogEntry中并沒有時序數據列,只有維度列(Tag Set)。
2. Inverted Index在內存中構建
(1)拼SeriesKey: 時序數據寫入到系統之后先將measurement和所有的維度值拼成一個seriesKey;
(2)確認SeriesKey是否已經構建過索引:在文件中確認該seriesKey是否已經存在,如果已經存在就忽略,不需要再將其加入到內存倒排索引。那問題轉化為如何在文件中查找某個seriesKey是否已經存在?這就是Series Block中Bloom Filter的核心作用,首先使用Bloom Filter進行判斷,如果不存在,肯定不存在。如果存在,不一定存在,需要進一步判斷。再進一步使用B+樹以及HashIndex進一步查找判斷;
(3)如果seriesKey在文件中不存在,需要將其寫入內存。倒排索引內存結構主要包含兩個Map:<measurement, List<tagKey>> 和 <tagKey, <tagValue, List<SeriesKey>>>,前者表示時序表與對應維度集合的映射,即這個表中有多少維度列。后者表示每個維度列都有哪些可枚舉的值,以及這些值都對應哪些SeriesKey。InfluxDB中SeriesKey就是一把鑰匙,只有拿到這把鑰匙才能找到這個SeriesKey對應的數據。而倒排索引就是根據一些線索去找這把鑰匙。
3. Inverted Index Cache Flush流程
(1)觸發時機:當Inverted Index WAL日志的大小超過閾值(默認5M),就會執行flush操作將緩存中的兩個Map寫成文件;
(2)基本流程:
- 緩存Map排序:<measurement, List<tagKey>>以及<tagKey, <tagValue, List<SeriesKey>>都需要經過排序處理,排序的意義在于有序數據可以結合Hash Index實現范圍查詢,另外Series Block中B+樹的構建也需要SeriesKey排序;
- 構建并持久化Series Block:在排序的基礎上首先持久化<tagKey, tagValue, List<SeriesKey>>結構中所有的SeriesKey,也就是先構建Series Block。依次持久化SeriesKey到SeriesKeyChunk,當Chunk滿了之后,根據Chunk中最小的SeriesKey構建B+樹中的Index Entry節點。當然,Hash Index以及Bloom Filter是需要實時構建的。需要注意的是,Series Block在構建的同時需要記錄下SeriesKey與該Key在文件中偏移量的對應關系,即<SeriesKey, SeriesKeyOffset>,這一點至關重要;
- 內存中將SeriesKey映射為SeriesId:將<tagKey, <tagValue, List<SeriesKey>>結構中所有的SeriesKey由上一步中得到的<SeriesKey, SeriesKeyOffset >中的SeriesKeyOffset代替。形成新的結構:<tagKey, <tagValue, List<SeriesKeyOffset>>,即<tagKey, <tagValue, List<SeriesKeyId>>>,其中SeriesKeyId就是SeriesKeyOffset;
- 構建并持久化Tag Block:在新結構<tagKey, <tagValue, List<SeriesKeyId>>>的基礎上首先持久化tagValue,將同一個tagKey下的所有tagValue持久化在一起并生成對應Hash Index寫入文件,接著持久化下一個tagKey的所有tagValue。所有tagValue都持久話完成之后再依次持久化所有的tagKey,形成Tag Block;
- 構建并持久化Measurement Block:***持久化measurement形成Measurement Block。
時序數據寫入流程
時序數據的維度信息經過倒排索引引擎構建完成之后,接著就需要將數據寫入系統。和倒排索引引擎一樣,數據寫入引擎也是一個LSM引擎,基本流程也是先寫WAL,再寫Cache,***滿足一定閾值條件之后將Cache中的數據flush到文件。
1. WAL追加寫入:時間線數據數據會經過兩重處理,首先格式化為WriteWALEntry對象,該對象字段元素如下圖所示。然后經過snappy壓縮后寫入WAL并持久話到文件。

2. 時序數據寫入內存結構
(1)時序數據點格式化:將所有時間序列數據點按時間線組織形成一個Map:<SeriesKey+FieldKey, List<Value>>,即將相同Key(SeriesKey+FieldKey)的時序數據集中放在一個List中;
(2)時序數據點寫入Cache:InfluxDB中Cache是一個crude hash ring,這個ring由256個partition構成,每個partition負責存儲一部分時序數據Key對應的值。就相當于數據寫入Cache的時候又根據Key Hash了一次,根據Hash結果映射到不同的partition。為什么要這么處理?個人認為有點像Java中ConcurrentHashMap的思路,將一個大HashMap切分成多個小HashMap,每個HashMap內部在寫的時候需要加鎖。這樣處理可以減小鎖粒度,提高寫性能。
3. Data Cache Flush流程(參考engine.compactCache)
(1)觸發時機:Cache執行flush操作有兩個基本觸發條件,其一是當cache大小超過一定閾值,可以通過參數’cache-snapshot-memory-size’配置,默認是25M大小;其二是超過一定時間閾值沒有時序數據寫入WAL也會觸發flush,默認時間閾值為10分鐘,可以通過參數’cache-snapshot-write-cold-duration’配置;
(2)基本流程:在了解了TSM文件的基本結構之后,我們再簡單看看時序數據是如何從內存中的Map持久化成TSM文件的,整個過程可以表述為:
- 內存中構建Series Data Block:順序遍歷內存Map中的時序數據,分別對時序數據的時間列和數值列進行相應的編碼,按照Series Data Block的格式進行組織,當Block大小超過一定閾值就構建成功。并記錄這個Block內時間列的最小時間MinTime以及***時間MaxTime。
- 將構建好的Series Data Block寫入文件:使用輸出流將內存中數據輸出到文件,并返回該Block在文件中的偏移量Offset以及總大小Size。
- 構建文件級別B+索引:在內存中為該Series Data Block構建一個索引節點Index Entry,使用數據Block在文件中的偏移量Offset、總大小Size以及MinTime、MaxTime構建一個Index Entry對象,寫入到內存Series Index Block對象。
這樣,每構建一個Series Data Block并寫入文件之后都會在內存中順序構建一個Index Entry,寫入內存Series Index Block對象。一旦一個Key對應的所有時序數據都持久化完成,一個Series Index Block就構建完成,構建完成之后填充Index Block Meta信息。接著新建一個新的Series Index Block開始構建下一個Key對應的數據索引信息。
InfluxDB數據刪除操作(DropMeasurement,DropTagKey)
一般LSM引擎處理刪除通常都采用Tag標記的方式,即刪除操作和寫入操作流程基本一致,只是數據上會多一個Tag標記 – deleted,表示該值已經被deleted。這種處理方案可以最小化刪除代價,但萬物有得必有失,減小了寫入代價必然會增加讀取代價,Tag標簽方案在讀取的時候需要對標記有deleted的數值進行特殊處理,這個代價還是很大的。HBase中刪除操作就是采用Tag標記方案。
InfluxDB比較奇葩,對于刪除操作處理的比較異類,通常InfluxDB不會刪除一條記錄,而是會刪除某段時間內或者某個維度下的所有記錄,甚至一張表的所有記錄,這和通常的數據庫有所不同。比如:
DROP SERIES FROM h2o_feet WHERE location = ‘santa_monica' DELETE FROM "cpu" DELETE FROM "cpu" WHERE time < '2000-01-01T00:00:00Z' DELETE WHERE time < '2000-01-01T00:00:00Z'
上文我們知道InfluxDB中一個shard有兩個LSM引擎,一個是倒排索引引擎(存儲維度列到SeriesKey的映射關系,方便多維查找),一個是TSM Engine,用來存儲實際的時序數據。如果是刪除一條記錄,通常只需要TSM Engine執行刪除就可以,倒排索引引擎是不需要執行刪除的。而如果是Drop Measurement這樣的操作,那么兩個LSM引擎都需要執行相應的刪除。問題是,這兩個引擎的刪除策略完全不同,TSM Engine采用了一種同步刪除策略,Inverted Index Engine采用了標記刪除策略。如下圖所示:
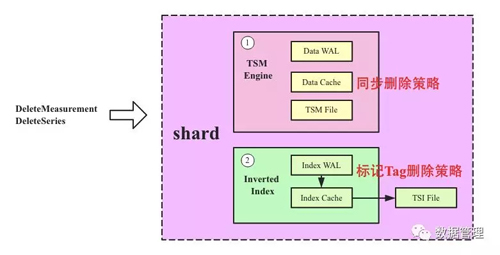
1. TSM Engine同步刪除策略,整個刪除流程可以分為如下四步:
(1)刪除所有TSM File中滿足條件的series,系統會遍歷當前shard中所有TSM File,檢查該File中是否存在滿足刪除條件的File,如果有會執行如下兩個操作:
- TSM File Index相關處理:在內存中刪除滿足條件的Index Entry,通常刪除會帶有Time Range以及Key Range,而且TSM File Index會在引擎啟動之后加載到內存。因此刪除操作會將滿足條件的Index Entry從內存中刪除。
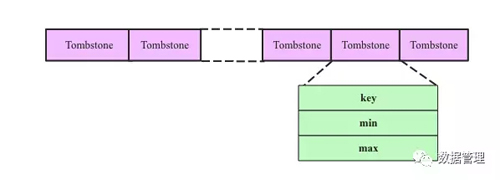
- 生成tombstoner文件:tombstoner文件會記錄當前TSM File中所有被刪除的時序數據,時序數據用[key, min, max]三個字段表示,其中key即SeriesKey+FieldKey,[min, max]表示要刪除的時間段。如下圖所示:
(2)刪除Cache中滿足條件的series;
(3)在WAL中生成一條刪除series的記錄并持久化到硬盤。
2. Inverted Index Engine 標記Tag刪除策略,標記Tag刪除非常簡單,和一次寫入流程基本相同:
(1)在WAL中生成一條flag為deleted的LogEntry并持久化到硬盤;
(2)將要刪除的維度信息寫入Cache,需要標記deleted(設置type=deleted);
(3)當WAL大小超過閾值之后標記為deleted的維度信息會隨Cache Flush到倒排索引文件;
(4)和HBase一樣,Inverted Index Engine中索引信息真正被刪除發生在compact階段。
總結
InfluxDB因為其特有的雙LSM引擎而顯得內部結構更加復雜,寫入流程相比其他數據庫來說更加繁瑣。但只要理解了它的數據文件內部組織格式以及倒排索引文件內部組織格式,相信對于整體的把握也并不是很難。