














演講的主題是 時(shí)序數(shù)據(jù)庫(kù)現(xiàn)狀及核心技術(shù)/問(wèn)題,因?yàn)榧夹g(shù)都是為解決具體問(wèn)題生的。

我們將從如下3個(gè)視角的分享,分別從:
- 領(lǐng)域趨勢(shì)方面和大家聊聊時(shí)序數(shù)據(jù)庫(kù)的現(xiàn)狀和未來(lái)發(fā)展空間。
- 核心技術(shù)角度和大家聊聊時(shí)序數(shù)據(jù)庫(kù)面臨怎樣的實(shí)際問(wèn)題,將會(huì)以怎樣的技術(shù)手段來(lái)解決。
- 從應(yīng)用場(chǎng)景和價(jià)值締造角度我們簡(jiǎn)單聊聊如何才能讓時(shí)序數(shù)據(jù)庫(kù)在具體應(yīng)用場(chǎng)景中產(chǎn)生業(yè)務(wù)價(jià)值。

那么,在開始今天的分享之前,先簡(jiǎn)單的介紹一下我的個(gè)人信息:
我是 孫金城,阿里花名 “金竹”。
目前在阿里工作已經(jīng)接近10年,以ApacheFlink為切入點(diǎn),在流計(jì)算領(lǐng)域貢獻(xiàn)了5年,目前以阿里巴巴物聯(lián)網(wǎng)分析團(tuán)隊(duì)負(fù)責(zé)人的角色,基于ApacheIoTDB對(duì)時(shí)序數(shù)據(jù)存儲(chǔ)領(lǐng)域進(jìn)行探索。
在開源領(lǐng)域,目前是兩個(gè)Apache頂級(jí)項(xiàng)目的PMC成員,也是ApacheMember,同時(shí)也在支持Apache本土社區(qū)的發(fā)展,是ALCBeijing的成員,Apache孵化器的IPMC 成員,以及開放原子開源基金會(huì)的孵化器導(dǎo)師。
那么,在眾多的開源 參與和貢獻(xiàn) 的同時(shí),我個(gè)人也非常喜歡做一些技術(shù)類的博客和視頻分享,也歡迎大家關(guān)注我的個(gè)人公眾號(hào),大家可以保持線下的持續(xù)交流。

好的,我們開始今天的第一部分,我們看看時(shí)序數(shù)據(jù)庫(kù)目前處在一個(gè)怎樣的趨勢(shì),是什么造就了時(shí)序數(shù)據(jù)庫(kù)的快速發(fā)展?

從我的角度看,聊存儲(chǔ),我喜歡從數(shù)據(jù)的角度切入。。
目前不僅僅是數(shù)據(jù)時(shí)代,而且數(shù)據(jù)的規(guī)模是驚人的,我們處在一個(gè)大數(shù)據(jù)時(shí)代。那么我們所說(shuō)的大數(shù)據(jù)時(shí)代的數(shù)據(jù)規(guī)模到底是怎樣的呢?
根據(jù)某研究院發(fā)布的統(tǒng)計(jì)數(shù)據(jù),近年,隨著人工智能、5G,AIoT等技術(shù)的推動(dòng),全球數(shù)據(jù)量正在無(wú)限地增加。2018年全球數(shù)據(jù)總量為33ZB,在2019年約達(dá)到45ZB。按照這樣的增長(zhǎng)趨勢(shì),到2025年,全年將會(huì)有175ZB的數(shù)據(jù)產(chǎn)生。
在希捷的首頁(yè),有一句話,這里分享給大家:
全球數(shù)據(jù)領(lǐng)域?qū)?019年的45ZB增長(zhǎng)到2025年的175ZB,全球數(shù)據(jù)的近30%將需要實(shí)時(shí)處理,您的企業(yè)是否已經(jīng)做好準(zhǔn)備?同樣帶著這個(gè)問(wèn)題,我們看看實(shí)時(shí)數(shù)據(jù)庫(kù)領(lǐng)域是否做好了準(zhǔn)備?

那么,到2025年每年175ZB的數(shù)據(jù)從哪里來(lái)的呢?我們從云/邊/端三個(gè)角度看數(shù)據(jù)的創(chuàng)建和存儲(chǔ)。
隨著網(wǎng)絡(luò)的高速發(fā)展,尤其是5G時(shí)代的到來(lái),數(shù)據(jù)越來(lái)越多的進(jìn)入云端。那么我們所說(shuō)的Core/Edge/Endpoint(云/邊/端)分別指的是什么呢?
- 云(Core) - 這包括企業(yè)中指定的計(jì)算數(shù)據(jù)中心和云提供商。它包括各種云計(jì)算,公共云、私有云云和混合云。
- 邊(Edge) - 邊緣是指不在核心數(shù)據(jù)中心的企業(yè)級(jí)服務(wù)器和設(shè)備。這包括服務(wù)器機(jī)房、現(xiàn)場(chǎng)服務(wù)器、還有一些較小的數(shù)據(jù)中心,這些數(shù)據(jù)中心位于距離設(shè)備較近的區(qū)域,以加快響應(yīng)。
- 端(Endpoint) - 端包括網(wǎng)絡(luò)邊緣的所有設(shè)備,包括個(gè)人電腦、電話、聯(lián)網(wǎng)汽車、可穿戴備以及工業(yè)傳感器等。
那么這些數(shù)據(jù)來(lái)源,有哪些是我們?nèi)粘9ぷ魃羁梢愿兄降哪兀课覀兘酉聛?lái)簡(jiǎn)單舉例分析一下:
 ?
?
作為在阿里工作近10年的我,對(duì)我來(lái)說(shuō)感覺(jué)最近的數(shù)據(jù)是一年一度的雙11全球狂歡。我們發(fā)現(xiàn)自2009年以來(lái),雙11每年的成交額飛速增長(zhǎng),到2020年竟然高達(dá)4982億。這個(gè)數(shù)字背后,說(shuō)明了大量數(shù)據(jù)的產(chǎn)生。但是相對(duì)于175ZB的數(shù)據(jù)來(lái)說(shuō),這些交易數(shù)據(jù),監(jiān)控?cái)?shù)據(jù),只是冰山一角。為什么這樣說(shuō)呢?我們繼續(xù)往下看。。。
這里同樣又一份關(guān)于全球設(shè)備連接的統(tǒng)計(jì)數(shù)據(jù),到2020年全球有500億的設(shè)備數(shù)據(jù)上云,這些設(shè)備覆蓋了很多實(shí)際場(chǎng)景,比如:智能生活,智能城市,智能農(nóng)業(yè),
更值得大家關(guān)注的是智能制造,也即是工業(yè)物聯(lián)網(wǎng)領(lǐng)域。在5G和工業(yè)4.0的的大背景下,工業(yè)物聯(lián)網(wǎng)也將會(huì)是下一個(gè)技術(shù)趨勢(shì)所在。。。

我們說(shuō)到技術(shù)發(fā)展趨勢(shì),Gartner的數(shù)據(jù)是大家非常信任的,在2021年Gartner又指明了9大技術(shù)趨勢(shì),如果大家關(guān)注Gartner的報(bào)告,我們發(fā)現(xiàn)這9大戰(zhàn)略技術(shù)趨勢(shì)和前三年有了一些變化。
2018強(qiáng)調(diào)云向邊緣挺進(jìn),2019主張賦權(quán)邊緣,2020更加強(qiáng)調(diào)流量的處理要靠近設(shè)備本地,其實(shí)也就是端和邊的計(jì)算技術(shù)。這連續(xù)三年都明確提到了端/邊,也就是物聯(lián)網(wǎng)領(lǐng)域,那么2021的戰(zhàn)略趨勢(shì)和物聯(lián)網(wǎng)有怎樣的關(guān)系呢?
2021強(qiáng)調(diào)的分布式云就是強(qiáng)調(diào)了物聯(lián)網(wǎng)領(lǐng)域已經(jīng)走進(jìn)云邊端一體化的進(jìn)程,分布式云將取代私有云。分布式云的架構(gòu)更強(qiáng)調(diào)了中心云計(jì)算能力下沉的時(shí)代趨勢(shì)。
分布式云的多樣性也囊括了物聯(lián)網(wǎng)領(lǐng)和邊緣計(jì)算的技術(shù)方向。那么在這樣一個(gè)大的技術(shù)趨勢(shì)下,時(shí)序數(shù)據(jù)庫(kù)當(dāng)前處在一個(gè)怎樣的階段呢?

國(guó)家對(duì)物聯(lián)網(wǎng)領(lǐng)域,尤其是工業(yè)物聯(lián)網(wǎng)領(lǐng)域是高度重視的,早在2017年就提出了指導(dǎo)意見(jiàn),明確了三個(gè)階段性的發(fā)展目標(biāo):在2025年之前重點(diǎn)在基礎(chǔ)設(shè)施的建設(shè),到2035年具備平臺(tái)化能力,最終達(dá)到應(yīng)有層面的落地。那么實(shí)際上各個(gè)大廠的發(fā)展都是超前于這份指導(dǎo)性建議的發(fā)展目標(biāo)額,目前各個(gè)云廠商已經(jīng)基本形成了各自的工業(yè)物聯(lián)網(wǎng)平臺(tái)的搭建,后續(xù)的重點(diǎn)是平臺(tái)的增強(qiáng)和實(shí)際應(yīng)用的創(chuàng)新發(fā)展。那么在這樣一個(gè)高速發(fā)展的階段,各個(gè)大廠都在解決這這樣的問(wèn)題呢?
其實(shí),物聯(lián)網(wǎng)領(lǐng)域的數(shù)據(jù)產(chǎn)生,大部分來(lái)自于 工業(yè)物聯(lián)網(wǎng),剛才大家看到,物聯(lián)網(wǎng)領(lǐng)域設(shè)備連接在2020年已經(jīng)超過(guò)500億,我們以一個(gè)挖掘機(jī)工礦信息來(lái)說(shuō),一個(gè)設(shè)備就有5000多的工況指標(biāo)要采集,數(shù)據(jù)每秒都在不停的采集,數(shù)據(jù)量可畏是驚人的,那么在千億的工礦數(shù)據(jù)和ZB級(jí)別的時(shí)序數(shù)據(jù)面前,我們面臨怎樣的難題呢?
大家會(huì)想到的是數(shù)據(jù)上云的帶寬流量成本問(wèn)題,但幸運(yùn)的是,在過(guò)去的20年中,有線寬帶服務(wù)每兆比特的費(fèi)用下降了98%,從2000年的平均28.13美元下降到2020年的0.64美元。所以低流量成本的情況下,ZB級(jí)別的存儲(chǔ)成本問(wèn)題就更為顯著。技術(shù)都是為領(lǐng)域問(wèn)題而生,面對(duì)這樣的領(lǐng)域問(wèn)題,存儲(chǔ)領(lǐng)域又有這樣的技術(shù)變化呢?

根據(jù)DB-Engines的統(tǒng)計(jì)數(shù)據(jù),我們發(fā)現(xiàn),在各種數(shù)據(jù)庫(kù)存儲(chǔ)產(chǎn)品中,時(shí)序數(shù)據(jù)庫(kù)的發(fā)展是最受歡迎,發(fā)展是最快的。
也就是說(shuō),5G和工業(yè)4.0的發(fā)展,大量時(shí)序數(shù)據(jù)的產(chǎn)生,促就了時(shí)序數(shù)據(jù)庫(kù)的快速發(fā)展。那么,目前都有哪些時(shí)序數(shù)據(jù)庫(kù)產(chǎn)品呢?

同樣這個(gè)統(tǒng)計(jì)也是來(lái)自DB-engines網(wǎng)站,目前我們已經(jīng)有幾十種時(shí)序數(shù)據(jù)庫(kù)產(chǎn)品,這些產(chǎn)品有些是開源的,有些是各個(gè)大廠研發(fā)的商業(yè)產(chǎn)品。
目前來(lái)看,大概有20%+的商業(yè)產(chǎn)品,近80%來(lái)自開源社區(qū),這里也多說(shuō)一句,擁抱開源同樣也是大勢(shì)所趨。

好的,趨勢(shì)方面我們就了解到這里,接下來(lái)我們細(xì)致的看看現(xiàn)在的時(shí)序數(shù)據(jù)庫(kù)有哪些特點(diǎn),如何分類,時(shí)序數(shù)據(jù)庫(kù)又???哪些核心技術(shù)。

首先,我們從存儲(chǔ)架構(gòu)角度,看看時(shí)序數(shù)據(jù)庫(kù)的分類情況。
- 第一類就是是基于關(guān)系數(shù)據(jù)庫(kù)的時(shí)序數(shù)據(jù)庫(kù),比如timescale。
- 第二類就是基于KV的時(shí)序數(shù)據(jù)庫(kù),比如OpenTSDB。
- 第三類就是專門面向時(shí)序數(shù)據(jù)場(chǎng)景的原生時(shí)序數(shù)據(jù)庫(kù),比如InfluxDB,IoTDB和TDengine等。
當(dāng)然持久化角度看,還有很多優(yōu)秀的內(nèi)存時(shí)序數(shù)據(jù)庫(kù),比如:Google的Monarch,Facebook基于Gorilla論文實(shí)現(xiàn)的產(chǎn)品。那么不論基于怎樣的架構(gòu),這些時(shí)序數(shù)據(jù)庫(kù)都要解決的共性問(wèn)題有是什么呢?

我們前面說(shuō)最大的數(shù)據(jù)來(lái)源是工業(yè)領(lǐng)域的各種設(shè)備傳感器數(shù)據(jù),這些設(shè)備的工況數(shù)據(jù)收集和處理將給存儲(chǔ)和計(jì)算帶來(lái)巨大的挑戰(zhàn)。我們還是以一個(gè)具體的案例來(lái)說(shuō),這是GoldWind發(fā)電數(shù)據(jù)采集,GoldWind有超過(guò)2w個(gè)風(fēng)機(jī),一個(gè)風(fēng)機(jī)有120-510個(gè)傳感器,采集頻率高達(dá)50Hz,就是每個(gè)傳感器1秒50個(gè)數(shù)據(jù)點(diǎn)采集峰值。這要算下來(lái)就是每秒5億個(gè)時(shí)序指標(biāo)點(diǎn)的數(shù)據(jù)。這個(gè)數(shù)據(jù)量讓數(shù)據(jù)采集/存儲(chǔ)/計(jì)算面臨很大的挑戰(zhàn)。同時(shí)還有我們業(yè)務(wù)中的一些非常常見(jiàn)的查詢需求。所以時(shí)序數(shù)據(jù)的存儲(chǔ)將要解決寫入吞吐問(wèn)題,還有數(shù)據(jù)查詢分析的性能問(wèn)題。
同時(shí),時(shí)序數(shù)據(jù)領(lǐng)域還有一個(gè)很大的領(lǐng)域特點(diǎn),或者說(shuō)是領(lǐng)域問(wèn)題,那就是弱網(wǎng)環(huán)境下,時(shí)序數(shù)據(jù)的亂序是一種常態(tài)。
亂序問(wèn)題問(wèn)什么是時(shí)序數(shù)據(jù)場(chǎng)景的核心問(wèn)題呢,我看一個(gè)具體的智能制造的案例,如圖。是一個(gè)工業(yè)冶煉能耗控制的例子。核心需求是,在云端進(jìn)行大量的實(shí)時(shí)模型訓(xùn)練,然后模型下推到邊緣端,在邊緣端利用時(shí)序數(shù)據(jù)庫(kù)進(jìn)行數(shù)據(jù)的本地存儲(chǔ)和局部數(shù)據(jù)數(shù)據(jù)預(yù)測(cè),進(jìn)而控制本地的熔爐燃料投放。比如,5秒鐘一個(gè)計(jì)算窗口,那么亂序造成的計(jì)算不精準(zhǔn),將會(huì)對(duì)能源消耗和冶煉質(zhì)量帶來(lái)很大的影響。所以說(shuō),亂序問(wèn)題的解決也是時(shí)序數(shù)據(jù)價(jià)值最大化的核心問(wèn)題所在。

那么從存儲(chǔ)架構(gòu)的維度看,基于關(guān)系/基于KV和原生時(shí)序數(shù)據(jù)庫(kù)的寫入速度有怎樣的排布?
宏觀來(lái)看,基于關(guān)系數(shù)據(jù)庫(kù)的時(shí)序數(shù)據(jù)庫(kù)寫入速度遠(yuǎn)遠(yuǎn)慢于,基于KV和原生的時(shí)序數(shù)據(jù)庫(kù)。為什么會(huì)有這樣的判斷呢?這個(gè)結(jié)論還是從底層存儲(chǔ)架構(gòu)設(shè)計(jì)角度得出的。
關(guān)系數(shù)據(jù)庫(kù)的存儲(chǔ)寫入架構(gòu)是基于B-Tree或者B+Tree,而KV和原生的時(shí)序數(shù)據(jù)庫(kù)都是基于LSM-Tree進(jìn)行數(shù)據(jù)寫入設(shè)計(jì)的。不同的數(shù)據(jù)結(jié)構(gòu)對(duì)寫入性能產(chǎn)生巨大的影響。我們進(jìn)一步細(xì)聊一下其中的原因。。。

聊到存儲(chǔ)寫入,我們立即會(huì)想到磁盤,我們應(yīng)用數(shù)據(jù)寫到磁盤會(huì)經(jīng)過(guò)內(nèi)存,然后持久化到磁盤。那么這個(gè)過(guò)程中,寫入的核心耗時(shí)是在什么階段呢?
就是大家熟知的磁盤IO部分。那我們看看怎樣的磁盤IO才是高性能的?而怎樣的磁盤IO又是低效的呢?
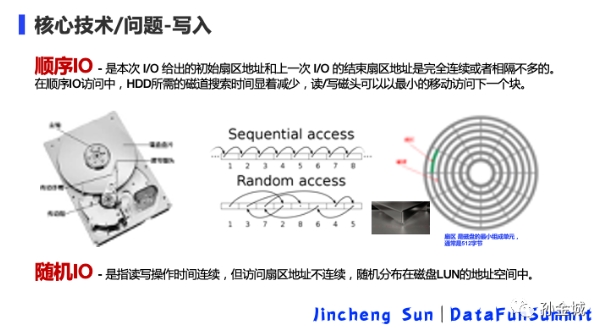
我們知道 扇區(qū) 是磁盤的最小組成單元,通常是512字節(jié),文件系統(tǒng)/數(shù)據(jù)庫(kù)不是一個(gè)扇區(qū)一個(gè)扇區(qū)的來(lái)讀數(shù)據(jù),因?yàn)樘耍杂辛薭lock(塊)的概念,它是一個(gè)塊一個(gè)塊的讀取的,block才是文件存取的最小單位。每個(gè)塊的大小是 4~64KB,但是這個(gè)數(shù)值是可配置。一般來(lái)說(shuō)磁盤訪問(wèn)一個(gè)磁盤塊平均要用10ms左右,因此,我們有必要做一些事情來(lái)減少磁盤的平均訪問(wèn)時(shí)間來(lái)提高寫入性能。大家都知道,順序IO性能遠(yuǎn)高于隨機(jī)IO,隨機(jī)I/O可能是因?yàn)榇疟P碎片導(dǎo)致磁盤空間不連續(xù),或者當(dāng)前block空間小于文件大小導(dǎo)致的。連續(xù) I/O 比隨機(jī) I/O 效率高的原因是:在做連續(xù) I/O 的時(shí)候,磁頭幾乎不用換道,或者換道的時(shí)間很短;而對(duì)于隨機(jī) I/O,很多的話,會(huì)導(dǎo)致磁頭不停地?fù)Q道,造成效率的極大降低。那么剛才說(shuō)的B+Tree和 LSM-Tree的數(shù)據(jù)結(jié)構(gòu),與磁盤IO有怎樣的關(guān)系呢?

我們先來(lái)看看Btree和B+Tree的的寫入復(fù)雜度,這里我們核心看對(duì)磁盤的訪問(wèn),
所以我以DAM的維度看兩種數(shù)據(jù)結(jié)果的復(fù)雜度,我們會(huì)發(fā)現(xiàn)不論是BTree和B+Tree寫入和查詢復(fù)雜度都是LogBN,B是階數(shù),N是節(jié)點(diǎn)數(shù)。感興趣算法復(fù)雜度的推導(dǎo)的朋友可以掃描左下角二維碼查看推導(dǎo)過(guò)程。那么,既然算法復(fù)雜度一樣,在實(shí)際的存儲(chǔ)產(chǎn)品中這兩種設(shè)計(jì)有怎樣的區(qū)別呢,我們先看看BTree和B+Tree的數(shù)據(jù)結(jié)構(gòu)設(shè)計(jì)的區(qū)別:
核心區(qū)別就是:是否在非葉子節(jié)點(diǎn)存儲(chǔ)數(shù)據(jù)以及在葉子節(jié)點(diǎn)是否以指針連接相鄰節(jié)點(diǎn)。那么問(wèn)題來(lái)了,在存儲(chǔ)對(duì)磁盤訪問(wèn)的角度考慮,我們是選擇BTree還是選擇B+Tree呢?這里面我們就要加入另一個(gè)變量因素,就是存儲(chǔ)產(chǎn)品一次讀取磁盤的block因素和每個(gè)節(jié)點(diǎn)數(shù)據(jù)和指針大小因素。根據(jù)BTree和B+Tree的數(shù)據(jù)結(jié)構(gòu)特點(diǎn),在一次讀取磁盤的Block大小一定的情況下,一個(gè)Block的磁盤讀取所包含節(jié)點(diǎn)越多那么在數(shù)據(jù)量一定的情況下,樹的階數(shù)越大,也就是LogBN的B越大,進(jìn)而讀取磁盤次數(shù)越少性能越好。這句話的信息點(diǎn)有點(diǎn)多,相信如果不是存儲(chǔ)領(lǐng)域的朋友可能會(huì)有若干個(gè)“為什么”,那么如果除了對(duì)這個(gè)結(jié)論感興趣,對(duì)細(xì)節(jié)推到部分也感興趣的話,我的公眾號(hào)里面有一個(gè)近2小時(shí)的細(xì)致剖析,大家可以關(guān)注我的公眾號(hào),在會(huì)后進(jìn)行選擇性觀看。

好的,那么我們?cè)倩氐剑瑸槭裁碆Tree/B+Tree的寫入會(huì)設(shè)涉及到隨機(jī)IO問(wèn)題。
假設(shè)我們有如上數(shù)據(jù)按順序進(jìn)入存儲(chǔ)系統(tǒng),如果存儲(chǔ)系統(tǒng)采用的是BTree進(jìn)行設(shè)計(jì)的,我們簡(jiǎn)單分析一下寫入過(guò)程。

首先數(shù)據(jù)陸陸續(xù)續(xù)的到來(lái),35,3,90這個(gè)小樹是如何變化的。。先來(lái)3,再來(lái) 35,再來(lái) 90,我們構(gòu)建數(shù)據(jù)結(jié)構(gòu),如圖,35左右是3和90,數(shù)據(jù)再陸續(xù)到來(lái),當(dāng)17到來(lái)的是,數(shù)據(jù)如何變化?17比35小,所以17再左子樹。假設(shè)這時(shí)候我進(jìn)行了一次持久化操作,然后,后續(xù)數(shù)據(jù)陸續(xù)到來(lái)。。。當(dāng)26到來(lái)的時(shí)候,26比35小,在35的左子樹,但是35左邊已經(jīng)有2個(gè)data了,做3階Btree,節(jié)點(diǎn)超了。因?yàn)楣?jié)點(diǎn)超了,所以我們需要進(jìn)行節(jié)點(diǎn)分裂,如圖,17上提與35同一層級(jí)。這時(shí)候我們假設(shè)再次磁盤持久化處理,我們發(fā)現(xiàn)3和17已經(jīng)不在一個(gè)數(shù)據(jù)塊了,17和35又重新寫到了磁盤上的一個(gè)數(shù)據(jù)塊。

數(shù)據(jù)不斷的到來(lái),數(shù)據(jù)的節(jié)點(diǎn)不斷的變化,磁盤持久化也不斷發(fā)生。

這個(gè)變化過(guò)程中大家發(fā)現(xiàn)機(jī)遇BTree和B+Bree的設(shè)計(jì),寫入磁盤的數(shù)據(jù)是有更新操作的,進(jìn)而造成了大量隨機(jī)IO。

那么我們?cè)賮?lái)看看LSM-Tree的為什么是順序IO?其實(shí),LSM核心思想是放棄部分讀能力,換取寫入的最大化能力。我們看到LSM-Tree的寫入復(fù)雜度是O(1)。具體的插入流程如下:
- 來(lái)請(qǐng)求之后 首先寫入write ahead文件,然后進(jìn)行內(nèi)存的更新,
- 更新完成之后,就返回成功。那么數(shù)據(jù)是如何持久化的呢?
- 當(dāng)內(nèi)存到一定大小后,就將內(nèi)存變成immutable,進(jìn)行持久化操作。
- 最后刷盤進(jìn)行持久化成功之后,會(huì)有后續(xù)的 Merging Compaction在后臺(tái)進(jìn)行。
所以基于LSM Tree結(jié)構(gòu)完美的解決了寫入的高吞吐問(wèn)題。

那么,解決的寫入問(wèn)題,基于LSM-Tree的時(shí)序數(shù)據(jù)庫(kù)產(chǎn)品是如何解決
查詢性能問(wèn)題的呢?我看OpenTSDB查詢邏輯是怎樣的?
- 查詢請(qǐng)求來(lái)了,會(huì)對(duì)各種索引進(jìn)行查詢。。。
- 首先是以二分法查詢MemTable,
- 然后查詢immutableMem-table,
- 如果都沒(méi)有查到,就查詢磁盤文件
?
當(dāng)然在查詢過(guò)程中還伴隨各種優(yōu)化,比如BloomFilter的應(yīng)用。

雖然都是基于LSM-Tree的設(shè)計(jì),但不同的產(chǎn)品有不同的優(yōu)化定制,
比如我們?cè)賮?lái)看看InfluxDB的設(shè)計(jì)。。
- 同樣數(shù)據(jù)來(lái)了也是第一寫入到WAL文件。
- 接下來(lái)再更新內(nèi)存Mem-Table之前,InfluxDB出于查詢性能的考慮,在這個(gè)環(huán)節(jié)增加了內(nèi)存索引構(gòu)建。
- 然后才是內(nèi)存更新,
- 最后返回客戶端成功信息。
當(dāng)然,在Mem-Table部分,InfluxDB也做了局部?jī)?yōu)化,利用hash進(jìn)行分布優(yōu)化。同時(shí)在持久化時(shí)機(jī)上面也考慮了內(nèi)存大小和刷盤時(shí)間周期。其實(shí),InfluxDB設(shè)計(jì)了自己的TSMFile格式,文件增加了索引建立。這里和大家提一句就是,InfluxDB的設(shè)計(jì)充分考慮時(shí)序數(shù)據(jù)的時(shí)間特點(diǎn),在Mem-Table中的Map中采用timestamp作為key的組成部分。從1.8版本看,InfluxDB代碼里面沒(méi)有看到將內(nèi)存變成immutable的部分。在InfluxDB的Compaction時(shí)候也考慮若干優(yōu)化因素。比如壓縮算法的選擇等。最后,InfluxDB還設(shè)計(jì)了自己的索引結(jié)構(gòu),TSI極大的加速了數(shù)據(jù)查詢性能。

好的,看完OpenTSDB和InfluxDB,我們?cè)賮?lái)看看Apache頂級(jí)項(xiàng)目 IoTDB。
IoTDB為了提高查詢速度,不僅定制了 索引結(jié)構(gòu)還增加了查詢優(yōu)化器的支持。
更值得大家關(guān)注的是,IoTDB針對(duì)工業(yè)物聯(lián)網(wǎng)領(lǐng)域時(shí)序數(shù)據(jù)亂序問(wèn)題對(duì)LSM-Tree
進(jìn)行了優(yōu)化改造,在內(nèi)存和文件上面都考慮亂序的處理。出于今天接下來(lái)還有
黃老師對(duì)ApacheIoTDB進(jìn)行細(xì)節(jié)分享,我這里先對(duì)IoTDB簡(jiǎn)單說(shuō)這么多。

OK,那么我們想想,在時(shí)序數(shù)據(jù)庫(kù)領(lǐng)域到底涉及里哪些問(wèn)題和哪些解決這些領(lǐng)域問(wèn)題的核心技術(shù)呢?
- 第一個(gè)就是存儲(chǔ)數(shù)據(jù)結(jié)構(gòu)的設(shè)計(jì),利用xLSM-Tree的架構(gòu)解決寫入高吞吐問(wèn)題。
- 第二個(gè)在高性能查詢上面,各個(gè)產(chǎn)品都有自己的索引定制和查詢優(yōu)化器的引入。
- 第三個(gè)在存儲(chǔ)成本上面,各個(gè)時(shí)序數(shù)據(jù)庫(kù)產(chǎn)品以列式存儲(chǔ)和具體類型的針對(duì)性壓縮算法選取解決存儲(chǔ)成本問(wèn)題。當(dāng)然在云上存儲(chǔ)成本上面我,們還可以在邊緣端做更多的優(yōu)化處理,在云上有冷熱數(shù)據(jù)的處理,這也是分布式云的技術(shù)戰(zhàn)略趨勢(shì)所導(dǎo)向的。
- 第四個(gè)也是非常重要的領(lǐng)域問(wèn)題,就是亂序的解決,利用寫前保序和寫后重排多種手段在存儲(chǔ)層面解決亂序問(wèn)題。進(jìn)而在后續(xù)的計(jì)算分析部分發(fā)揮最大的價(jià)值。那么大家想想除了上面核心的四個(gè)方面還有其他關(guān)鍵問(wèn)題和技術(shù)需要關(guān)注嗎?
- 當(dāng)然還有,那就是在分布式云的架構(gòu)下,邊緣端的部署也是需要高可靠的,各個(gè)時(shí)序數(shù)據(jù)庫(kù)產(chǎn)品都需要提供多副本的集群版支持。
- 最后還有一個(gè),如果最大限度讓時(shí)序數(shù)據(jù)庫(kù)產(chǎn)生最大價(jià)值,邊緣端的實(shí)時(shí)計(jì)算也是必不可少的,那么,時(shí)序數(shù)據(jù)庫(kù)對(duì)實(shí)時(shí)計(jì)算的支持也有很大的技術(shù)挑戰(zhàn)。

那么在上面提到的6大領(lǐng)域問(wèn)題和技術(shù)挑戰(zhàn)中,實(shí)時(shí)計(jì)算看起來(lái)和數(shù)據(jù)庫(kù)關(guān)系不大,為什么我這里還要重點(diǎn)提出呢?
這里和大家分享的思考是,在分布式云的大技術(shù)方向下,計(jì)算不僅僅是集中云上的需求,也是在邊緣端的計(jì)算能力也是一種強(qiáng)需求,我們還以前面提到的案例來(lái)說(shuō)在邊緣上面同樣需要實(shí)時(shí)計(jì)算和實(shí)時(shí)預(yù)測(cè),那么出于邊緣端硬件資源有限,現(xiàn)有云上實(shí)時(shí)計(jì)算產(chǎn)品大多是部署很重的,很難在實(shí)際的工業(yè)領(lǐng)域邊緣節(jié)點(diǎn)進(jìn)行部署,邊緣端需要更輕量的、針對(duì)時(shí)序數(shù)據(jù)進(jìn)行的實(shí)時(shí)計(jì)算支持。所以在邊緣端的時(shí)序數(shù)據(jù)庫(kù)同樣需要接受 支持實(shí)時(shí)計(jì)算 的 技術(shù)挑戰(zhàn)。

那么在分布式計(jì)算領(lǐng)域,我們按照計(jì)算延時(shí)角度已經(jīng)有了很多的技術(shù)產(chǎn)品。
從計(jì)算延時(shí)以天為單位,到計(jì)算延時(shí)達(dá)到毫秒,大家熟知的產(chǎn)品如圖。Hadoop/Hive/Spark/Kafka/Flink等產(chǎn)品,但這些產(chǎn)品的定位都是云上硬件資源豐富的大規(guī)模分布式計(jì)算場(chǎng)景,那么在邊緣端的時(shí)序數(shù)據(jù)分析場(chǎng)景,我們需要具備怎樣的實(shí)時(shí)能力呢?邊緣的實(shí)時(shí)計(jì)算能力我們重點(diǎn)放到分鐘到毫秒的實(shí)時(shí)性。
在這部分的實(shí)時(shí)計(jì)算設(shè)計(jì)架構(gòu)中,我們也有兩種典型的設(shè)計(jì)架構(gòu),一個(gè)是NativeStreaming的設(shè)計(jì)模式,認(rèn)為批是流的特例,另一個(gè)是Micro-Batching的設(shè)計(jì)模式,認(rèn)為流是批的特例。在目前的很多時(shí)序數(shù)據(jù)庫(kù)產(chǎn)品已經(jīng)考慮對(duì)實(shí)時(shí)計(jì)算的支持,比如InfluxDB1.x版本的CQ功能,和2.x版本的Task設(shè)計(jì)。還有ApacheIoTDB正在設(shè)計(jì)的實(shí)時(shí)計(jì)算功能。當(dāng)然今天下午也給大家準(zhǔn)備了專門面向IoT領(lǐng)域的時(shí)序數(shù)據(jù)流計(jì)算分析產(chǎn)品HStreamDB的分享。

好的,到了今天最后一部分。那么,時(shí)序數(shù)據(jù)庫(kù)可以應(yīng)用到哪些場(chǎng)景呢?我們?nèi)绾尾拍芾眉夹g(shù)手段,讓數(shù)據(jù)價(jià)值最大化呢?

時(shí)序數(shù)據(jù)庫(kù)可以應(yīng)用到各種場(chǎng)景中包括前面提各種監(jiān)控領(lǐng)域,以及前面提到的智能制造,智能生活,智能城市等場(chǎng)景中,那么要想這些場(chǎng)景中的價(jià)值最大化,我們需要考慮從采集到數(shù)據(jù)分析和數(shù)據(jù)可視化的各個(gè)環(huán)節(jié)的不同挑戰(zhàn)性問(wèn)題。
這里想稍加強(qiáng)調(diào)的是云邊端的數(shù)據(jù)閉環(huán)的建立,才是數(shù)據(jù)最大化的最佳途徑。我們不僅僅是采集數(shù)據(jù)和數(shù)據(jù)的監(jiān)控,數(shù)據(jù)的可視化,最大的數(shù)據(jù)業(yè)務(wù)價(jià)值需要在采集的數(shù)據(jù)上面進(jìn)行數(shù)據(jù)分析,分析之后的數(shù)據(jù)再反向控制終端,達(dá)成數(shù)據(jù)閉環(huán)。

那么,不同的大廠,不同的時(shí)序數(shù)據(jù)產(chǎn)品在數(shù)據(jù)閉環(huán)的締造中采用的技術(shù)手段可能個(gè)各不相同。今天非常有興邀請(qǐng)到業(yè)界知名的時(shí)序產(chǎn)品負(fù)責(zé)人/大神為大家針對(duì)性的對(duì)具體時(shí)序數(shù)據(jù)庫(kù)產(chǎn)品進(jìn)行細(xì)致分享,我們接下來(lái)把時(shí)間交給 后續(xù)的老師。
作者介紹
孫金城,51CTO社區(qū)編輯,Apache Flink PMC 成員,Apache Beam Committer,Apache IoTDB PMC 成員,ALC Beijing 成員,Apache ShenYu 導(dǎo)師,Apache 軟件基金會(huì)成員。關(guān)注技術(shù)領(lǐng)域流計(jì)算和時(shí)序數(shù)據(jù)存儲(chǔ)。




















