從源碼解密Spark內存管理
內存不過是計算機分級存儲系統中的靠近cpu的一個存儲介質。
- spark運行起來內存里都存的啥?
- 如何管理里面所存的東西?
- spark用java和scala這樣的jvm語言寫的,沒有像c語言那樣顯式申請釋放內存,如何進行內存的管理的?
- 我們應該如何設置spark關于內存的參數?
我們一起來解決這些問題
一、內存模型
遠古大神曾告訴我們這個神秘公式:程序=算法+數據。
1.1 什么是內存模型
內存模型就是告訴我們怎么劃分內存、怎么合理利用我們的內存。
首先我們要存什么,根據大神的公式,我們這樣來分析:
- 數據:就是我們代碼操作的數據,比如人的數據(年齡、職位等)或者輸入的某個值。這些可在運行時將要計算的部分數據加載到內存。
- 算法:就是操作數據的邏輯,表現形式就是代碼或者編譯后的指令。當然它要運行起來,會依賴一部分內存,來儲存程序計數器(代碼執行到那一句了)、函數調用棧等運行時需要的數據。總而言之就是執行數據操作邏輯所必要的內存。
這下我們就可以把我們需要儲存的東西分為數據區和執行區。
二、spark內存模型
2.1 spark為啥快
我們都知道spark之所以比mapreduce計算的快,是因為他是基于內存的,不用每次計算完都寫磁盤,再讀取出來進行下一次計算,spark直接把內存作為數據的臨時儲存介質。所以mapreduce就沒有強調內存管理,而spark需要管理內存。
2.2 spark管理的內存
系統區:spark運行自身的代碼需要一定的空間。
用戶區:我們自己寫的一些udf之類的代碼也需要一定的空間來運行。
存儲區:spark的任務就是操作數據,spark為了快可能把數據存內存,而這些數據也需要占用空間。
執行區:spark操作數據的單元是partition,spark在執行一些shuffle、join、sort、aggregation之類的操作,需要把partition加載到內存進行運算,這也會運用到部分內存。
2.3 spark內存模型
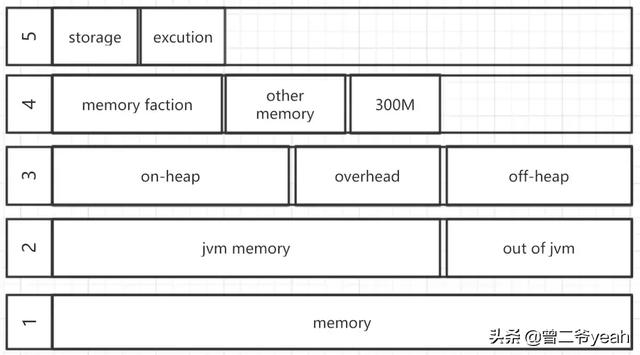
spark內存
上圖就是spark內存劃分的圖了
我們從下到上一層一層的解釋:
- 第1層:整個excutor所用到的內存
- 第2層:分為jvm中的內存和jvm外的內存,這里的jvm內存在yarn的時候就是指申請的container的內存
- 第3層:對于spark來內存分為jvm堆內的和memoryoverhead、off-heap
- jvm堆內的下一層再說
- memoryOverhead 對應的參數就是spark.yarn.executor.memoryOverhead 這塊內存是用于虛擬機的開銷、內部的字符串、還有一些本地開銷(比如python需要用到的內存)等。其實就是額外的內存,spark并不會對這塊內存進行管理。
- off-heap 這里特指的spark.memory.offHeap.size這個參數指定的內存(廣義上是指所有堆外的)。這部分內存的申請和釋放是直接進行的不通過jvm管控所以沒有GC,被spark分為storage和excution兩部分和第5層講的一同被spark統一進行管理。
- 第4層:jvm堆內的內存分為三個部分
- reservedMemory 預留內存300M,用于保障spark正常運行
- other memory 用于spark內部的一些元數據、用戶的數據結構、防止出現對內存估計不足導致oom時的內存緩沖、占用空間比較大的記錄做緩沖
- memory faction spark主要控制的內存,由參數spark.memory.fraction控制。
- 第5層:分成storage和execution 由參數spark.memory.storageFraction控制它兩的大小,但是
- execution 用于spark的計算:shuffle、sort、aggregation等這些計算時會用到的內存,如果計算是內存不足會向storage部分借,如果還是不夠就會spill到磁盤。
- storage 主要用于rdd的緩存,如果execution來借內存,可能會犧牲自己丟棄緩存來借給execution,storage也可以向execution借內存,但execution不會犧牲自己。
三、源碼層面
3.1 整體架構
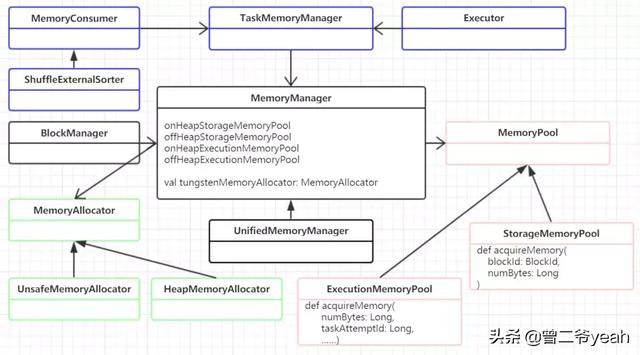
內存管理
- 內存申請和釋放(綠色):
- 看上圖綠色那塊,就是內存的申請和釋放模塊。MemoryAllocator接口負責內存申請,有兩個子類實現分別負責堆內內存和off-heap內存。
- 內存池(粉色):
- MemoryPool內存池有兩個子類分別管理著執行內存和儲存內存。可以看到兩種內存池的申請方法的參數有很明顯的區別,執行內存主要是面向task的,而儲存內存主要是面向block的也就是用于rdd緩存呀啥的。
- 統一內存管理:
- MemoryManager負責記錄內存的消耗,管理這4個內存池,子類UnifiedMemoryManager負責把這執行內存和儲存內存統一起來管理,實現相互借用之類的功能。
- MemoryManager的使用場景
- 一個是BlockManager用于管理儲存,還有一部分是運行Task是的內存使用,主要有executor的使用,shuffle時spill呀外部排序呀,這樣的場景。
3.2 如何實現內存申請釋放。
spark是用scala和java實現的,印象中沒有管理內存申請釋放的api,spark是如何利用這些jvm語言管理內存的呢。
我們來看看源碼片段
- //HeapMemoryAllocator.scala
- private final Map<Long, LinkedList<WeakReference<long[]>>> bufferPoolsBySize = new HashMap<>();
- ……
- public MemoryBlock allocate(long size) throws OutOfMemoryError {
- …… 上面是些內存的判斷 ……
- long[] array = new long[numWords];
- //上面這就很關鍵了
- MemoryBlock memory = new MemoryBlock(array, Platform.LONG_ARRAY_OFFSET, size);
- if (MemoryAllocator.MEMORY_DEBUG_FILL_ENABLED) {
- memory.fill(MemoryAllocator.MEMORY_DEBUG_FILL_CLEAN_VALUE);
- }
- return memory;
- }
HeapMemoryAllocator可以看到上面的源碼片段,實際的內存申請是這個代碼:new long[numWords]; 就是new了個數組來占著內存,用MemoryBlock 包裝了一下。bufferPoolsBySize這個是為了防止內存頻繁申請和釋放做的buffer。
接下來看看off-heap是怎么申請內存的。
- //UnsafeMemoryAllocator
- public MemoryBlock allocate(long size) throws OutOfMemoryError {
- long address = Platform.allocateMemory(size);
- MemoryBlock memory = new MemoryBlock(null, address, size);
- if (MemoryAllocator.MEMORY_DEBUG_FILL_ENABLED) {
- memory.fill(MemoryAllocator.MEMORY_DEBUG_FILL_CLEAN_VALUE);
- }
- return memory;
- }
offheap的就和C語言一樣的了可以直接使用api來申請。這部分內存就需要自己進行管理了,沒有jvm的控制,沒有內存回收機制。
當然這也不意味了你能無限制的使用內存,在yarn的情況下,yarn是監測子進程的內存占用來看你是否超了內存,如果超了直接kill掉。
四、總結
我們能回答開頭提出的幾個問題了嗎?還是又有了更多的問題呢。