













邊緣計算探索:處理器,算法與內存
什么是邊緣計算
最近,邊緣計算成為了人工智能和物聯網領域非常熱門的關鍵詞。
人們對于人工智能和物聯網的最初設想是,在云端有一個異常強大的數據中心,而物聯網各個節點負責采集數據交給云端,云端在根據數據分析并做決策后再把結果發還給終端。在這種模型中,云端負責智能計算,而終端節點負責數據采集以及決策執行。
然而,這樣的設想在實際實現中遇到了不少困難。***個困難來源于數據傳輸的開銷。物聯網節點通常都使用無線網絡與云端做數據傳輸,而如果物聯網節點把不加任何處理的原始數據一股腦全部傳到云端,會導致帶寬需求爆炸,網絡基礎架構沒法支撐如此高的帶寬。開銷的另一部分是無線傳輸的功耗,如果把數據不加任何處理就傳輸到云端,那么終端節點的無線傳輸模塊必須支持高速無線傳輸,這就意味著無線模塊需要很大的功耗,與物聯網節點低功耗的設想不符。第二個困難在于延遲。許多節點執行的任務對于延遲非常敏感,例如無人駕駛,例如安防,在這些應用中網絡傳輸帶來的延遲(幾十毫秒以上,有時候網絡信號不好會帶來數秒的延遲甚至掉線)無法被接受。
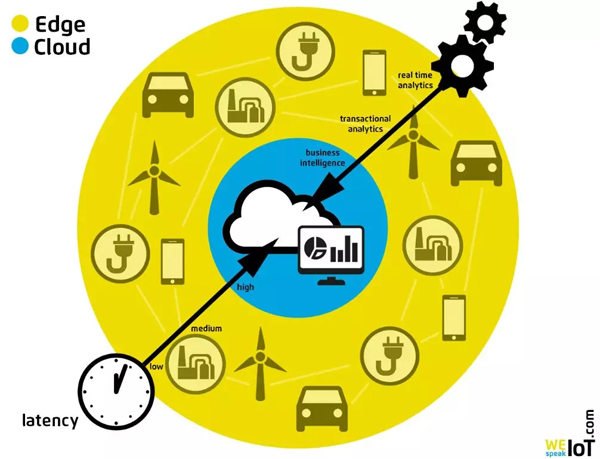
考慮到這些問題,邊緣計算就成為了解決方案。在邊緣計算中,終端節點不再是完全不負責計算,而是做一定量的計算和數據處理,之后把處理過的數據再傳遞到云端。這樣一來延遲和帶寬的問題可以解決,因為計算在本地,而且處理過的數據一定是從原始數據中進行過精煉的數據所以數據量會小很多。當然,具體要在邊緣做多少計算也取決于計算功耗和無線傳輸功耗的折衷——終端計算越多,計算功耗越大,無線傳輸功耗通常就可以更小,對于不同的系統存在不同的***值。
對于邊緣計算系統,處理器、算法和存儲器是整個系統中最關鍵的三個要素。下面我們仔細分析這幾個元素。
用于邊緣計算的處理器:要多通用?是否要上專用加速器?
常規物聯網終端節點的處理器是一塊簡單的MCU,以控制目的為主,運算能力相對較弱。如果要在終端節點加邊緣計算能力,有兩種做法,***是把這塊MCU做強,例如使用新的指令集增加對矢量計算的支持,使用多核做類似SIMD的架構等等;第二種是走異構計算的思路,MCU還是保持簡單的控制目的,計算部分則交給專門的加速器IP來完成,目前正火的AI芯片其實大部分做的就是這樣的一個專用人工智能算法加速器IP。顯然,前一種思路做出來通用性好,而第二種思路則是計算效率高。未來預期兩種思路會并行存在,平臺型的產品會使用***種通用化思路,而針對某種大規模應用做的定制化產品則會走專用加速器IP的思路。然而,IoT終端的專用加速器IP設計會和其他領域(如手機)的專用加速器設計有所不同,因為有內存的限制(見下面分析)。
算法與內存
眾所周知,目前最主流的深度神經網絡模型大小通常在幾MB甚至幾百MB,這就給在物聯網節點端的部署帶來了挑戰。物聯網節點端處于成本和體積的考量不能加DRAM,一般用FLASH(同時用于存儲操作系統等)作為系統存儲器。我們可以考慮用FLASH來存儲模型權重信息,但是緩存必須在處理器芯片上完成,因為FLASH的寫入速度比較慢。由于緩存大小一般都是在幾百KB到1MB數量級,這就限制了模型的大小,因此算法必須能把模型做到很小,這也是為什么最近“模型壓縮”這個話題會這么火的原因。
如果算法無法把模型做到很小,就需要考慮內存內計算。內存內計算(in-memory computing)是一種與傳統馮諾伊曼架構不同的計算方式。馮諾伊曼架構的做法是把處理器計算單元和存儲器分開,需要時處理器從存儲器讀數據,之后在處理器處理完了數據之后再寫回存儲器。因此傳統使用馮諾伊曼架構的專用加速器大部分也需要配合DRAM內存使用,使得這樣的方案在沒法加DRAM的物聯網節點端難以部署。內存內計算則是直接在內存內做計算而無需把數據取到處理器里,這樣就節省了內存存取的額外開銷。一塊內存內計算的加速器的主體就是一塊大SRAM或者Flash,然后在內存上再加一些計算電路,從而直接在內存內做計算,理想情況下就能在沒有DRAM的情況下跑起來相關算法。
當然內存內計算也有自己的挑戰。出了編程模型需要仔細考慮之外,內存內計算目前的實現方案本質上都是做模擬計算,因此計算精度有限,FP32之類的高精度肯定是不可能了。這就需要人工智能模型和算法做相應配合,對于低精度計算(即量化計算,quantized computation)有很好的支持,避免在低精度計算下損失太多正確率。目前已經有不少binary neural network(BNN)出現,即計算的時候只有1位精度0或者1,并且仍然能保持合理的分類準確率。
另一方面,目前IoT節點終端內存不夠的問題除了可以用模型壓縮來解決之外,另一條路就是使用新存儲器解決方案來實現高密度片上內存,或者加速片外非易失性存儲器的讀寫速度,并降低讀寫功耗。因此,邊緣計算也將會催生新內存器件,例如MRAM,ReRAM等等。
總結
邊緣計算是人工智能和物聯網結合的產物,是未來的重要趨勢。未來邊緣計算的關鍵技術,包括新處理器(強通用處理器或專用加速器),內存內計算,網絡模型壓縮,以及新存儲器。喜歡新技術的朋友們不妨多多關注這些領域,預計會出現不少有趣的公司和技術。

















