計算存儲分離之“數據存儲高可用性設計”
一、背景
面對著業務的發展,不管是在線,近線還是離線系統,其所需要的存儲規模以及存儲成本,成倍上漲。如果還是采取傳統的分散式存儲管理方式,除了高昂的管理分散式存儲的成本,還會增加存儲成本。
因此,我們極需一種既高效又省成本的數據存儲以及存儲管理方式。自然地,我們把目光聚焦到了分布式存儲系統上。
從目前行業發展趨勢來看,各大互聯網公司都設計或者維護了自己的分布式存儲系統。如Google的GFS(Colossus 為GFS第二代分布式存儲系統),Facebook和LinkedIn的HDFS等。由此可見,分布式存儲也是大勢所趨。
同樣在阿里,我們今年對數據庫進行計算存儲分離,面臨的難度也非常大。因此,我們也對各種分布式存儲進行了許多研究,開源的如Ceph,還有阿里云的盤古等。
我們緊跟業界以及開源社區,并不斷吸收其優秀成果;同時也做了大量的研究,測試和驗證。根據集團業務的特性,我們進行了許多軟件層面,甚至軟硬件結合的優化,為集團業務的發展賦能。
分布式存儲系統所具備的優點就是為了克服傳統存儲方式的缺點。那么,它將會給我們帶來哪些收益呢?
二、分布式存儲的收益
分布式存儲系統所帶來的收益主要體現在以下幾個方面。總體上來講,主要是降低存儲成本,同時也提高了資源的分配效率,助力計算資源的彈性調度。
2.1 解除機型配比
一般性的,我們將服務器分為兩部分,計算資源和存儲資源。計算資源如CPU和內存,計算資源的特點就是無狀態,資源分配比較靈活。存儲資源有狀態,需要保證數據的一致性和持久性,資源分配比較固定,會涉及到數據的遷移。如果數據量太大,就會遇到遷移性能的問題。
傳統的存儲方式,是單臺服務器類型的,將計算資源與存儲資源(HHD和SSD等存儲設備)綁定在一起。因此一臺機器CPU,內存與存儲設備比值都是固定的。這帶來的一個問題,就是我們會比較頻繁的改變我們的機型,因每年我們的計算資源與存儲資源的配比都在變化,業務數據的增長非常快。這也在某種程度上提高了每年采購機器的成本。
引入分布式存儲系統后,解除了這兩者緊密耦合的現狀,使得降低存儲成本成為了可能。計算資源和存儲資源解耦后,各自可以按不同的策略進行過保,在一定程度上降低了成本。
2.2 解決存儲碎片
傳統分散式的存儲模型,必然會有存儲碎片問題的存在。因為每臺服務器都會為線上業務預留一定的存儲空間,以滿足將來業務數據增長的需要。但是采用預留空間的方式會有一個問題,就是我們無法準確地評估真實的實際空間需求,往往預留的會比較多,業務實際需求與預留空間這兩者的差距就是存儲空間浪費量。
這些服務器殘留了獨立的10G,20G的空間碎片,在一定程度上也并不能滿足業務實例申請的規格,但將這些碎片合并在一起就能滿足業務所需。
引入分布式存儲系統后,大大減少這種碎片,業務實際的數據存儲空間按需進行動態分配。我們引入數據增長趨勢分析,每天或者每周進行存儲在線動態擴容,以提高管理效率,降低存儲成本。
2.3 計算資源彈性
傳統資源配置下,我們的計算資源調度水平受限于單臺機器的存儲容量。在制定Docker容器化規格時,連同存儲容量一起考慮,其調度和資源分配算法異常復雜。當CPU,內存以及存儲容量這三者在某種程度上發生沖突時,往往會犧牲一定的存儲資本,來達成Docker實例規格的妥協。
將計算資源與存儲資源分離后,計算資源得到解脫。我們在安排機器的過保時,采用不同的策略,降低機器采購成本。
另外,計算資源是無狀態的,獨立之后,進行容器化,就可以方便的進行調度,提高效率。更重要的是,讓離在線混布成為一種可能或者讓其更高效。
2.4 解決差異化需求
某些新興業務,往往會呈現爆發式增長。自然而然,其數據量也會呈跳躍式的爆炸。此時對存儲的規格的需求就會比較大,因為業務短時間內往往來不及做架構優化,或者做數據分片來降低單機的數據存儲容量。這會給傳統的存儲模型帶來很大的挑戰,因為傳統的分散式的單臺服務器的存儲容量已經不能滿足需求。
分布式存儲系統破除了這種大存儲容量實例規格的天花板限制,業務不再關心底層存儲的實現,我們根據業務數據的增長趨勢分析,動態擴展存儲空間。
三、面臨的問題
盡管分布式存儲有上述的諸多優點,然而如何設計其高可用性,如何減少數據丟失的概率,是擺在我們面前必須要去克服的問題。那么我們又是如何來架構和設計的呢?
3.1 數據丟失
在分布式存儲系統中,為了防止單機故障而造成數據丟失,往往會引入多個數據副本,我們稱之為replica set。此replica set中數據的副本個數用R來表示。一般的,R等于3,就表示是這份數據的存儲份數是“3”,也就是我們通常所說的 3-way replication。
在隨機的模式下,有可能replica set的3份數據位于同一個rack中,那么當此rack掉電就會導致數據丟失,對線上業務造成影響。隨著集群規模的變大,如果有超過1%的數據節點遭遇斷電,并且斷電之后又有一部分機器重起失敗,或者進程異常導致數據文件損壞;那么其影響都將隨著集群規模的增長而變得異常嚴重,成為分布式存儲系統致命的問題。
當然,我們可能通過增加數據的副本數即“replica set size”,來降低數據丟失的概率。又或者提高底層IDC以及網絡的高可用性,減少斷網或者網絡故障發生的概率。但是這些方法都是繞開問題的本質來優化的,另外帶來的存儲成本的增長也是不能接受的。
早期,Facebook和LinkedIn在使用HDFS時,也同樣面臨這樣的問題,也做了這方面不少的驗證和測試。最終較為一個合理的方案就是通過合理安排replica set中數據存儲的位置來降低數據丟失的可能性。
3.2 數據散射度
為了能夠更好的理解數據副本存儲位置(data locality),我們引入數據散射度(scatter width)的概念。怎么來理解數據散射度?
假設一個集群,有N個節點,數據副本replica set size為R,那么數據散射度最差的情況就是從N個節點中任意取R個的組合數,也就是C(N,R)。我們假定N為“9”,R為“3”。
舉個例子:我們定義三個copy set(存放的都是不同的數據):{1,2,3},{4,5,6},{7,8,9}。任意一組copy set中存放的數據沒有重復,也就是說一份數據的三個副本分別放置在:{1,4,7}或者{2,5,8}或者{3,6,9}。那么這個時候,我們稱之為其數據散射度S為“3”,遠小于隨機組合的C(9,3)。
隨機組合時,任意3臺機器Down機都會存在數據丟失。而采用Copy Set方案后,只有當{1,4,7}或者{2,5,8}或者{3,6,9}其中的任意一個組合不可用時,才會影響高可用性,才會有數據丟失。
綜上可知,我們引入copy set的目標就是盡量的降低數據散射度“S”。
但是現實遠非這么簡單,當我們降低數據散射度后,其數據恢復速度變小,也就是說恢復時間變長。因此,我們必須在數據散射度“S”和恢復速度中找到一個平衡。
四、高可用性設計
一般地,業務統一用N個“9”來表示一個分布式系統的高可用性。一般業界做得好的,都已經能達到9個“9”。那么,我們的分布存儲系統又如何來設計,又能達到多個“9”呢?
4.1 OSD Domain
默認的OSD節點bucket是基于Host的,也就是說取決于一臺機器上存儲設備的數量。如下圖所示,一臺Host上面有4個OSD(device,如HDD或SSD等)。所以在集群存儲數據時,會尋找數據存放位置。
首先會將Primary放入到Host0的四個節點中,即{0,1,2,3}。同一組中的OSD會根據權重進行平衡。另外兩個副本按同樣的權重計算方法放到Host1和Host2中。從總上來看,就是三份數據分別放到Host0,Host1和Host2上面,在每一個Host中數據均勻的分布在4個OSD節點上。

當Host0中的OSD 0節點(存儲設備)掛掉,會做兩個事情:
- 會從Host0中剩余的OSD節點中,找可替代節點,將新增數據寫到剩余的節點中
- 當OSD 0恢復時,會將Host0其它OSD節點中剛才新增的數據copy回OSD 0,這個叫recovery的backfill過程
我們的目的,就是減少recovery時backfill的時間。所以如果一個Host下面的OSD節點越多,就會有越多的節點參加backfill,恢復速度就會越快。一般單臺機器的存儲設備掛載都是有限制的,我們很快就會遇到瓶頸。另外,目前的SSD 128K的寫入速度也在400-500M/s之間,跟我們的目標相比,并不算太高。
基于此,我們計了OSD domain,它擺脫了單臺機器的設備掛載量限制。如下所示,其中黃色虛線框中的OSD都在同一個OSD domain中。一個OSD domain中包含4臺機器,每臺機器有4個OSD節點(存儲設備)。此時,當一個OSD掛掉后,會有15個OSD參加新增數據的平衡和recovery的backfill,大大縮短了恢復時間。
在這些OSD Domain中,故障是隔離的,所以一般也稱OSD Domain為故障隔離域。

4.2 Replica Domain
在第三個章節中,我們提到了數據散射度問題,數據散射度越大,可用性越差,丟失數據的可能性越高。因此,我們怎么來解決這個問題呢?
這需要結合copy set的原理來做合理架構與設計,再基于上面OSD domain的設計,我們再新增replica domain,將三個不同rack中的OSD domain組成三個copy set,用于存放replica set的三個數據副本。
具體架構圖如下,這樣部署后,copy set做到了一個非常低的水平。

另外,為了節省IDC機架位資源,我們在一個集群下分為兩個replica domain,每個replica domain下面又有3個OSD domain:

4.3 泊松分布
到這里,我們的副本存放拓撲結構設計差不多完成了,那么接下來,我們來計算下這種部署能做到多個“9”呢?
在分布式存儲集群中,X個磁盤發生故障的事件是獨立的,其概率是符合泊松分布的。
拿磁盤來講,其MTTF為1million,因此AFR為“1-(24*365/1million)= 0.98832”,約為“0.99”。泊松分布中,兩個重要的變量因還素X和Mean我們都確定了。
對于分布式存儲池來講,X就是replica set size “R”,Mean就是“0.99”。
我們存儲集群的高可用性可以簡單的按以下函數來量化:P = f(N, R, S, AFR),其中:
- P: 丟失所有副本的概率
- R: 副本數,也就是replica set size
- S: 單組OSD Domain中OSD的個數
- N: 整個集群中OSD的總數
- AFR: 磁盤的年平均故障率
進行演化后,我們得到可用性公式:P = Pr * M / C(N,R),其中:
Pr:為R個數據副本同時失效的概率,相當于是Primary在做recovery恢復時,其它R-1個副本也Fault掉了。
M:為可能的Copy set數目
R:為replicat set size,即副本數
N:為集群OSD總數
C(N,R):為N個OSD節點中,取R個副本的組合數
從上面的高可用性公式可以看出,一般在給定集群OSD節點數和副本數“R”后,C(N,R)也就確定了。那么,為了提高可用性,我們必須想辦法降低Pr和M的值。
存儲節點的拓撲結構,基于以上分析,做的最終架構優化:
- 為了降低Pr,我們引入了OSD domain,默認基于Host單機,無法發揮網絡“多打一”的優勢,我們引入OSD domain,提高單個OSD恢復的速度。將原來三個OSD節點擴大到16個,恢復速度提高了5倍以上。
- 為了降低M,也就是copy set的size,我們引入了replica domain。同一個PG中所有的OSD必須在同一個replica domain中,降低了數據丟失的概率了,提高了高可用性。
以下經我們架構設計后,再根據泊松分布計算出來的高可用性:
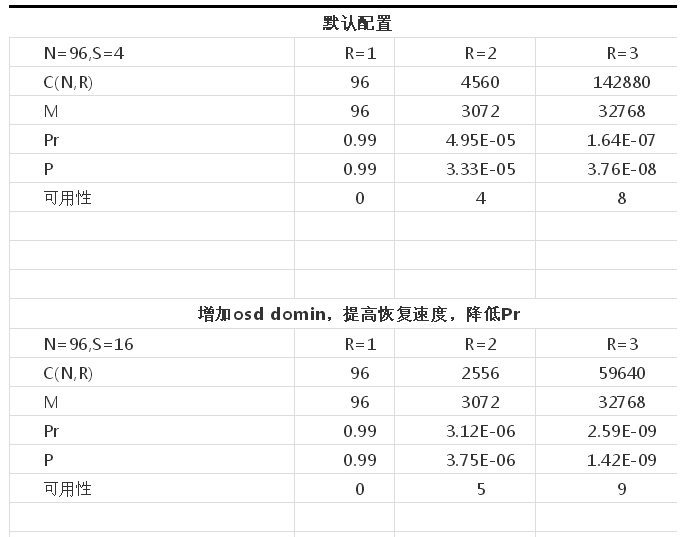

根據這個架構設計,在同一個IDC內,我們基本上能做到接近于10個“9”的高可用性。比之于默認的算法,高可用性整整提高了將近100倍。
4.4 網絡拓撲結構
根據上面的分布式拓撲結構設計,再結合現有的網絡拓撲結構,我們的架構設計最終方案為:
一個存儲集群24臺機器,兩個replica domain,每個replica domain中有三個OSD domain,每個OSD domain中4臺機器,因此計算公式如下:
2(一般為兩個,由網絡交換機下掛的機器數決定)* 3(replica set,replica domain) * 4(scatter width,OSD domain)= 24
原則性的,replica domain的機器位于三個不同的rack時,這三個rack不能在同一個port中。一個交換設備下掛16臺機器,兩個OSD domain,這兩個OSD domain屬于不同的replica domain。
在實際生產中,為了高可用性,我們建議至少部署4個rack集群。另外,在集群擴容時,建議按一組replica domain的規模來擴容。
每一組OSD domain中,存儲機器數目也可以是4臺或者8臺不等,可以按單臺的機器容量來進行動態規劃,但是計算公式可大致參考以上的部署策略。
五、總結與展望
目前,軟硬件結合的分布式存儲IO stack也在不斷的優化(SPDK,NVMe 等)中,網絡基礎架構RDMA的網絡設計也在驗證和POC中。這些新的思路與整個業界的生態體系發展趨勢一致。
在可預見的將來,存儲技術上將會有不斷的融合與補益,這也有利于存儲技術的更新換代,也更好的支撐業務的快速發展;最終具備,技術擴展業務邊界以及業務向技術拿紅利的能力。
計算存儲分離更多細節,將在以后的篇章中講述。