一、優化分類
二、測試數據樣例
參考mysql官方的sakina數據庫。
三、使用mysql慢查詢日志對有效率問題的sql進行監控

***個,開啟慢查詢日志。第二個,慢查詢日志存儲位置。第三個,沒有使用索引的也會記錄到慢查詢日志中。第四個,超過1秒之后的查詢記錄到慢查詢日志中(通常設置100ms)。
3.1、分析慢查詢日志文件
3.1.1 tail命令
tail -50 /home/mysql/sql_log/mysql_slow.log,輸入文件中的尾部內容,即末尾50行數據.
我們抽出其中一條,查看,如下圖所示。


query_time,查詢耗時(單位秒);lock_time,鎖表時間。rows_sent,發送請求的行數;rows_examined,查詢數據導致掃描表用到的行數。
3.1.2 官方mysqldumpslow工具
mysqldumpslow ,默認隨mysql安裝。
mysqldumpslow -h,可查詢工具支持的命令。
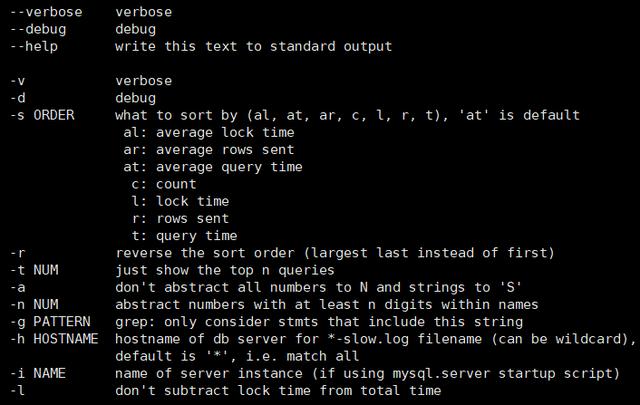
mysqldumpslow -s r -t 10 /var/lib/mysql/localhost-slow.log | more ,返回結果如下圖所示。
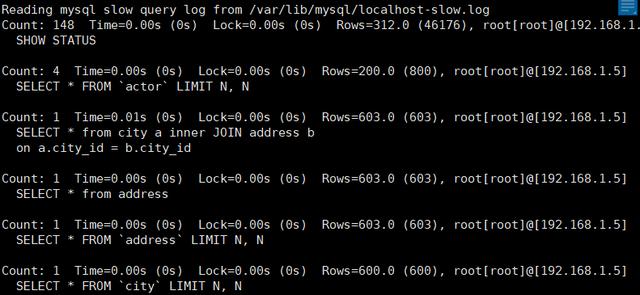
3.1.3 pt-query-digest工具
比mysqldumpslow反饋的信息多。

pg-query-digest --help 查看幫助,查看使用命令。
pg-query-digest /var/lib/mysql/localhost-slow.log,查詢結果如下。
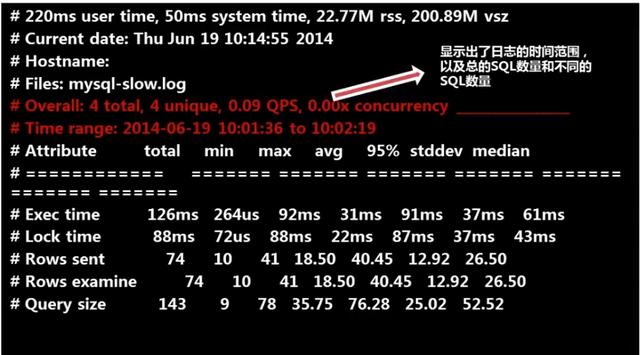
***部分

第二部分
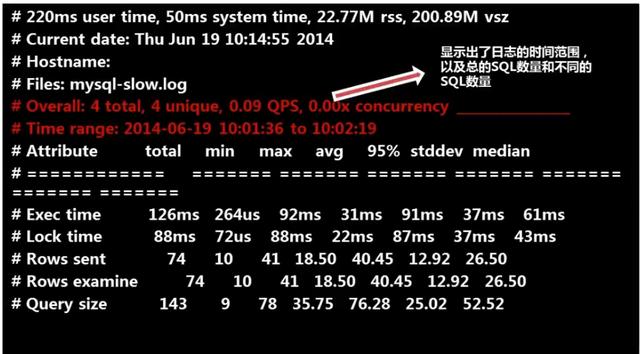
第三部分
四、如何通過慢查日志發現有問題的sql

五、通過explain查詢和分析sql的執行計劃

const常數查找,一般來說,針對主鍵和唯一索引;eq_reg,一般主鍵或是唯一索引范圍查找;ref,常見于連接查詢中;range,對于索引的范圍查找;
index,對于索引的掃描;all,表掃描。

六、count()和max()的優化
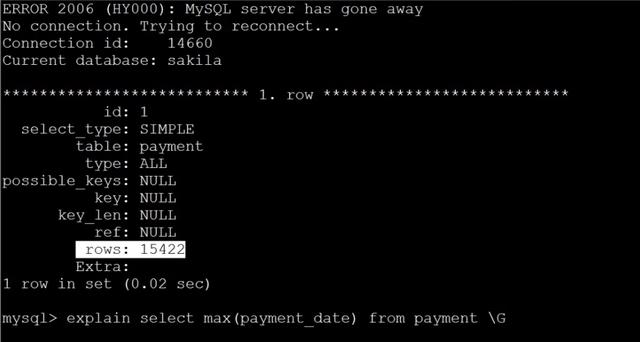
1、max()優化
在payment_date上建立索引
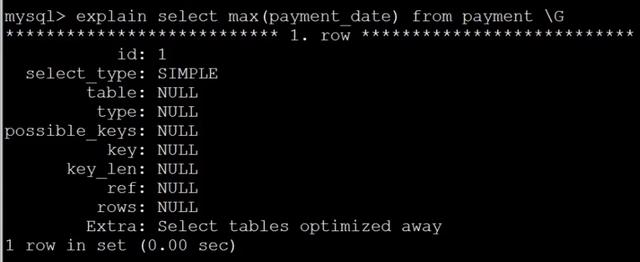
建索引后的查詢結果
可以看出,直接通過索引結構,就能查詢出***日期。覆蓋索引,是指完全可以通過索引獲得查詢結果。
2、count()優化
count(*)包含null值,count(id)不包含
錯誤寫法:

正確寫法:

七、子查詢的優化
一對多的子查詢,注意dinstinct

八、group by的優化

優化前
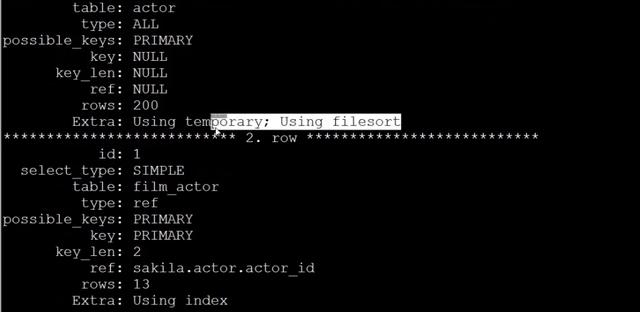
優化前

優化后
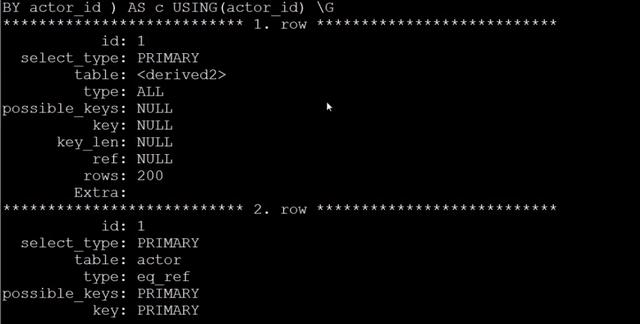
優化后
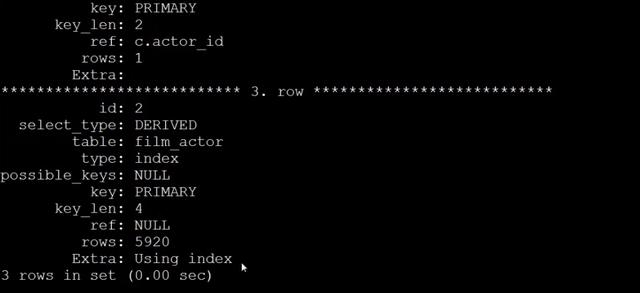
優化后,減少io,提高效率,節省服務器資源
靈活使用子查詢和連接查詢
九、limit查詢的優化


缺點:分頁limit越往后,掃描行數越多,io操作越大

缺點:id連續。主鍵連續增長,分頁查詢更快
十、如何選擇合適的列建立索引

如果是覆蓋索引,可直接從索引結構中獲取數據,這樣最快;索引字段越小,數據庫數據存儲以頁為單位,每次io所獲取的數據量就大。
通過select count(dinstinct customer_id)查看離散度。離散度大的列,可選擇性越高。
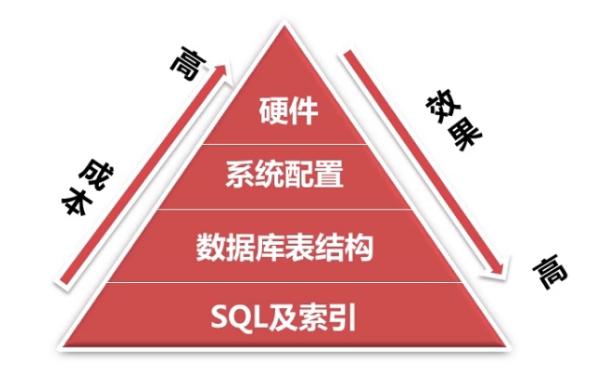
十一、索引優化SQL的方法
索引提高查詢,但是會影響inset,update,delete。



4、數據庫表結構優化
4.1 選擇合適的數據類型

時間類型上,時間戳和int占用字節相同;not null需要額外字段存儲,


bigint8個字節,varchar15個字節
4.2 數據庫的范式化優化
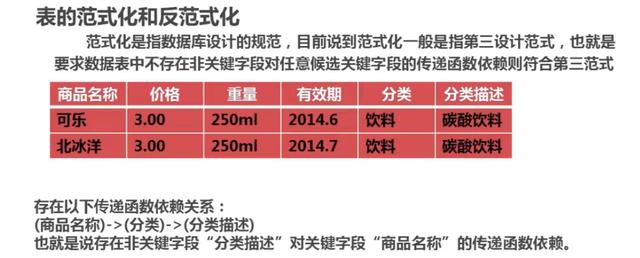

4.4表的垂直拆分

例如,將新聞表的內容拆分到單獨一個表
4.5 表的水平拆分


前臺用拆分后的表,后臺用匯總表