













DRDS內核技術前瞻 — 列式存儲綜述
本文將介紹若干個典型的列式存儲數據庫系統。作為完整的 OLAP 或 HTAP 數據庫系統,他們大多使用了自主設計的存儲方式,運行在多臺機器節點上,使用網絡進行通訊協作。
C-Store (2005) / Vertica
大多數 DBMS 都是為寫優化,而 C-Store 是***個為讀優化的 OLTP 數據庫系統,雖然從今天的視角看它應當算作 HTAP 。在 ad-hoc 的分析型查詢、ORM 的在線查詢等場景中,大多數操作都是查詢而非寫入,在這些場景中列式存儲能取得更好的性能。像主流的 DBMS 一樣,C-Store 支持標準的關系型模型。
關于 C-Store 特有的 projection 數據模型。這里做一下簡單的回顧:每個 projection 可以包含一個或多個列,完整的表視圖需要通過若干 projection JOIN 得到。Projection 水平拆分成若干 segments。
C-Store 的設計考慮到企業級應用的使用模式,在優化 AP 查詢的同時兼顧了大多數 DBMS 具有的 TP 查詢功能。在 ACID 事務方面同樣提供了完整的支持,支持快照(snapshot)讀事務和一般的 2PC 讀寫事務。
通常而言,互聯網應用對 DBMS 有較高的并發寫入需求,對一致性讀、分析型查詢的需求不那么強烈。而企業級應用(例如 CRM 系統)的并發寫入需求不大,但需要對一致性讀、分析型查詢等。
系統設計
C-Store 將其物理存儲也就是每個 projection 分成兩層,分別是為寫優化的 Writeable Store (WS) 和為讀優化的 Read-optimized Store (RS)。RS 即是基線數據,WS 上暫存了對 RS 數據的變更,二者在讀取時需要 merge 得到***的數據。在上一篇文章的 Apache ORC 格式種,我們也看到了類似的做法(基線數據疊加增量數據)。
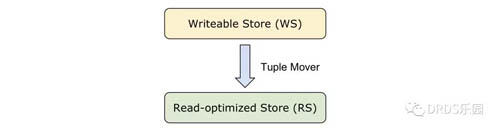
RS 是一個為讀優化的列式存儲。RS 中采用之前提到的 projection 數據模型,對不同的列采用了不同的編碼方式,根據它是否是 projection 的排序列、以及該列的取值個數,來決定采取何種編碼方式。
WS 用于暫存高性能的寫入操作,例如 INSERT、UPDATE 等。為了簡化系統的設計,WS 邏輯上仍然按照 projection 的列式模型存儲,但是物理上使用 B 樹以滿足快速的寫入要求。WS 基于 BerkeleyDB 構建。
對于某一列中的某個值 v,會有兩個映射關系存在:一是 (storage_key -> v),在 RS 中 storage_key 就是 segment 中的行號,但在 WS 中顯式的記錄下
來;二是 (sort_key -> storage_key),用于滿足主鍵查詢的需求。
值得一提的是,WS 是一個 MVCC 的存儲——它的每個數據都保存了對應的寫入事務編號,同一行可能有多個版本同時存在。而 RS 是沒有 MVCC 的,你可以將它看作過去某個時間點的快照。
Tuple Mover 周期性地將 WS 中的數據移動到 RS 中。與大多數 MVCC 系統一樣,C-Store 中的更新是通過一個刪除加一個插入實現的,Tuple Mover 的主要工作是根據 WS 的數據更新 RS:刪掉被刪除的行、添加新的行。
事務支持
C-Store 認為大多數事務是只讀事務,因此采用了 Snapshot Isolation。C-Store 維護兩個全局的時間戳:低水位(Low Water Mark, LWM)和高水位(High Water Mark, HWM),允許用戶查詢介于二者之間的任意時間戳的 Snapshot。時間戳來自中心化的 Time Authority (TA)。
LWM 對應 RS 即基線數據的版本。Tuple Mover 會保證任何高于 LWM 的修改都不會被移動到 RS 中,因為一旦移動到 RS 也就失去了多版本。
HWM 由中心的 TA 維護,時間被分成固定長度的 epoch。當各個節點確認 epoch e 中開始的寫入事務完成時,就會發送一個 Complete(e) 的消息給 TA,當 TA 收集到所有節點的 Complete(e) 將 HWM 置為 e。換句話說,HWM 以前的事務一定是已經完成提交的。
對于讀寫事務,C-Store 采用了傳統的 2PC。
MonetDB (2012) / VectorWise
MonetDB 是一個面向 OLAP 的內存數據。區別于大多數 DBMS 使用的 Valcano 執行模式,MonetDB 使用一種獨特的 full materialization 的列式(向量)執行模型,也因此設計了對應的一系列算子以及查詢優化器。
BAT Algebra
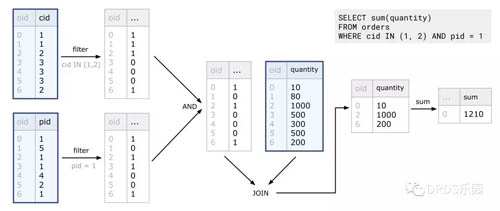
MonetDB 獨有的列式計算是通過 BAT(Binary Association Table)的運算組成的,BAT 之間通過算子產生新的 BAT,最終生成查詢結果。每個 BAT 可以簡單地理解為一列帶有編號的數據 <oid, value>,有些 BAT 來自用戶的邏輯表,其他則是運算的結果。每個算子被設計地很緊湊、高效,能充分利用 CPU 流水線的計算能力,這和 CPU 設計的 RISC 思想頗為相似,所以被稱為“數據庫查詢的 RISC 方案”。
如上圖,對于用戶一條 SELECT 查詢,MonetDB 先將其分解為多次 BAT 的運算,執行計劃中的每一步的輸入和輸出都是 BAT。圖中藍框中為輸入的 BAT,其他則是執行產生的運算結果。
MonetDB 的設計決定了它的計算過程十分耗費內存。MonetDB 利用操作系統的 Memory Mapped File 進行內存管理,不使用的頁面可以被換出內存,為執行查詢騰出空間。但顯然這并不是一個徹底的解決方案。
VectorWise 使用類似的向量化執行模型,但它嘗試在 full materialization 和 Valcano 模型中間尋求一個平衡——它將整個列劃分成較小的 block,對 block 進行上述的 column algebra 計算。
Apache Kudu (2015)
Kudu 是 Cloudera 研發的處理實時數據的 OLAP 數據庫。上文提到的 Parquet / ORC 是開源界常用的處理靜態數據的方式,為什么說是靜態數據呢?因為這些緊湊的格式對數據修改很不友好,且隨機讀寫性能極差,通常只能用于后臺 OLAP。
所以我們看到,很多數據系統都采用動態、靜態兩套數據,例如:把在線業務數據放在 HBase 中,定期通過 ETL 程序產生Parquet 格式文件放到 HDFS 上,再對其進行統計、歸檔等。這種定期導入的方式不可避免地會帶來小時級的延遲,而且,眾所周知維護 ETL 代碼是一件費時費力的事情。
Kudu 試圖在 OLAP 與 OLTP 之間尋求一個平衡點——在保持同一份數據的情況下,既能提供在線業務實時寫入的能力,又能支持高效的 OLAP 查詢。
Kudu 采用我們熟悉的半關系型模型,允許用戶定義 schema,但是目前并不支持二級索引。
事務方面,Kudu 默認使用 Snapshot Isolation 一致性模型。此外,如果用戶需要一個更強的一致性保證(例如 read own's writes),Kudu 也允許用戶指定特定的時間戳,讀取這個時間戳的 snapshot。這項功能被集成在 Kudu 的 API 層面,用戶可以方便地獲得因果(causality)一致性保證。
系統設計
Kudu 采用了類似 HBase 的 master-slave 架構:中心節點被稱作 Kudu Master,數據節點被稱作 Tablet Server。一個表的數據被分割成多個 tablets,由它們對應的 Tablet Server 來提供數據讀寫服務。
與 HBase 相比,中心節點 Kudu Master 除了存放了 Tablet 的分布信息,還身兼了如下角色:
- Catalog 管理:同步各個庫、表的 schema 等元信息、負責協調完成建表等 DDL 操作
- 集群協調者:各個 Tablet Server 向其匯報自己的狀態、replica 變更等
Kudu 底層數據文件并沒有存儲在 HDFS 這樣的分布式文件系統上,而是基于 Raft 算法實現了一套副本同步機制,保障數據不丟失及高可用性。其中 Raft 算法用于同步數據修改操作的 log,這點和大多數 shared-nothing 架構分布式數據庫并無二致。對 Raft 算法有興趣的同學可以參考原論文。
作為列式 OLAP 數據庫,Kudu 的磁盤存儲是常見的列式方案,很多地方直接復用了 Parquet 的代碼。我們知道,緊湊的列式存儲難以實現高效的更新操作。Kudu 為了提供實時寫入功能,采用了類似 C-Store 中的方案——在不可變的基線數據上,疊加后續的更新數據。
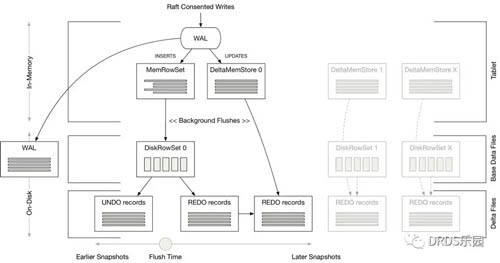
具體來說,Tablet 由 RowSet 組成,而 RowSet 既可以是內存中的 MemRowSet,也可以是存儲在磁盤上的 DiskRowSet。一個 RowSet 包含兩部分數據:基礎數據通常以 DiskRowSet 形式保存在磁盤上;而變更數據先以 MemRowSet 的形式暫存在內存中,后續再異步地刷寫到磁盤上。和 C-Store 類似,內存中的數據使用 B 樹存儲。
與 C-Store 不同的是,Delta 數據并不會立即和磁盤上的基線數據進行合并,而是由后臺的 compaction 線程異步完成。值得注意的是,為了保證 compaction 操作不影響過去的 snapshot read,被覆蓋的舊數據也會以 UNDO 記錄的形式保存在另外的文件中。
PowerDrill (2012)
PowerDrill 是 Google 研發用于快速處理 ad-hoc 查詢的 OLAP 數據庫,為前端的 Web 交互式分析軟件提供支持。PowerDrill 的數據放在內存中,為了盡可能節約空間,PowerDrill 引入一種全新的分區的存儲格式,在節省內存占用的同時提供了類似索引的功能,能過濾掉無關的分區、避免全表掃描。
同是 Google 家的產品,和 Dremel 相比,PowerDrill 有以下幾點差異:
- 定位不同:Dremel 用于查詢“大量的大數據集”(數據集的規模都大,數據集很多),PowerDrill 用于查詢“少量的大數據集”(數據集的規模大,但數據集不多)
- Dremel 用全表掃描(full scan)處理查詢,而 PowerDrill 對數據做了分區,并能根據查詢只掃描用到的分區。
- Dremel 使用類似 Protobuf 的嵌套數據模型;PowerDrill 使用關系模型
- Dremel 的數據直接放在分布式文件系統上,而 PowerDrill 需要一個 load 過程將數據載入內存
數據分區
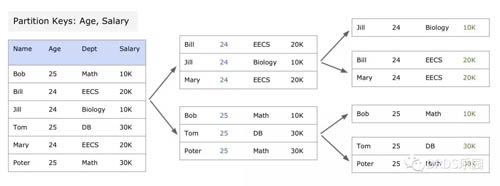
Ad-hoc 查詢常常包含 GROUP BY 子句,在這些 group key 上進行分區,能很好的過濾掉不需要的數據。PowerDrill 需要 DBA 根據自己對數據的理解,選出用于用于分區的一組屬性 Key1 Key2 Key3 ...(優先級依次遞減)。分區是一個遞歸的過程:一開始把整個數據集視為一個分區(Chunk),如果 Key1 能將數據分開就用 Key1,否則用 Key2、Key3—……直到分區大小小于一個閾值。
以下是一個分區的例子,***次使用 Age 分區、第二次使用 Salary 分區。
數據結構
PowerDrill 的數據組織以列為單位。對于每個列有一個全局字典表,列的每個分區有一個分區字典表:
- 全局字典表(global dictionary)存儲列中所有 distinct 的字符串,按字典順序排序。字典結構是雙向的,既能將 string 映射到 global-id,也能從 global-id 查 string。
- 分區字典表(chunk dictionary)存儲一個分區中 chunk-id 到 global-id 的雙向映射。相應地,數據列(elements)存儲 chunk-id 而不是 global-id。
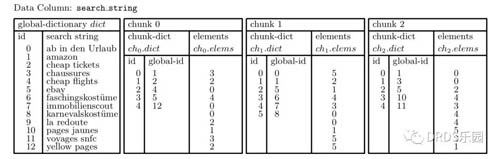
如果要將 chunk 中的一個 element 也就是 chunk-id 還原成數據,***步需要查分區字典表,得到 global-id;第二步查全局字典表,得到原本的字符串數據。以上圖舉例而言:
- Chunk 0 存儲的 chunk-id 數據 [3, 2, 0, ...]
- 根據分區字典表,查出 global-id:[5, 4, 1, ...]
- 根據全局字典表,查出 search string: ['ebay', 'cheap flights', 'amazon', ...]
這樣的兩層映射保證 chunk-id 盡可能的小,所以可以用更緊湊的編碼,比如用 8bit、16bit 整數存儲。這不僅能節省空間,也能加快掃描速度。
此外,相同的數據只會在全局字典表中存一份。而且全局字典表中的字符串數據已經被排序,相比不排序,排序后用 Snappy 等算法的壓縮比更高。
分區索引
上述的數據結構還有一個額外的好處:它能快速算出某個分區是否包含有用的數據,幫助執行器跳過無關的分區。以下面的 SQL 為例(數據參考上一張圖 Figure XXXX):

步驟如下:
- 在 search_string 列的全局字典表中查找 "[la redoute", "voyages sncf"],得到 global-id [9, 11]
- 在各個分區中查找 global-id [9, 11]: Chunk 0,Chunk 1 中都沒有找到,所以可以直接跳過;而 Chunk 2 中出現了 [11],對應 chunk-id 為 [4]
- 在 Chunk 2 中的 elements 掃描查出 chunk-id = 4 的元素數量一共有 3 次,作為 COUNT(*) 的結果返回。
總結
本文介紹了幾個知名的列式存儲系統。與上一篇文章不同,本文的系統大多重新設計了存儲層。與此同時,系統的復雜性也大大提升。
在構建自己的數據系統時,除了存儲方式本身,以下幾個地方是著重需要考慮清楚的地方,上述的幾個系統也給我們提供了很好的參考:
- 系統需要處理的查詢是怎樣的模式?C-Store 主要服務于企業級 HTAP 場景,Kudu 在提供 OLAP 查詢能力的同時保持了一定的實時寫入能力,PowerDrill 著重處理 ad-hoc 的分析型查詢。
- 系統如何保證數據的持久性和高可用性?C-Store 在 projection 上保留了一定的冗余,Kudu 用 Raft 協議保持各個副本的數據一致性及可用性,PowerDrill 則直接把數據放在分布式文件系統上,因為不需要對數據作修改。
- 系統提供怎樣的數據一致性保證?對于只讀的系統來說,這不是個問題。但是一旦支持寫入,數據的一致性、事務隔離性都需要精心的考慮和權衡。Kudu 和 C-Store 的 Snapshot Read 實現可作為參考。
















