技術經驗分享:漫談OceanBase 列式存儲
列式存儲主要的目的有兩個:
大部分OLAP查詢只需要讀取部分列而不是全部列數據,列式存儲可以避免讀取無用數據;
將同一列的數據在物理上存放在一起,能夠極大地提高數據壓縮率。
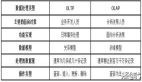
OLAP和OLTP
OLAP,也叫聯機分析處理(Online Analytical Processing)系統,有的時候也叫DSS決策支持系統,就是我們說的數據倉庫。在這樣的系統中,語句的執行量不是考核標準,因為一條語句的執行時間可能會非常長,讀取的數據也非常多。所以,在這樣的系統中,考核的標準往往是磁盤子系統的吞吐量(帶寬),如能達到多少MB/s的流量。
在OLAP系統中,常使用分區技術、并行技術。

分區技術在OLAP系統中的重要性主要體現在數據庫管理上,比如數據庫加載,可以通過分區交換的方式實現,備份可以通過備份分區表空間實現,刪除數據可以通過分區進行刪除,至于分區在性能上的影響,它可以使得一些大表的掃描變得很快(只掃描單個分區)。另外,如果分區結合并行的話,也可以使得整個表的掃描會變得很快。總之,分區主要的功能是管理上的方便性,它并不能絕對保證查詢性能的提高,有時候分區會帶來性能上的提高,有時候會降低。
在OLAP系統中,不需要使用綁定(BIND)變量,因為整個系統的執行量很小,分析時間對于執行時間來說,可以忽略,而且可避免出現錯誤的執行計劃。但是OLAP中可以大量使用位圖索引,物化視圖,對于大的事務,盡量尋求速度上的優化,沒有必要像OLTP要求快速提交,甚至要刻意減慢執行的速度。
綁定變量真正的用途是在OLTP系統中,這個系統通常有這樣的特點,用戶并發數很大,用戶的請求十分密集,并且這些請求的SQL 大多數是可以重復使用的。
OLTP,也叫聯機事務處理(Online Transaction Processing),表示事務性非常高的系統,一般都是高可用的在線系統,以小的事務以及小的查詢為主,評估其系統的時候,一般看其每秒執行的Transaction以及Execute SQL的數量。在這樣的系統中,單個數據庫每秒處理的Transaction往往超過幾百個,或者是幾千個,Select 語句的執行量每秒幾千甚至幾萬個。典型的OLTP系統有電子商務系統、銀行、證券等,如美國eBay的業務數據庫,就是很典型的OLTP數據庫。
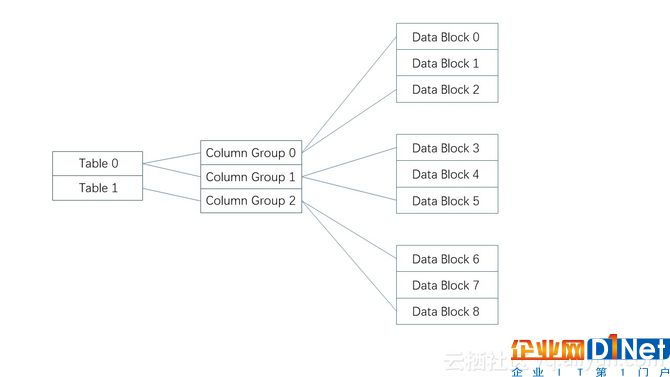
列組(Column Group)
OceanBase通過列組支持行列混合存儲,每個列組存儲多個經常一起訪問的列。
技術經驗分享:漫談OceanBase 列式存儲
如上圖所示,OceanBase SSTable首先按照列組存儲,每個列組內部再按行存儲。分為幾種情況:
·所有列屬于同一個列組。數據在SSTable中按行存儲,OLTP應用往往配置為這種方式。
·每列對應一個列組。數據在SSTable中按列存儲,這種方式在實際應用中比較少見。
·每個列組對應一行數據的部分列。數據在SSTable中按行列混合存儲,OLAP應用往往配置為這種方式。
OceanBase還允許一個列屬于多個列組,通過冗余存儲這些列,能夠提高訪問性能。例如,某表格總共包含5列,用戶經常一起訪問(1,3,5)或者(1,2,3,4)列。如果將(1,3,5)和(l,2,3,4)存儲到兩個列組中,那么,大部分訪問只需要讀取一個列組,避免了多個列組的合并操作。
列式存儲提高了數據壓縮比,然面,實踐過程中我們發現,由于OceanBase最初的幾個版本內存操作實現得不夠精細,例如數據結構設計不合理,數據在內存中膨脹很多倍,導致大查詢的性能瓶頸集中在CPU,列式存儲的優勢完全沒有發揮出來。這就告訴我們,列式存儲的前提是設計好內存數據結構,把CPU操作優化好,否則,后續的工作都是無用功。為了更好地支持OLAP應用,新版的OceanBase將重新設計列式存儲引擎