為什么 OLAP需要列式存儲
為什么這么設(shè)計(Why’s THE Design)是一系列關(guān)于計算機領(lǐng)域中程序設(shè)計決策的文章,我們在這個系列的每一篇文章中都會提出一個具體的問題并從不同的角度討論這種設(shè)計的優(yōu)缺點、對具體實現(xiàn)造成的影響。如果你有想要了解的問題,可以在文章下面留言。
ClickHouse 是最近比較熱門的用于在線分析處理的(OLAP)[^1]數(shù)據(jù)存儲,與我們常見的 MySQL、PostgreSQL 等傳統(tǒng)的關(guān)系型數(shù)據(jù)庫相比,ClickHouse、Hive 和 HBase 等用于在線分析處理(OLAP)場景的數(shù)據(jù)存儲往往都會使用列式存儲。
olap-oltp-databases
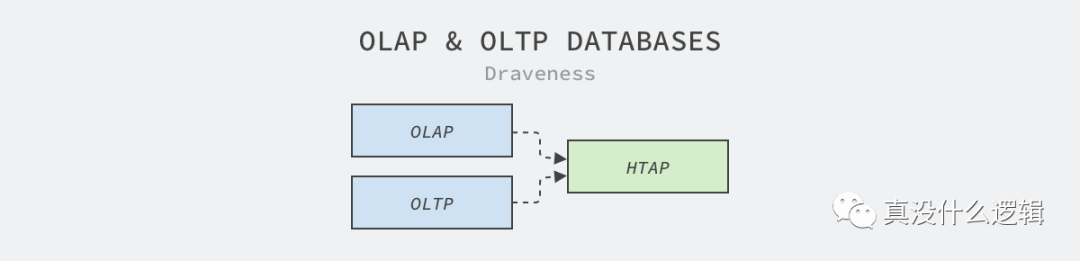
圖 1 - OLAP 和 OLTP
對數(shù)據(jù)庫稍有了解的讀者都知道,在線事務(wù)處理(Online Transaction Processing、OLTP)[^2]和在線分析處理(Online Analytical Processing、OLAP)是數(shù)據(jù)庫最常見的兩種場景,這兩種場景不是唯二的兩種,從中衍生出來的還有混合事務(wù)分析處理(Hybrid Transactional/Analytical Processing、HTAP)[^3]等概念。
在線事務(wù)處理是最常見的場景,在線服務(wù)需要為用戶實時提供服務(wù),提供服務(wù)的過程中可能要查詢或者創(chuàng)建一些記錄;而在線分析處理的場景需要批量處理用戶數(shù)據(jù),數(shù)據(jù)分析師會根據(jù)用戶產(chǎn)生的數(shù)據(jù)分析用戶行為和畫像、產(chǎn)出報表和模型。
標(biāo)題中提到的列式存儲與傳統(tǒng)關(guān)系型數(shù)據(jù)庫的行式存儲相對應(yīng),如下圖所示,其中行式存儲以數(shù)據(jù)行或者實體為邏輯單元管理數(shù)據(jù),數(shù)據(jù)行的存儲都是連續(xù)的,而列式存儲以數(shù)據(jù)列為邏輯單元管理數(shù)據(jù),相鄰的數(shù)據(jù)都是具有相同類型的數(shù)據(jù)。
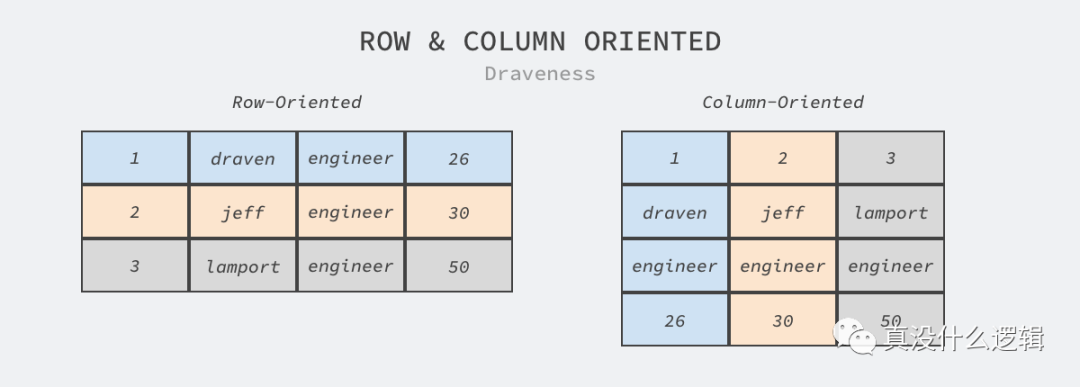
圖 2 - 行式存儲和列式存儲
既然我們已經(jīng)了解了標(biāo)題中提到的兩個概念:OLAP 和列式存儲,那么接下來將從以下兩個方面分析為什么列式存儲更適合 OLAP 的場景。
- 列式存儲可以滿足快速讀取特定列的需求,在線分析處理往往需要在上百列的寬表中讀取指定列分析;
- 列式存儲就近存儲同一列的數(shù)據(jù),使用壓縮算法可以得到更高的壓縮率,減少存儲占用的磁盤空間;
按需讀取
在線服務(wù)需要應(yīng)對用戶發(fā)起的增刪改查需求,雖然查詢的需求往往都是寫入請求的幾倍、甚至幾十倍,但是寫操作帶來的負(fù)責(zé)一致性問題成為了在線服務(wù)數(shù)據(jù)存儲不得不解決的問題,MySQL 和 PostgreSQL 等使用關(guān)系型數(shù)據(jù)庫提供的事務(wù)可以提供很好的方案。
正是因為 OLTP 場景中大多數(shù)的操作都是以記錄作為單位的,所以將經(jīng)常被同時使用的數(shù)據(jù)相鄰存儲也是很符合邏輯的,但是如果我們將 MySQL 等數(shù)據(jù)庫用于 OLAP 場景,最常見的查詢也可能需要遍歷整張表中的全部數(shù)據(jù)。
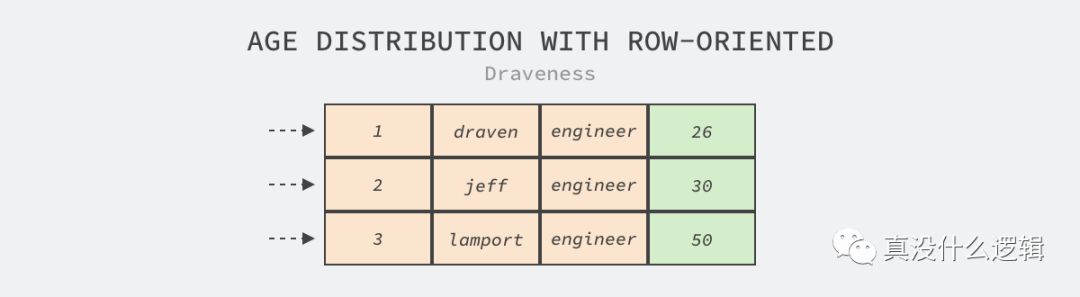
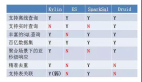
圖 3 - 在行式存儲獲取特定列
如上圖所示,當(dāng)我們僅需要獲取上表中年齡的分布時,也仍然需要讀取表中的全部數(shù)據(jù)并在內(nèi)存中丟棄不需要的數(shù)據(jù)行,其中黃色部分都是我們不關(guān)心的數(shù)據(jù),這浪費了大量的 I/O 和內(nèi)存資源。雖然我們可以使用輔助索引解決這些問題,但是對于 OLAP 中常見的幾十列甚至上百列的寬表就捉襟見肘了。
列式存儲會按列存儲數(shù)據(jù),這也意味著在讀取數(shù)據(jù)表中的特定列時,我們只需要找到相應(yīng)內(nèi)存空間的起始位置,然后讀取這片連續(xù)的內(nèi)存空間就可以獲得關(guān)心的全部數(shù)據(jù)。

圖 4 - 在列式存儲獲取特定列
哪怕在幾百列的大表中找到幾個特定列也不需要遍歷整張表,只需要找到列的起始位置就可以快速獲取相關(guān)的數(shù)據(jù),減少了 I/O 和內(nèi)存資源的浪費,這也是為什么面向列的存儲系統(tǒng)更適合在 OLAP 的場景中使用。
數(shù)據(jù)壓縮
因為列式存儲將同一列的數(shù)據(jù)存儲在一起,所以使用壓縮算法可以得到更高的壓縮率,減少存儲占用的磁盤空間。壓縮算法的基本原理其實很簡單,它使用基于特定規(guī)則的數(shù)據(jù)表示原數(shù)據(jù),如下所示的字符串中包含連續(xù)的相同字符,我們使用最符合直覺的壓縮算法就可以減少字符串的長度:
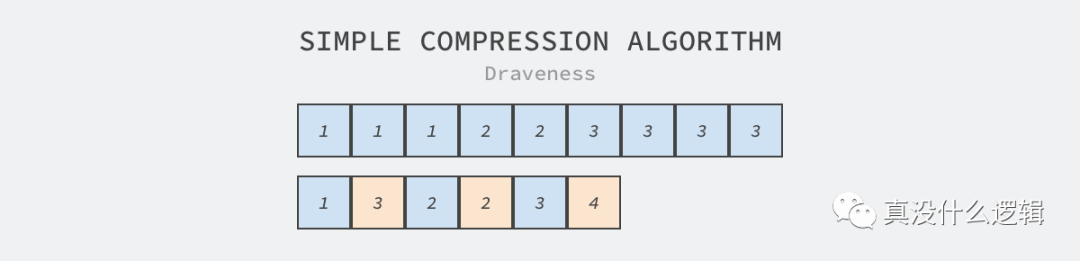
圖 5 - 簡單的壓縮算法
上圖中所有的黃色方塊表示前面字符串的重復(fù)次數(shù),這種簡單的壓縮策略可以在保證無損的情況下將字符串的長度壓縮 33%,然而壓縮率是由壓縮算法和數(shù)據(jù)的特性共同決定的。與面向行的數(shù)據(jù)存儲相比,面向列的數(shù)據(jù)存儲會將相同類型的數(shù)據(jù)就近存儲,這也給壓縮算法的提供了更多發(fā)揮的空間。
雖然壓縮算法實際上是一種使用 CPU 時間換取 I/O 時間和空間的策略,但是在多數(shù)情況下,這種生意都是穩(wěn)賺不賠的。壓縮算法通過減少數(shù)據(jù)的大小、減少磁盤的尋道時間提高 I/O 的性能、減少數(shù)據(jù)的傳輸時間并提高緩沖區(qū)的命中率,節(jié)省的 I/O 時間可以輕易補償它帶來的 CPU 額外開銷[^4]。
總結(jié)
在線分析處理的場景雖然一直都存在,不過隨著數(shù)字化浪潮的演進(jìn),我們也只是在最近才采集到了海量的用戶數(shù)據(jù)。因為過去的系統(tǒng)無法滿足今天海量數(shù)據(jù)的分析和處理需求,所以才出現(xiàn)了為細(xì)分場景設(shè)計的系統(tǒng),面向列的存儲系統(tǒng)也因為它的以下特性在 OLAP 的場景中煥發(fā)了光彩:
- 列式存儲可以滿足快速讀取特定列的需求,在線分析處理往往需要在上百列的寬表中讀取指定列分析,而傳統(tǒng)的行式存儲在分析數(shù)據(jù)時往往需要使用索引或者遍歷整張表,帶來了非常大的額外開銷;
- 列式存儲就近存儲同一列的數(shù)據(jù),使用壓縮算法可以得到更高的壓縮率,減少存儲占用的磁盤空間,雖然帶來了 CPU 時間的額外開銷,但是節(jié)省的 I/O 時間比帶來的額外開銷更多;
列式存儲在 OLAP 的場景中有著種種優(yōu)勢,不過它也不是數(shù)據(jù)存儲中的銀彈,仍然有很多缺點,不過在這里就不做討論了。到最后,我們還是來看一些比較開放的相關(guān)問題,有興趣的讀者可以仔細(xì)思考一下下面的問題:
- 列式存儲在 OLTP 的場景中有哪些優(yōu)點?
- HTAP 的場景會使用哪種方式存儲數(shù)據(jù)?
如果對文章中的內(nèi)容有疑問或者想要了解更多軟件工程上一些設(shè)計決策背后的原因,可以在博客下面留言,作者會及時回復(fù)本文相關(guān)的疑問并選擇其中合適的主題作為后續(xù)的內(nèi)容。
本文轉(zhuǎn)載自微信公眾號「真沒什么邏輯」,可以通過以下二維碼關(guān)注。轉(zhuǎn)載本文請聯(lián)系真沒什么邏輯公眾號。