我終于搞清楚了和String有關(guān)的那點(diǎn)事兒
String,是Java中除了基本數(shù)據(jù)類型以外,最為重要的一個(gè)類型了。很多人會(huì)認(rèn)為他比較簡(jiǎn)單。但是和String有關(guān)的面試題有很多,下面我隨便找兩道面試題,看看你能不能都答對(duì):
Q1:String s = new String("hollis");定義了幾個(gè)對(duì)象。
Q2:如何理解String的intern方法?
上面這兩個(gè)是面試題和String相關(guān)的比較常考的,很多人一般都知道答案。
A1:若常量池中已經(jīng)存在"hollis",則直接引用,也就是此時(shí)只會(huì)創(chuàng)建一個(gè)對(duì)象,如果常量池中不存在"hollis",則先創(chuàng)建后引用,也就是有兩個(gè)。
A2:當(dāng)一個(gè)String實(shí)例調(diào)用intern()方法時(shí),JVM會(huì)查找常量池中是否有相同Unicode的字符串常量,如果有,則返回其的引用,如果沒有,則在常量池中增加一個(gè)Unicode等于str的字符串并返回它的引用;
兩個(gè)答案看上去沒有任何問題,但是,仔細(xì)想想好像哪里不對(duì)呀。

按照上面的兩個(gè)面試題的回答,就是說new String會(huì)檢查常量池,如果有的話就直接引用,如果不存在就要在常量池創(chuàng)建一個(gè),那么還要intern干啥?難道以下代碼是沒有意義的嗎?
- String s = new String("Hollis").intern();
如果,每當(dāng)我們使用new創(chuàng)建字符串的時(shí)候,都會(huì)到字符串池檢查,然后返回。那么以下代碼也應(yīng)該輸出結(jié)果都是true?
- String s1 = "Hollis";
- String s2 = new String("Hollis");
- String s3 = new String("Hollis").intern();
- System.out.println(s1 == s2);
- System.out.println(s1 == s3);
但是,以上代碼輸出結(jié)果為(base jdk1.8.0_73):
- false
- true
不知道,聰明的讀者看完這段代碼之后,是不是有點(diǎn)被搞蒙了,到底是怎么回事兒?
別急,且聽我慢慢道來。
字面量和運(yùn)行時(shí)常量池
JVM為了提高性能和減少內(nèi)存開銷,在實(shí)例化字符串常量的時(shí)候進(jìn)行了一些優(yōu)化。為了減少在JVM中創(chuàng)建的字符串的數(shù)量,字符串類維護(hù)了一個(gè)字符串常量池。
在JVM運(yùn)行時(shí)區(qū)域的方法區(qū)中,有一塊區(qū)域是運(yùn)行時(shí)常量池,主要用來存儲(chǔ)編譯期生成的各種字面量和符號(hào)引用。
了解Class文件結(jié)構(gòu)或者做過Java代碼的反編譯的朋友可能都知道,在java代碼被javac編譯之后,文件結(jié)構(gòu)中是包含一部分Constant pool的。比如以下代碼:
- public static void main(String[] args) {
- String s = "Hollis";
- }
經(jīng)過編譯后,常量池內(nèi)容如下:
- Constant pool:
- #1 = Methodref #4.#20 // java/lang/Object."<init>":()V
- #2 = String #21 // Hollis
- #3 = Class #22 // StringDemo
- #4 = Class #23 // java/lang/Object
- ...
- #16 = Utf8 s
- ..
- #21 = Utf8 Hollis
- #22 = Utf8 StringDemo
- #23 = Utf8 java/lang/Object
上面的Class文件中的常量池中,比較重要的幾個(gè)內(nèi)容:
- #16 = Utf8 s
- #21 = Utf8 Hollis
- #22 = Utf8 StringDemo
上面幾個(gè)常量中,s就是前面提到的符號(hào)引用,而Hollis就是前面提到的字面量。而Class文件中的常量池部分的內(nèi)容,會(huì)在運(yùn)行期被運(yùn)行時(shí)常量池加載進(jìn)去。關(guān)于字面量,詳情參考Java SE Specifications
new String創(chuàng)建了幾個(gè)對(duì)象
下面,我們可以來分析下String s = new String("Hollis");創(chuàng)建對(duì)象情況了。
這段代碼中,我們可以知道的是,在編譯期,符號(hào)引用s和字面量Hollis會(huì)被加入到Class文件的常量池中,然后在類加載階段,這兩個(gè)常量會(huì)進(jìn)入常量池。
但是,這個(gè)“進(jìn)入”過程,并不會(huì)直接把所有類中定義的常量全部都加載進(jìn)來,而是會(huì)做個(gè)比較,如果需要加到字符串常量池中的字符串已經(jīng)存在,那么就不需要再把字符串字面量加載進(jìn)來了。
所以,當(dāng)我們說<若常量池中已經(jīng)存在"hollis",則直接引用,也就是此時(shí)只會(huì)創(chuàng)建一個(gè)對(duì)象>說的就是這個(gè)字符串字面量在字符串池中被創(chuàng)建的過程。
說完了編譯期的事兒了,該到運(yùn)行期了,在運(yùn)行期,new String("Hollis");執(zhí)行到的時(shí)候,是要在Java堆中創(chuàng)建一個(gè)字符串對(duì)象的,而這個(gè)對(duì)象所對(duì)應(yīng)的字符串字面量是保存在字符串常量池中的。但是,String s = new String("Hollis");,對(duì)象的符號(hào)引用s是保存在Java虛擬機(jī)棧上的,他保存的是堆中剛剛創(chuàng)建出來的的字符串對(duì)象的引用。
所以,你也就知道以下代碼輸出結(jié)果為false的原因了。
- String s1 = new String("Hollis");
- String s2 = new String("Hollis");
- System.out.println(s1 == s2);
因?yàn)椋?=比較的是s1和s2在堆中創(chuàng)建的對(duì)象的地址,當(dāng)然不同了。但是如果使用equals,那么比較的就是字面量的內(nèi)容了,那就會(huì)得到true。
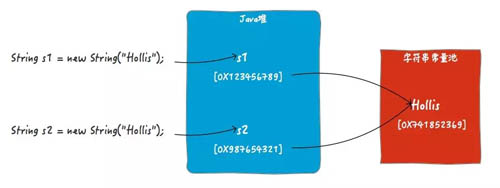
在不同版本的JDK中,Java堆和字符串常量池之間的關(guān)系也是不同的,這里為了方便表述,就畫成兩個(gè)獨(dú)立的物理區(qū)域了。具體情況請(qǐng)參考Java虛擬機(jī)規(guī)范。
上圖中s1和s2是兩個(gè)完全不同的對(duì)象,在堆中有自己的內(nèi)存空間,當(dāng)然不相等了。
所以,String s = new String("Hollis");創(chuàng)建幾個(gè)對(duì)象的答案你也就清楚了。
常量池中的“對(duì)象”是在編譯期就確定好了的,在類被加載的時(shí)候創(chuàng)建的,如果類加載時(shí),該字符串常量在常量池中已經(jīng)有了,那這一步就省略了。堆中的對(duì)象是在運(yùn)行期才確定的,在代碼執(zhí)行到new的時(shí)候創(chuàng)建的。
運(yùn)行時(shí)常量池的動(dòng)態(tài)擴(kuò)展
編譯期生成的各種字面量和符號(hào)引用是運(yùn)行時(shí)常量池中比較重要的一部分來源,但是并不是全部。那么還有一種情況,可以在運(yùn)行期像運(yùn)行時(shí)常量池中增加常量。那就是String的intern方法。
當(dāng)一個(gè)String實(shí)例調(diào)用intern()方法時(shí),JVM會(huì)查找常量池中是否有相同Unicode的字符串常量,如果有,則返回其的引用,如果沒有,則在常量池中增加一個(gè)Unicode等于str的字符串并返回它的引用;
intern()有兩個(gè)作用,***個(gè)是將字符串字面量放入常量池(如果池沒有的話),第二個(gè)是返回這個(gè)常量的引用。
我們?cè)賮砜聪麻_頭的那個(gè)讓人產(chǎn)生疑惑的例子:
- String s1 = "Hollis";
- String s2 = new String("Hollis");
- String s3 = new String("Hollis").intern();
- System.out.println(s1 == s2);
- System.out.println(s1 == s3);
你可以簡(jiǎn)單的理解為String s1 = "Hollis";和String s3 = new String("Hollis").intern();做的事情是一樣的(但實(shí)際有些區(qū)別,這里暫不展開)。都是定義一個(gè)字符串對(duì)象,然后將其字符串字面量保存在常量池中,并把這個(gè)字面量的引用返回給定義好的對(duì)象引用。如下圖:
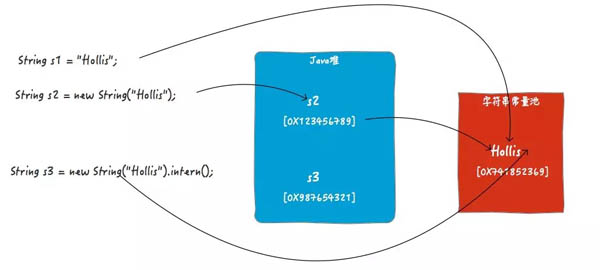
對(duì)于String s3 = new String("Hollis").intern();,在不調(diào)intern情況,s3指向的是JVM在堆中創(chuàng)建的那個(gè)對(duì)象的引用的(如圖中的s2)。但是當(dāng)執(zhí)行了intern方法時(shí),s3將指向字符串常量池中的那個(gè)字符串常量。
由于s1和s3都是字符串常量池中的字面量的引用,所以s1==s3。但是,s2的引用是堆中的對(duì)象,所以s2!=s1。
intern的正確用法
不知道,你有沒有發(fā)現(xiàn),在String s3 = new String("Hollis").intern();中,其實(shí)intern是多余的?
因?yàn)榫退悴挥胕ntern,Hollis作為一個(gè)字面量也會(huì)被加載到Class文件的常量池,進(jìn)而加入到運(yùn)行時(shí)常量池中,為啥還要多此一舉呢?到底什么場(chǎng)景下才會(huì)用到intern呢?
在解釋這個(gè)之前,我們先來看下以下代碼:
- String s1 = "Hollis";
- String s2 = "Chuang";
- String s3 = s1 + s2;
- String s4 = "Hollis" + "Chuang";
在經(jīng)過反編譯后,得到代碼如下:
- String s1 = "Hollis";
- String s2 = "Chuang";
- String s3 = (new StringBuilder()).append(s1).append(s2).toString();
- String s4 = "HollisChuang";
可以發(fā)現(xiàn),同樣是字符串拼接,s3和s4在經(jīng)過編譯器編譯后的實(shí)現(xiàn)方式并不一樣。s3被轉(zhuǎn)化成StringBuilder及append,而s4被直接拼接成新的字符串。
如果你感興趣,你還能發(fā)現(xiàn),String s4 = s1 + s2; 經(jīng)過編譯之后,常量池中是有兩個(gè)字符串常量的分別是 Hollis、Chuang(其實(shí)Hollis和Chuang是String s1 = "Hollis";和String s2 = "Chuang";定義出來的),拼接結(jié)果HollisChuang并不在常量池中。
如果代碼只有String s4 = "Hollis" + "Chuang";,那么常量池中將只有HollisChuang而沒有Hollis和 Chuang。
究其原因,是因?yàn)槌A砍匾4娴氖且汛_定的字面量值。也就是說,對(duì)于字符串的拼接,純字面量和字面量的拼接,會(huì)把拼接結(jié)果作為常量保存到字符串。
如果在字符串拼接中,有一個(gè)參數(shù)是非字面量,而是一個(gè)變量的話,整個(gè)拼接操作會(huì)被編譯成StringBuilder.append,這種情況編譯器是無法知道其確定值的。只有在運(yùn)行期才能確定。
那么,有了這個(gè)特性了,intern就有用武之地了。那就是很多時(shí)候,我們?cè)诔绦蛑杏玫降淖址侵挥性谶\(yùn)行期才能確定的,在編譯期是無法確定的,那么也就沒辦法在編譯期被加入到常量池中。
這時(shí)候,對(duì)于那種可能經(jīng)常使用的字符串,使用intern進(jìn)行定義,每次JVM運(yùn)行到這段代碼的時(shí)候,就會(huì)直接把常量池中該字面值的引用返回,這樣就可以減少大量字符串對(duì)象的創(chuàng)建了。
如一美團(tuán)點(diǎn)評(píng)團(tuán)隊(duì)的《深入解析String#intern》文中舉的一個(gè)例子:
- static final int MAX = 1000 * 10000;
- static final String[] arr = new String[MAX];
- public static void main(String[] args) throws Exception {
- Integer[] DB_DATA = new Integer[10];
- Random random = new Random(10 * 10000);
- for (int i = 0; i < DB_DATA.length; i++) {
- DB_DATA[i] = random.nextInt();
- }
- for (int i = 0; i < MAX; i++) {
- arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length])).intern();
- }
- }
在以上代碼中,我們明確的知道,會(huì)有很多重復(fù)的相同的字符串產(chǎn)生,但是這些字符串的值都是只有在運(yùn)行期才能確定的。所以,只能我們通過intern顯示的將其加入常量池,這樣可以減少很多字符串的重復(fù)創(chuàng)建。
總結(jié)
我們?cè)倩氐轿恼麻_頭那個(gè)疑惑:按照上面的兩個(gè)面試題的回答,就是說new String也會(huì)檢查常量池,如果有的話就直接引用,如果不存在就要在常量池創(chuàng)建一個(gè),那么還要intern干啥?難道以下代碼是沒有意義的嗎?
- String s = new String("Hollis").intern();
new String 所謂的“如果有的話就直接引用”,指的是Java堆中創(chuàng)建的String對(duì)象中包含的字符串字面量直接引用字符串池中的字面量對(duì)象。也就是說,還是要在堆里面創(chuàng)建對(duì)象的。
而intern中說的“如果有的話就直接返回其引用”,指的是會(huì)把字面量對(duì)象的引用直接返回給定義的對(duì)象。這個(gè)過程是不會(huì)在Java堆中再創(chuàng)建一個(gè)String對(duì)象的。
的確,以上代碼的寫法其實(shí)是使用intern是沒什么意義的。因?yàn)樽置媪縃ollis會(huì)作為編譯期常量被加載到運(yùn)行時(shí)常量池。
之所以能有以上的疑惑,其實(shí)是對(duì)字符串常量池、字面量等概念沒有真正理解導(dǎo)致的。有些問題其實(shí)就是這樣,單個(gè)問題,自己都知道答案,但是多個(gè)問題綜合到一起就蒙了。歸根結(jié)底是知識(shí)的理解還停留在點(diǎn)上,沒有串成面。
本文中的內(nèi)容歡迎大家討論,因?yàn)楣P者只是翻閱了部分JVM規(guī)范及Java語言規(guī)范,并未完全深入到虛擬機(jī)源碼級(jí)別。如有偏頗請(qǐng)不吝賜教。文中例子是為了方面講解特意舉的,如有不當(dāng)之處望諒解。
【本文是51CTO專欄作者Hollis的原創(chuàng)文章,作者微信公眾號(hào)Hollis(ID:hollischuang)】